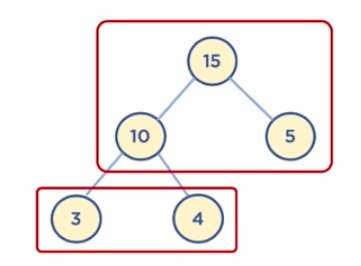
힙
2021. 8. 16. 11:24
🕶 Algorithm/자료구조
힙 (Heap) 이란? 힙: 데이터에서 최대값과 최소값을 빠르게 찾기 위해 고안된 완전 이진 트리(Complete Binary Tree) 완전 이진 트리: 노드를 삽입할 때 최하단 왼쪽 노드부터 차례대로 삽입하는 트리 힙을 사용하는 이유 배열에 데이터를 넣고, 최대값과 최소값을 찾으려면 O(n) 이 걸림 이에 반해, 힙에 데이터를 넣고, 최대값과 최소값을 찾으면, 𝑂(𝑙𝑜𝑔𝑛) 이 걸림 우선순위 큐와 같이 최대값 또는 최소값을 빠르게 찾아야 하는 자료구조 및 알고리즘 구현 등에 활용됨 힙 (Heap) 구조 힙은 최대값을 구하기 위한 구조 (최대 힙, Max Heap) 와, 최소값을 구하기 위한 구조 (최소 힙, Min Heap) 로 분류할 수 있음 가장 높은 값이 루트인 힙 = 최대 힙 가장 낮은 값이 ..
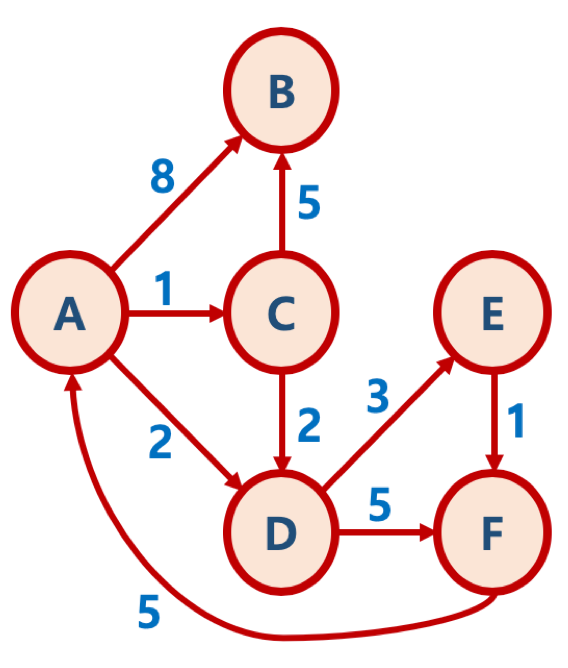
최단 경로 알고리즘
2021. 8. 9. 21:23
🕶 Algorithm/알고리즘
1. 최단 경로 문제란? 최단 경로 문제란 두 노드를 잇는 가장 짧은 경로를 찾는 문제임 가중치 그래프 (Weighted Graph) 에서 간선 (Edge)의 가중치 합이 최소가 되도록 하는 경로를 찾는 것이 목적 최단 경로 문제 종류 1. 단일 출발 및 단일 도착 (single-source and single-destination shortest path problem) 최단 경로 문제 그래프 내의 특정 노드 u 에서 출발, 또다른 특정 노드 v 에 도착하는 가장 짧은 경로를 찾는 문제 2. 단일 출발 (single-source shortest path problem) 최단 경로 문제 그래프 내의 특정 노드 u 와 그래프 내 다른 모든 노드 각각의 가장 짧은 경로를 찾는 문제 따지고 보면 굉장히 헷깔릴..
탐욕 알고리즘 (Greedy Algorithm)
2021. 8. 9. 21:10
🕶 Algorithm/알고리즘
1. 탐욕 알고리즘 (Greedy Algorithm)이란? Greedy algorithm 또는 탐욕 알고리즘 이라고 불리움 최적의 해에 가까운 값을 구하기 위해 사용됨 여러 경우 중 하나를 결정해야할 때마다, 매순간 최적이라고 생각되는 경우를 선택하는 방식으로 진행해서, 최종적인 값을 구하는 방식 2. 탐욕 알고리즘 예 문제1 : 동전 문제 지불해야 하는 값이 4720원 일 때 1원, 50원, 100원, 500원 동전으로 동전의 수가 가장 적게 지불하시오. 가장 큰 동전부터 최대한 지불해야 하는 값을 채우는 방식으로 구현 가능 탐욕 알고리즘으로 매순간 최적이라고 생각되는 경우를 선택하면 됨 coin_list = [500, 100, 50, 1] def min_coin_count(value, coin_lis..
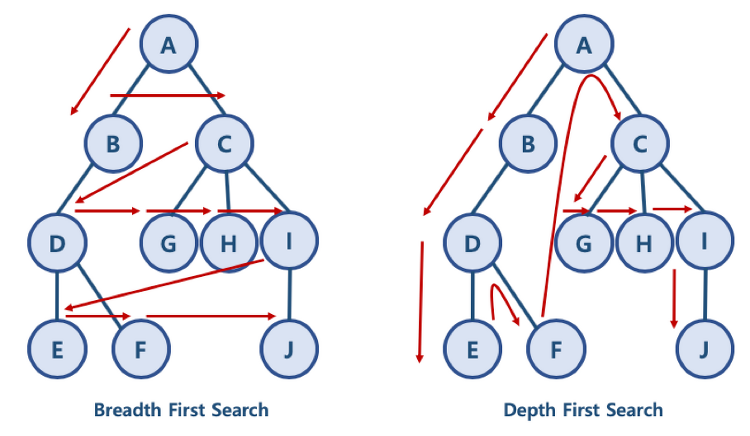
깊이 우선 탐색 (DFS, Depth First Search)
2021. 8. 8. 17:48
🕶 Algorithm/알고리즘
1. BFS 와 DFS 란? 대표적인 그래프 탐색 알고리즘 너비 우선 탐색 (Breadth First Search): 정점들과 같은 레벨에 있는 노드들 (형제 노드들)을 먼저 탐색하는 방식 깊이 우선 탐색 (Depth First Search): 정점의 자식들을 먼저 탐색하는 방식 1.1 BFS/DFS 방식 이해를 위한 예제 BFS 방식: A - B - C - D - G - H - I - E - F - J 한 단계씩 내려가면서, 해당 노드와 같은 레벨에 있는 노드들 (형제 노드들)을 먼저 순회함 DFS 방식: A - B - D - E - F - C - G - H - I - J 한 노드의 자식을 타고 끝까지 순회한 후, 다시 돌아와서 다른 형제들의 자식을 타고 내려가며 순화함 2. 파이썬으로 그래프를 표현하..
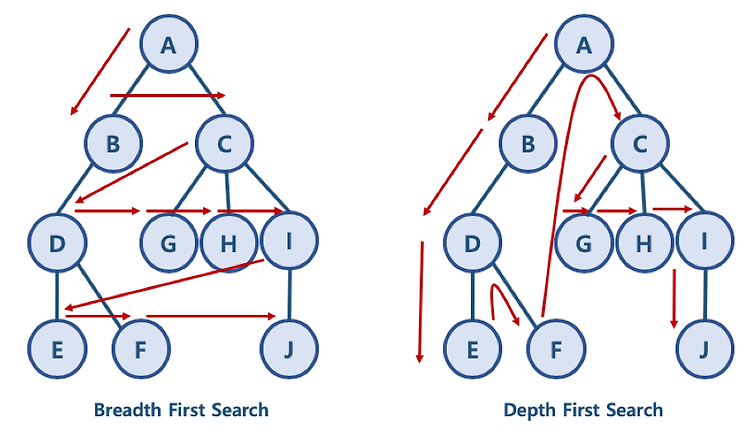
너비 우선 탐색 (BFS, Breadth First Search)
2021. 8. 8. 17:12
🕶 Algorithm/알고리즘
1. BFS 와 DFS 란? 대표적인 그래프 탐색 알고리즘 너비 우선 탐색 (Breadth First Search): 정점들과 같은 레벨에 있는 노드들 (형제 노드들)을 먼저 탐색하는 방식 깊이 우선 탐색 (Depth First Search): 정점의 자식들을 먼저 탐색하는 방식 1.1 BFS/DFS 방식 이해를 위한 예제 BFS 방식: A - B - C - D - G - H - I - E - F - J 한 단계씩 내려가면서, 해당 노드와 같은 레벨에 있는 노드들 (형제 노드들)을 먼저 순회함 DFS 방식: A - B - D - E - F - C - G - H - I - J 한 노드의 자식을 타고 끝까지 순회한 후, 다시 돌아와서 다른 형제들의 자식을 타고 내려가며 순화함 2. 파이썬으로 그래프를 표현하..
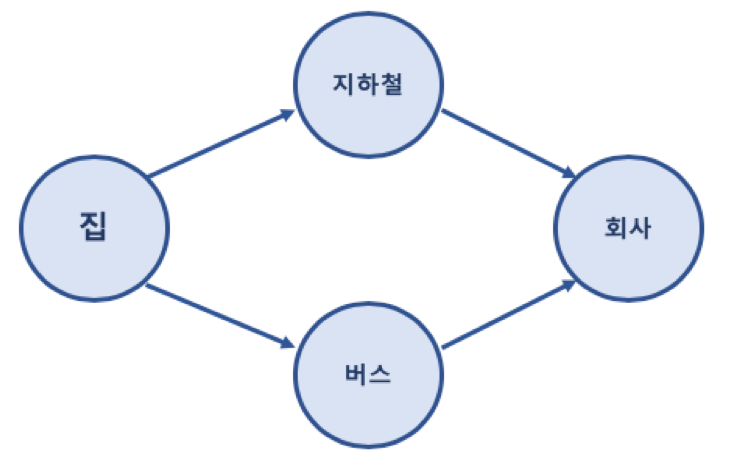
그래프
2021. 8. 8. 12:40
🕶 Algorithm/자료구조
그래프 (Graph) 란? 그래프는 실제 세계의 현상이나 사물을 정점(Vertex) 또는 노드(Node) 와 간선(Edge)로 표현하기 위해 사용 예제 집에서 회사로 가는 경로를 그래프로 표현한 예 그래프 (Graph) 관련 용어 노드(Node) : 위치를 말함, 정점(Vertex)라고도 함 간선(Edge) : 위치 간의 관계를 표시한 선으로 노드를 연결한 선이라고 보면 됨 (link 또는 branch 라고도 함) 인접 정점(Adjacent Vertex) : 간선으로 직접 연결된 정점(또는 노드) 참고 용어 정점의 차수 (Degree): 무방향 그래프에서 하나의 정점에 인접한 정점의 수 진입 차수 (In-Degree): 방향 그래프에서 외부에서 오는 간선의 수 진출 차수 (Out-Degree): 방향 그..
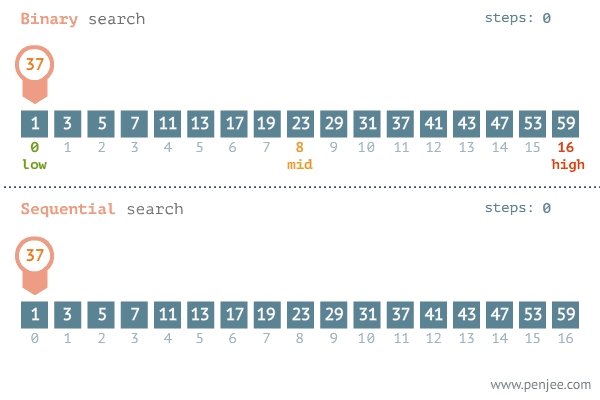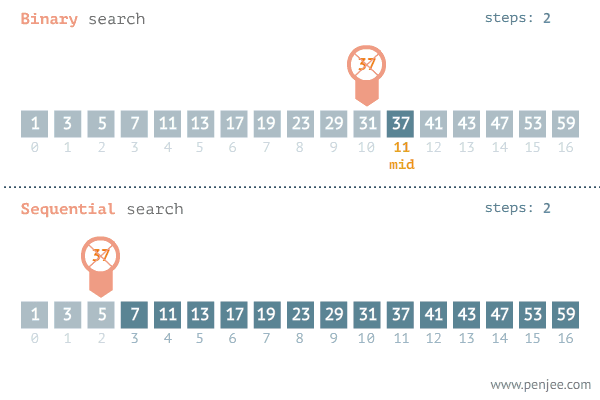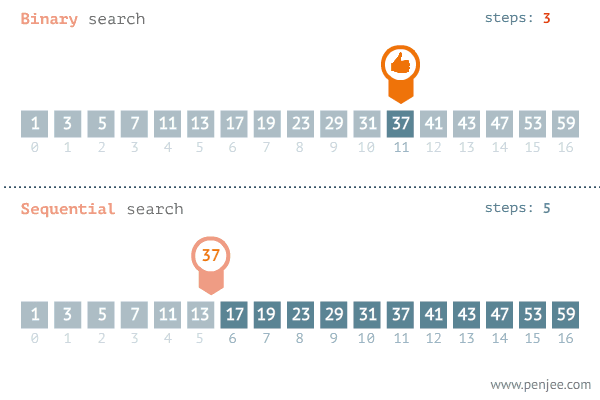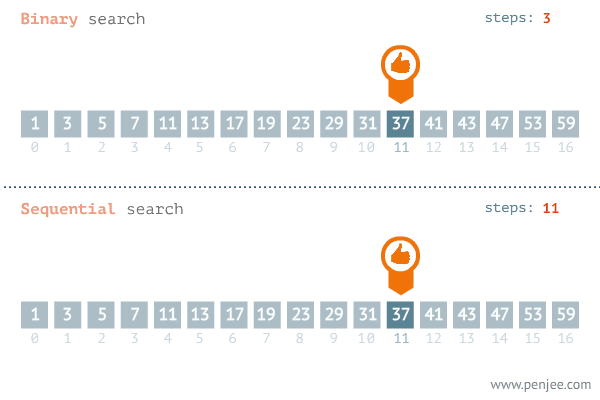
이진 탐색 (Binary search)
2021. 8. 6. 16:45
🕶 Algorithm/알고리즘
1. 이진 탐색 (Binary Search) 이란? 탐색할 자료를 둘로 나누어 해당 데이터가 있을만한 곳을 탐색하는 방법 이진 탐색의 이해 (순차 탐색과 비교하며 이해하기) 데이터가 정렬되어 있다는 가정하에서는 이진탐색이 순차탐색보다 훨씬 빠르다. 2. 분할 정복 알고리즘과 이진 탐색 분할 정복 알고리즘 (Divide and Conquer) Divide : 문제를 하나 또는 둘 이상으로 나눈다. Conquer : 나눠진 문제가 충분히 작고, 해결이 가능하다면 해결하고, 그렇지 않다면 다시 나눈다. 이진 탐색 Divide : 리스트를 두 개의 서브 리스트로 나눈다. Conquer 검색할 숫자 (search) > 중간값 이면, 뒷 부분의 서브 리스트에서 검색할 숫자를 찾는다. 검색할 숫자 (search) <..
순차 탐색 (Sequential search)
2021. 8. 6. 16:09
🕶 Algorithm/알고리즘
1. 순차 탐색 (Sequential search)이란? 탐색은 여러 데이터 중에서 원하는 데이터를 찾아내는 것을 의미 데이터가 담겨있는 리스트를 앞에서부터 하나씩 비교해서 원하는 데이터를 찾는 방법 from random import * rand_data_list = list() for num in range(10): rand_data_list.append(randint(1,100)) # 한번 호출 될때마다 하나의 수 랜덤 추가 rand_data_list >> [71, 63, 75, 33, 6, 37, 81, 79, 3, 29] 1.1 순차 탐색 알고리즘 def sequenctial(data_list, search_data): for i in range(len(data_list)): if data_lis..
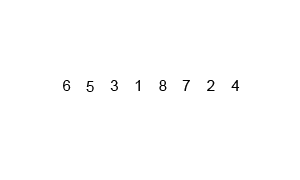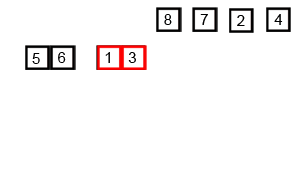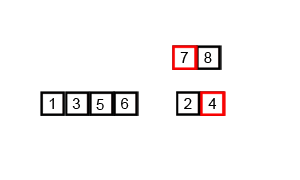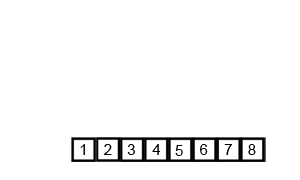
병합 정렬 (Merge sort)
2021. 8. 6. 14:03
🕶 Algorithm/알고리즘
병합 정렬 (Merge sort) 재귀용법을 활용한 정렬 알고리즘 리스트를 절반으로 잘라 비슷한 크기의 두 부분 리스트로 나눈다. 각 부분 리스트를 재귀적으로 합병 정렬을 이용해 정렬한다. 두 부분 리스트를 다시 하나의 정렬된 리스트로 합병한다. 알고리즘 이해 데이터가 네 개 일때 (데이터 갯수에 따라 복잡도가 떨어지는 것은 아니므로, 네 개로 바로 로직을 이해해보자.) 예: data_list = [1, 9, 3, 2] 먼저 [1, 9], [3, 2] 로 나누고 다시 앞 부분은 [1], [9] 로 나누고, 자를게 없어지면 다시 합병한다. 다시 정렬해서 합친다. [1, 9] 다음 [3, 2] 는 [3], [2] 로 나누고 다시 정렬해서 합친다 [2, 3] 이제 [1, 9] 와 [2, 3]을 합친다. 1 <..
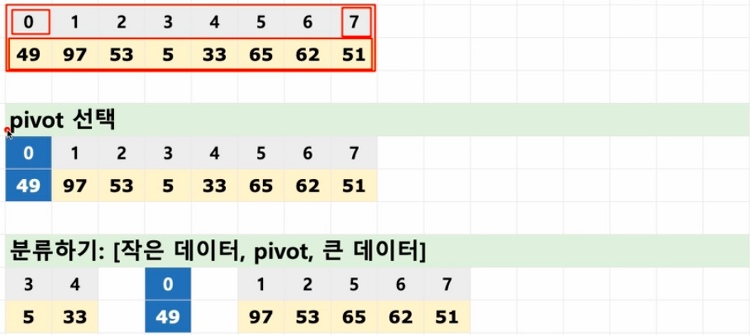
퀵정렬 (Quick sort)
2021. 7. 23. 17:38
🕶 Algorithm/알고리즘
1. 퀵 정렬 (Quick sort) 이란? 정렬 알고리즘의 꽃 기준점(pivot 이라고 부름)을 정해서, 기준점보다 작은 데이터는 왼쪽(left), 큰 데이터는 오른쪽(right) 으로 모으는 함수를 작성함 각 왼쪽(left), 오른쪽(right)은 재귀용법을 사용해서 다시 동일 함수를 호출하여 위 작업을 반복함 함수는 왼쪽(left) + 기준점(pivot) + 오른쪽(right) 을 리턴함 분할 정복 알고리즘의 예이다. (재귀 사용) 1) pivot 선택 2) [pivot보다 작은], [pivot], [pivot보다 큰] 순서대로 분류한다. (각 데이터 수 1개 될 때까지) 3) 1),2) 반복 4) 재귀적으로 합치기 다시 재귀적으로 합치기 2. 어떻게 코드로 만들까? 3. 알고리즘 구현 def qs..
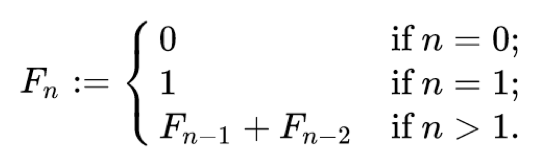
동적 계획법 (Dynamic Programming)과 분할 정복 (Divide and Conquer)
2021. 7. 23. 15:30
🕶 Algorithm/알고리즘
1. 정의 동적계획법 (DP 라고 많이 부름) 입력 크기가 작은 부분 문제들을 해결한 후, 해당 부분 문제의 해를 활용해서, 보다 큰 크기의 부분 문제를 해결, 최종적으로 전체 문제를 해결하는 알고리즘 상향식 접근법으로, 가장 최하위 해답을 구한 후, 이를 저장하고, 해당 결과값을 이용해서 상위 문제를 풀어가는 방식 Memoization 기법을 사용함 : 작은 문제들을 기억하는 것 Memoization (메모이제이션) 이란: 프로그램 실행 시 이전에 계산한 값을 저장하여, 다시 계산하지 않도록 하여 전체 실행 속도를 빠르게 하는 기술 -> 동일한 문제를 풀지 않도록 하는 것 문제를 잘게 쪼갤 때, 부분 문제는 중복되어, 재활용됨 예: 피보나치 수열 분할 정복 문제를 나눌 수 없을 때까지 나누어서 각각을 ..
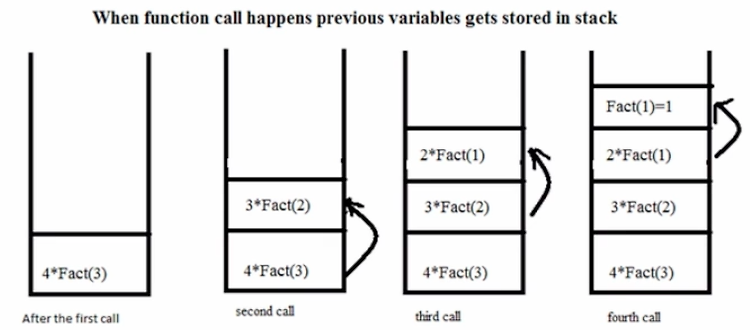
재귀 (Recursion)
2021. 7. 22. 17:07
🕶 Algorithm/알고리즘
1. 재귀 용법 (recursive call, 재귀 호출) 함수 안에서 동일한 함수를 호출하는 형태 여러 알고리즘 작성시 사용되므로, 익숙해져야 함 1.1 팩토리얼 함수 def factorial(n): if n > 1: return n * factorial(n-1) else : return 1 for num in range(10): print (factorial(num)) >> 0 1 2 6 24 120 720 5040 40320 362880 1.2 팩토리얼 함수 - 시간 복잡도와 공간 복잡도 factorial(n) 은 n - 1 번의 factorial() 함수를 호출해서, 곱셈을 함 일종의 n-1번 반복문을 호출한 것과 동일 factorial() 함수를 호출할 때마다, 지역변수 n 이 생성됨 함수는 동..
공간복잡도
2021. 7. 22. 16:33
🕶 Algorithm/자료구조
알고리즘 계산 복잡도는 다음 두 가지 척도로 표현될 수 있음 시간 복잡도: 얼마나 빠르게 실행되는지 공간 복잡도: 얼마나 많은 저장 공간이 필요한지 좋은 알고리즘은 실행 시간도 짧고, 저장 공간도 적게 쓰는 알고리즘 통상 둘 다를 만족시키기는 어려움 시간과 공간은 반비례적 경향이 있음 최근 대용량 시스템이 보편화되면서, 공간 복잡도보다는 시간 복잡도가 우선 그래서! 알고리즘은 시간 복잡도가 중심 공간 복잡도 대략적인 계산은 필요함 기존 알고리즘 문제는 예전에 공간 복잡도도 고려되어야할 때 만들어진 경우가 많음 그래서 기존 알고리즘 문제에 시간 복잡도뿐만 아니라, 공간 복잡도 제약 사항이 있는 경우가 있음 또한, 기존 알고리즘 문제에 영향을 받아서, 면접시에도 공간 복잡도를 묻는 경우도 있음 아래와 같은 ..
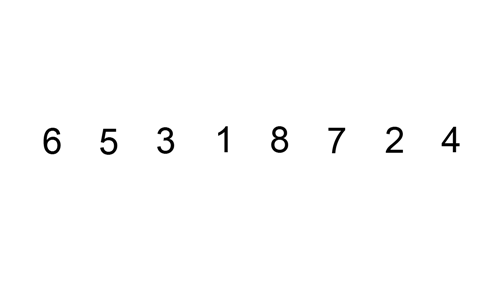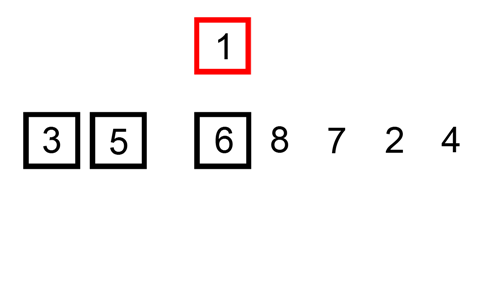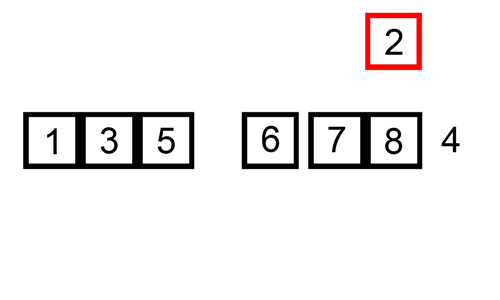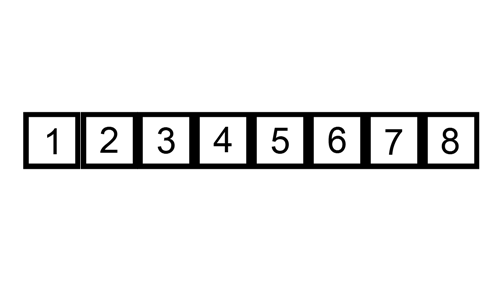
삽입 정렬 (Insertion sort)
2021. 7. 21. 18:05
🕶 Algorithm/알고리즘
1. 삽입 정렬 (insertion sort) 란? 삽입 정렬은 두 번째 인덱스부터 시작 해당 인덱스(key 값) 앞에 있는 데이터(B)부터 비교해서 key 값이 더 작으면, B값을 뒤 인덱스로 복사 이를 key 값이 더 큰 데이터를 만날때까지 반복, 그리고 큰 데이터를 만난 위치 바로 뒤에 key 값을 이동 두번째 데이터부터 시작해서 앞에 있는 것과 비교한다. 기준점과 앞으 데이터와 비교하면서, 삽입 안하고 비교만 하다가, 적절한 위치가 나오면 거기에 삽입한다. 직접 눈으로 보면 더 이해가 쉽다: https://visualgo.net/en/sorting 출처 : https://commons.wikimedia.org/wiki/File:Insertion-sort-example.gif 2. 어떻게 코드로 만..
선택 정렬 (Select sort)
2021. 7. 21. 17:02
🕶 Algorithm/알고리즘
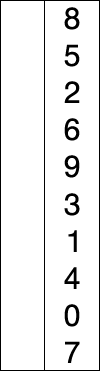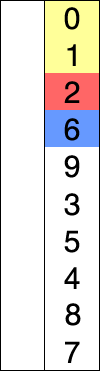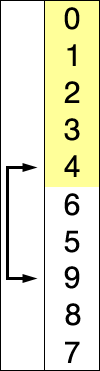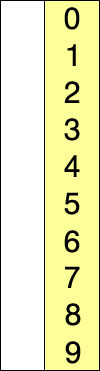
1. 선택 정렬 (Selection sort) 란? 다음과 같은 순서를 반복하며 정렬하는 알고리즘 주어진 데이터 중, 최소값을 찾음 해당 최소값을 데이터 맨 앞에 위치한 값과 교체함 맨 앞의 위치를 뺀 나머지 데이터를 동일한 방법으로 반복함 직접 눈으로 보면 더 이해가 쉽다: https://visualgo.net/en/sorting 출처: https://en.wikipedia.org/wiki/Selection_sort 마지막 데이터는 비교할 필요가 없다. 2. 어떻게 코드로 만들까? 데이터가 두 개 일때 예: dataList = [9, 1] data_list[0] > data_list[1] 이므로 data_list[0] 값과 data_ list[1] 값을 교환 데이터가 세 개 일때 예: data_list..
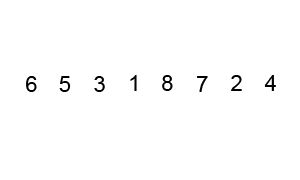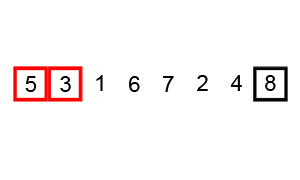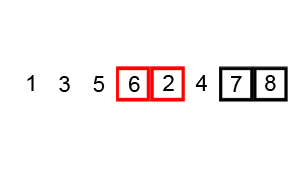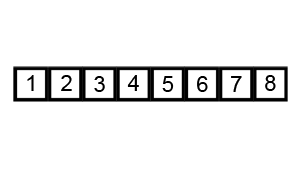
버블 정렬 (Bubble sort)
2021. 7. 21. 16:25
🕶 Algorithm/알고리즘
알고리즘 연습 방법 연습장과 펜을 준비하자. 알고리즘 문제를 읽고 분석한 후에, 간단하게 테스트용으로 매우 간단한 경우부터 복잡한 경우 순서대로 생각해보면서, 연습장과 펜을 이용하여 알고리즘을 생각해본다. 가능한 알고리즘이 보인다면, 구현할 알고리즘을 세부 항목으로 나누고, 문장으로 세부 항목을 나누어서 적어본다. 코드화하기 위해, 데이터 구조 또는 사용할 변수를 정리하고, 각 문장을 코드 레벨로 적는다. 데이터 구조 또는 사용할 변수가 코드에 따라 어떻게 변하는지를 손으로 적으면서, 임의 데이터로 코드가 정상 동작하는지를 연습장과 펜으로 검증한다. 1. 정렬 (sorting) 이란? 정렬 (sorting): 어떤 데이터들이 주어졌을 때 이를 정해진 순서대로 나열하는 것 정렬은 프로그램 작성시 빈번하게 ..