
R (17) - Support Vector Machine (SVM)
2020. 11. 13. 21:56
📌 R
Support Vector Machine SVM의 매력은 매우 아름답고 탄탄한 이론적인 배경을 바탕으로 정교하게 고안된 기계학습 알고리즘이라는 것에 있습니다. 여기에 알고리즘의 실제 적용이 여러 모로 쉽고 성능이 강력하며 따라서 실전적이라는 점이 그 매력을 더합니다. SVM에서 풀고자 하는 문제는 다음과 같습니다. "How do we divide the space with decision boundaries?" 예시와 함께 보면 좀 더 구체적으로 문제를 좁힐 수 있습니다: 우리가 ′+′ 샘플과 ′−′ 샘플을 구별하고 싶다면 어떤 식으로 나눠야 하는가? 만약 선을 그어 그 사이를 나눈다면 어떤 선이어야 할 것인가? 가장 쉽게 그리고 직관적으로 생각할 수 있는 답은 아마도 ′+′와 ′−′ 샘플 사이의 거리를..
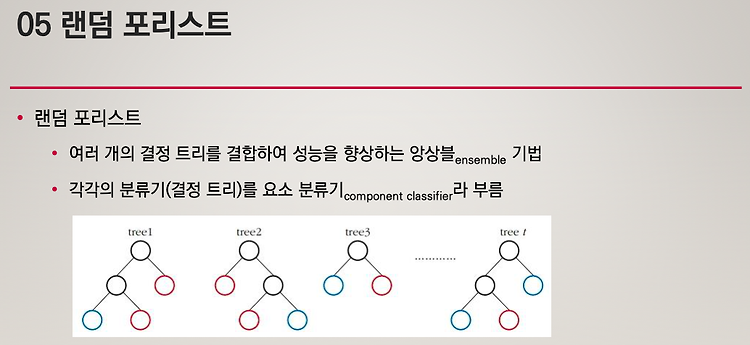
R (16) - 랜덤 포리스트
2020. 11. 13. 20:55
📌 R
랜덤 포리스트 Decision Tree는 overfitting될 가능성이 높다는 약점을 가지고 있습니다. 가지치기를 통해 트리의 최대 높이를 설정해 줄 수 있지만 이로써는 overfitting을 충분히 해결할 수 없습니다. 그러므로 좀더 일반화된 트리를 만드는 방법을 생각해야합니다. 이는 Random Forest(랜덤 포레스트)의 기원이 되는 아이디어입니다. Random forest는 ensemble(앙상블) machine learning 모델입니다. 여러개의 decision tree를 형성하고 새로운 데이터 포인트를 각 트리에 동시에 통과시키며, 각 트리가 분류한 결과에서 투표를 실시하여 가장 많이 득표한 결과를 최종 분류 결과로 선택합니다. 랜덤 포레스트가 생성한 일부 트리는 overfitting될 ..

R (15) - 회귀, 결정트리
2020. 11. 6. 16:02
📌 R
회귀 & 분류 분류(Classification)와 회귀(Regression)는 지도학습(Supervised Learning)의 목적이라 할 수 있다. - 지도학습 : 입력과 출력 데이터(훈련 데이터)가 있고 이를 모델화하여 새로운 데이터에 대해 정확한 출력을 예측하는 것 분류와 회귀는 어떻게 다른가 분류 : 결과가 이산값 회귀 : 결과가 연속값 분류 (Classification) 분류는 class를 예측하는 것이다. (세부적으로는 다중분류) 어떤 text를 입력했을 때, 그것이 어떤 class에 속하는지 예측하는 것이다. 이제는 hot하다고 말하기에는 너무 큰 흐름이 되어 버린 Deep Learning, 특히 CNN 에서 Tutorial 처럼 언급되는 개/고양이 이미지 예측 문제와 같은 것들이다. 즉, ..

R (14) - 일반화 선형 모델, 로지스틱 회귀
2020. 11. 6. 08:37
📌 R
일반화 선형모형(Generalized Linear Model) 회귀분석이나 분산분석은 종속변수가 정규분포되어 있는 연속형 변수이다. 하지만 많은 경우에 있어서 종속변수가 정규분포되어 있다는 가정을 할 수 없는 경우도 있으며 범주형 변수가 종속변수인 경우도 있다. 다음과 같은 경우에 일반화 선형모형을 사용한다. 종속변수가 범주형변수인 경우 : 이항변수( 0 또는 1, 합격/불합격, 사망.생존 등)인 경우도 있으며 다항변수(예를 들어 poor/good/excellent 또는 공화당/민주당/무소속 등)인 경우 정규분포 하지 않는다. 종속변수가 count(예를 들면 한 주간 교통사고 발생 건수, 하루에 마시는 물이 몇잔인지 등)인 경우. 이들 값은 매우 제한적이며 음수가 되지 않고 평균과 분산이 밀접하게 관련되..

R (13) - 모델링
2020. 10. 27. 16:29
📌 R
모델링과 예측 모델 = 수학식 모델을 이용하여 예측을 할 수 있다. 훈련 집합 : 주어진 데이터 독립 변수 : 설명 변수 종속 변수 : 반응 변수 모델링 = 훈련 집합을 이용하여 최적의 모델을 찾아내는 과정 모델 선택 모델을 가지게 되면 x값이 어떤 값이 오던지 y값을 예측할 수 있다. 모델을 완성하면 무엇을 해야할까? 모델의 품질 평가 평균 제곱 오차(MSE, Mean Squared Error) 평균 제곱 오차 평균 제곱 오차는 작을수록 좋다. 모델 적합 모델피팅을 하기위해서 데이터 입력을 한다. m이라는 변수에 모델 피팅을 한다. lm 이라는 함수에 반응변수와 설명변수를 입력해준다. m을 출력하면 학습된 모델이 출력된다. 모델 m에 해당하는 직선의 매개변수가 출력된다. 최적의 모델을 구할 수 있게 된..

R (12) - 워드클라우드
2020. 10. 15. 21:57
📌 R
JRE 설치 한글 워드클라우드를 사용하기 위해서는 JRE를 설치해야 한다. JRE = 자바 실행 환경 워드클라우드 문서 파일 준비 주의할점 : 마지막 문장에서 Enter 치고 끝내야 한다. 인코딩을 UTF-8로 하고 저장해야한다. KONLP 패키지 설치하기 Korea Natural Language Process = 자연어 처리 명사 추출하기 text 데이터에서 명사를 추출해서 noun에 저장 빈도수 높은 단어 막대그래프로 작성하기 워드클라우드 작성하기 random.oredr=F : 빈도가 높은 단어는 가운데에 배치. 만약 T이면 단어를 무작위로 배치 rot.per=.1 : 세로방향의 단어의 배치 비율 colors = 단어의 색 names(wordcount) freq=wordcount scale=c(6, ..
R (11) - 구글맵
2020. 10. 15. 17:30
📌 R
Application programming interface 를 통해 ggmap을 이용해보자. R 최신 버전으로 업데이트하기 ggmap 패키지 설치하기 API 키를 복사해서 저장해놔야 한다. 예제1) 서울시 종로구 근방 지도 보기 register_google(key='구글 API 키') geocode : 지명을 경도와 위도로 바꾼다. enc2utf8("한글") : 한글 포맷을 utf8 포맷으로 바꾸어준다. gc에는 경도와 위도가 들어간다. gc를 벡터타입으로 변경을 해서 cen 변수에 넣어준다. center=cen : 지도의 중심을 cen으로 하겠다는 것 그것을 매개변수로 하여 지도를 가지고 온다. center zoom size maptype geocode : 설악산의 지도를 보기 위해서 한글 인코딩을 ..
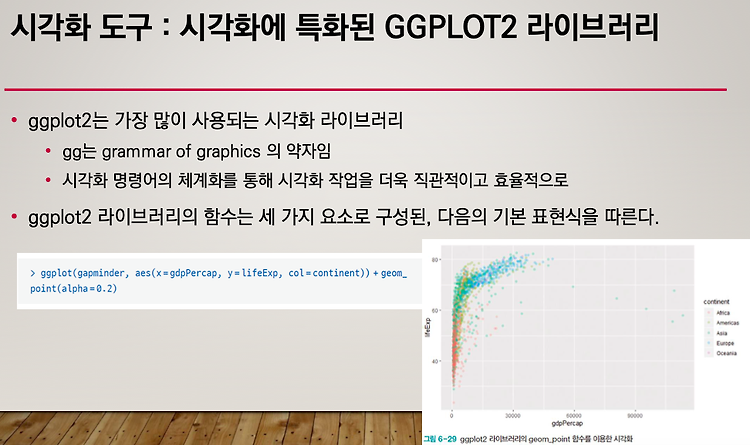
R (10) - ggplot2
2020. 10. 14. 22:00
📌 R
ggplot2 aes(가로축, 세로축) geom_point 아무런 옵션을 주지 않으면 위로 쌓인다. 대륙을 기반으로 나눠진다. 옆으로 나란히 그리고 싶다면 position=dodge 옵션을 추가한다. geom_boxplot geom_histogram scale_x_log10 coord_flip 가로축 세로축 바꾸기 scale_fill_brewer 팔레트를 사용해서 칼라를 사용한다. RColorBrewer 라이브러리 이용 쿠웨이트 관찰 데이터 가공시간을 줄일 수 있고 데이터를 직관적으로 파악한 뒤에 어떠한 관점으로 분석할 것인지 파악할 수 있어서 데이터를 시각화한다.

R (9) - 데이터 시각화, 상관관계, legend, matplot, treetop
2020. 10. 7. 18:18
📌 R
거의 비슷한 데이터처럼 보인다. 거의다 유사한 데이터인 것 같았는데 시각화 해보니 다르게 보였다. 가시화를 왜 해야 하는지 보여주는 데이터이다. 단순하게 그림으로 본다 이런게 아니라 데이터의 신뢰성을 상승시키는 작업이 데이터 시각화이다. x좌표는 연도 y 좌표는 합산된 값 사용자 입장에서는 이 그래프는 무엇을 말하는지 모를 수 있다. 색깔이 다 똑같기 때문에 그래서 하나하나 옵션을 집어넣어 보자. col = y$continent : 대륙끼리는 다른 색깔로 칠해달라 모양을 바꿔보자. pch pch = 몇 ## 으로 하면 하나의 모양으로 바뀐다. pch = c(1:5) # 5개의 모양으로 pch = c(1:length(levels(y$continent))) # 만약 5개로 끝나지 않고 계속 바뀔거 같으면 l..
R (8) - 데이터 가공, apply(), select(), filter(), group_by(), summaries()
2020. 10. 4. 21:17
📌 R
크로아티아만 뽑고 싶다? 조건식을 넣어서 추출하면 된다. apply() : 연산 DPLYR 라이브러리 dplyr 팩키지가 데이터프레임을 솜씨있게 조작하는데 유용한 많은 함수를 제공한다. 이를 통해서, 위에서 언급된 반복을 줄이고, 실수를 범할 확률도 줄이고, 심지어 타이핑하는 수고도 줄일 수 있다. 보너스로, dplyr 문법은 훨씬 더 가독성도 높다. select() 데이터 프레임에서 변수 일부만 뽑아서 작업하고자 할 때 select()를 쓴다. filter() 꼬박꼬박 쓰지 않아도 돼서 간편하다. year_country_gdp_euro % filter(continent=="Europe") %>% select(year,country,gdpPercap) gapminder 데이터프레임을 filter() 함수..
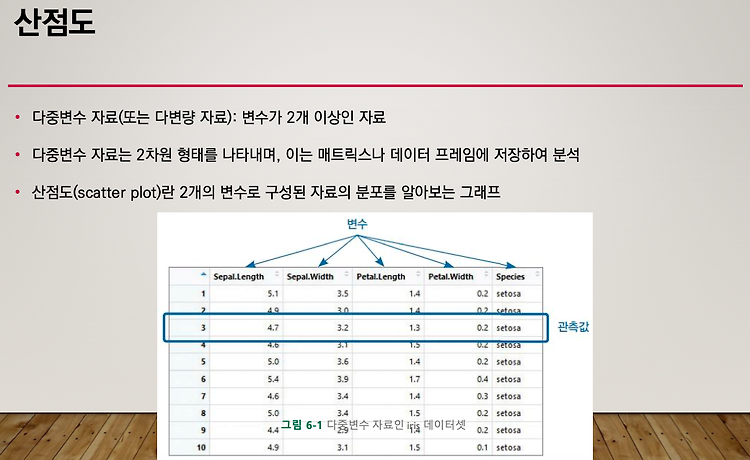
R (7) - 산점도, 상관분석, 선그래프
2020. 9. 24. 13:51
📌 R
산점도 : plot() 두개의 변수로 구성된 자료의 분포를 알아보는 그래프 pch 번호 두 변수 사이의 관련성을 확인하는데에 산점도가 쓰인다. 여러 변수들 간의 산점도 : pairs() 4개 중 2개씩 짝지어 지므로 다양한 산점도가 나타난다. 대각선을 기준으로 대칭되는 특징이 있다. 속성값이 많을 때에는 다중 산점도로 표현할 수 있다. 그룹 정보가 있는 두 변수의 산점도 : plot() 꽃잎의 길이와 폭의 상관관계를 알 수 있다. 관측값의 비교 뿐만 아니라 그룹간의 관계도 알 수 있다. 상관분석 : cor() r이 1이면 거의 선의 모양 r이 0.5이면 선형성이 있긴 하지만 약간 분포가 되어 있다. 약한 선형성을 가진다. r이 0인 경우엔 선형성의 거의 없다라고 판단할 수 있다. cor() : 두 변수 ..

R (6) - 자료의 종류, table, barplot, pie, quantile, hist, boxplot
2020. 9. 23. 22:19
📌 R
범주형 자료 연속형 자료 단일변수 자료 & 다중변수 자료 벡터는 여러개의 변수를 사용할 수 없기 때문에 단일변수 자료는 벡터에 넣는다. 크기를 측정할 수 없는 자료 : 범주형 자료 도수분포표 : table() 막대그래프 : barplot() 원 그래프 : pie() 자료값의 이름을 colors로 바꾼다. col = colors 라고 하면 실제로도 색깔을 지정하게 된다. 평균과 중앙값 사분위 수 : quantile() 사분위 수 : 4등분 하는 지점의 값 제2 사분위 수 : 중앙값 3개를 기준으로 판단하기 때문에 더 많은 정보를 얻을 수 있다. 산포 분산고 표준편차가 작으면 자료의 관측값이 평균값 부근에 많이 모여있다는 뜻 range() : 자료값의 범위를 알려준다. diff(range()) : 어느정도의..

R (5) - if else, 반복문, 결측값, 이상값
2020. 9. 22. 22:12
📌 R
데이터 프레임의 경우 행과 열의 조건을 모두 표기할 수 있어서 쉼표로 나타낸다. 벡터는 그럴 수가 없어서 일렬로 나타낸다. if 문 파이썬은 들여쓰기로 파악하지만 R은 괄호로 파악한다. ifelse 문 warning message : 실행은 됐는데 에러는 아니지만 확인해보아라. if (){ } else { } 이런식으로 if문의 } 가 끝나는 라인에 else를 붙여줘야한다. 반복문 repeat 문 계속 반복되기 때문에 break를 걸어줘야 한다. while 문 for 문 함수 데이터 정제 : 결측값 처리 is.na 로 TRUE 값이 44가 나왔으므로 NA 값이 44개 라는 뜻이다. TRUE 값이 나오지 않았다면 NA 값이 존재하지 않는 것이다. 평균 값이 달라졌는데 na.omit으로 na가 있는 모든 열..
R (4) - 엑셀, csv, txt 파일 가져오기, 데이터 추출, 조건문
2020. 9. 15. 15:58
📌 R
리스트는 숫자와 문자를 같이 넣을 수 있다 = 다중형 R studio 엑셀파일 가져오기 : read_excel() R studio 메뉴로 .txt 파일 가져오기, .csv 파일, 엑셀 파일 가져오기 R studio .rda 파일로 저장하고 불러오기 저장하기 : save(데이터 셋, file = "파일명") 불러오기 : load("경로/파일명") Rstudio .csv 또는 .txt 파일로 저장하기 write.table(데이터셋, file = "경로/파일명") 쉼표로 구분된 .txt 파일 가져오기, 변수명을 추가하여 가져오기 쉼표로 구분 : read.table("경로/파일명", header=TRUE, sep=",") 변수명 추가 : read.table("경로/파일명", sep=",", col.names=v..

R (3) - 배열, 매트릭스, 데이터프레임, 리스트, 팩터
2020. 9. 14. 18:36
📌 R
매트릭스(matrix) : 모든 셀의 자료형이 동일한 컬럼들로 구성 데이터프레임(data frame) : 자료형이 다른 컬럼들로 구성 한칸 = 셀 matrix(매트릭스에 저장될 값, nrow = 행의 수, ncol = 열의 수) matrix(매트릭스에 저장될 값, nrow = 행의 수, ncol = 열의 수, byrow=T) 행의 방향으로 값을 대입한다. cbind() : 열방향 결합 rbind() : 행방향 결합 cbind(x,y) : 열들로 만들어서 결합하여 매트릭스 생성 rbind(x,y) : 행들로 만들어서 결합하여 매트릭스 생성 인덱스값을 이용하여 매트릭스에서의 값 추출하기 매트릭스에서 여러개의 값을 추출하기 매트릭스의 행과 열에 이름을 지정하기 데이터 프레임 표 형태의 데이터구조이다. 행렬과 ..