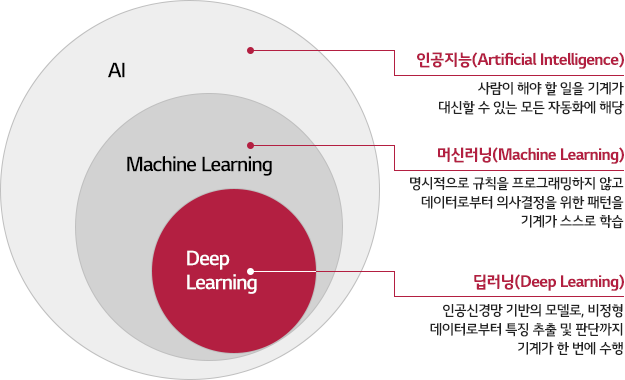
DL - tech interview
2022. 4. 11. 09:33
💡 AI/DL
목차 딥러닝은 무엇인가요? 딥러닝과 머신러닝의 차이는? Cost Function과 Activation Function은 무엇인가요? Data Normalization은 무엇이고 왜 필요한가요? 알고있는 Activation Function에 대해 알려주세요. (Sigmoid, ReLU, LeakyReLU, Tanh 등) 오버피팅의 경우 어떻게 대처해야 할까요? 하이퍼 파라미터는 무엇인가요? Weight Initialization 방법에 대해 말해주세요. 그리고 무엇을 많이 사용하나요? 볼츠만 머신은 무엇인가요? TF, PyTorch 등을 사용할 때 디버깅 노하우는? Neural Network의 가장 큰 단점은 무엇인가? 이를 위해 나온 One-Shot Learning은 무엇인가? 1. 딥러닝은 무엇인가요?..
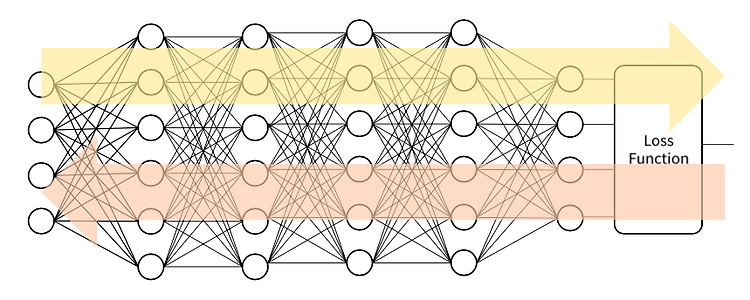
Back-Propagation 의 Chain Rule
2021. 2. 1. 15:26
💡 AI/DL
Back propagation 의 가장 핵심적인 미분 계산을 수식적으로 자세히 뜯어보고 이해해보자. 합성함수로서의 DNN 입력, 함수모델, 정답은 fix되어있다. Activation function, loss function도 이미 정의가 되어있는 상태이다. 변할 수 있는건 Trainable parameter와 손실값(L) 밖에 없다. 그렇기 때문에 n번째 함수 fn은 n-1번째 데이터셋 값을 입력 받아서 Wn, bn 파라미터가 조건부로 들어가게 된다. 다 넣었으면 이제 데이터 셋의 입력과 출력 값은 중요하지 않게 된다. 손실을 최소화하는 파라미터만 찾으면 되기 때문이다. DNN의 Chain Rule Fully Connected Layer의 미분 Sigmoid 함수의 미분 Back Propagation ..
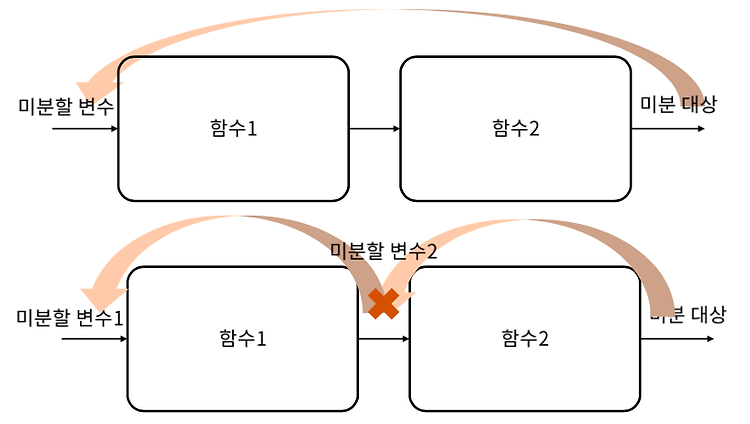
Chain Rule
2021. 2. 1. 15:20
💡 AI/DL
Chain Rule 간단히 개념만 알고 넘어갔던 연쇄 법칙을 수식으로 이해해 보자. 직렬 연결된 두 함수의 미분 Chain Rule의 확장 모두 곱한다. 동적 계획법으로 저장해 놓고 계속 미분하며 곱할 수 있다.
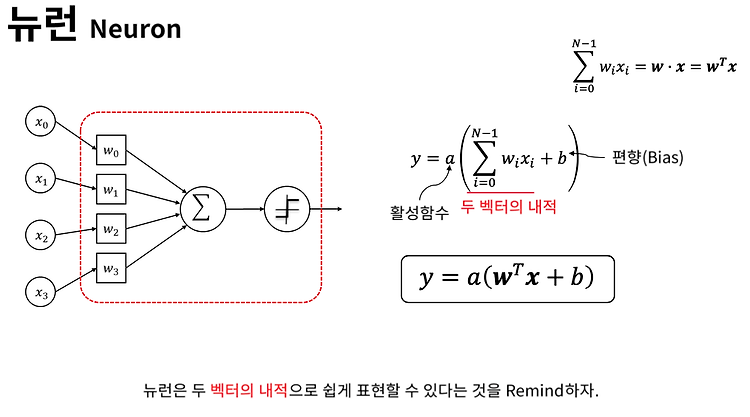
DNN의 수학적 이해
2021. 2. 1. 15:17
💡 AI/DL
뉴런은 여러개의 입력을 받아 가중치를 곱해서 합해주고 non linear activation function을 이용해서 출력을 해주는 가장 기본적인 단위이다. 전결합 계층 (Fully Connected Layer) 모든 뉴런들을 연결한 Layer가 Fully connectecd layer이다. 간단한 matrix의 곱으로 표현할 수 있다. 볼드체(x, b, y)는 벡터이고 W는 벡터이다. DNN 블랙 박스 모델 (Black Box Model) 손실을 최소화 하는 방향으로 학습한다. 어떤 블랙박스 모델이 있고 trainable parameter가 4개라고 해보자. 블랙 박스 모델의 학습 수치적 기울기 (Numerical Gradient) 에타값이 충분히 작다면 수치적 기울기를 미분값으로 사용할 수 있다. ..

Deep Neural Network - Back Propagation
2021. 2. 1. 15:08
💡 AI/DL
Shallow Neural Network 에 이어서 Deep Neural Network에 대해서 배워보자. 뉴런 입력이 들어왔을 때 가중치와 bias를 곱해주고 Summation 한 다음 Activation function을 이용해서 Nonlinear 연산으로 출력을 하는게 뉴런이다. Shallow Neural Network Hidden layer 에서는 dense layer(=fully connected layer)를 통해 계산한다. 보통 SNN의 Hidden layer에서는 Sigmoid를 이용한다. Output layer의 경우에서 사용되는 activation function은 linear 또는 softmax를 이용한다. softmax를 이용하면 확률로 나오면서 classification에 이용된다..
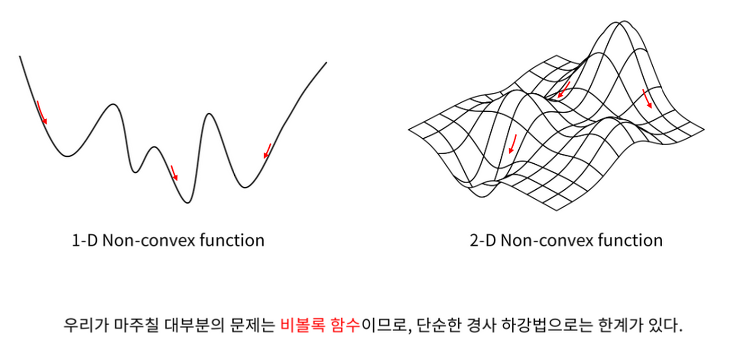
심화 경사하강법
2021. 1. 31. 15:08
💡 AI/DL
비볼록 함수 지역 최솟값 (Local minimum) 안장점 (Saddle point) 한쪽으로는 최댓값, 다른 쪽으로는 최솟값을 띄는 곳 전반적으로 봤을 때 최댓값도 최솟값도 아니게 되는 지점이 된다. 기울기가 0이 되지만 극값이 아니다. 경사하강법의 여러가지 접근 방법 1. 관성 (Momentum) 관성을 이용해서 계속해서 내려갈 수 있는 힘을 갖게 한다. vt = t-1 번째와 t 번째 사이에 있는 이동벡터 vt는 학습률 x 기울기에 이전 속도에 관성계수를 곱해서 더해준 것 밖에 없다. 2. 적응적 기울기 (AdaGrad) Adaptive gradient는 변수별로 학습률이 달라지게 하는 방법이다. 기존의 gradient descent에 해당하는 부분은 -η·▽f(xt-1)이다. 이 부분에 1/루트..
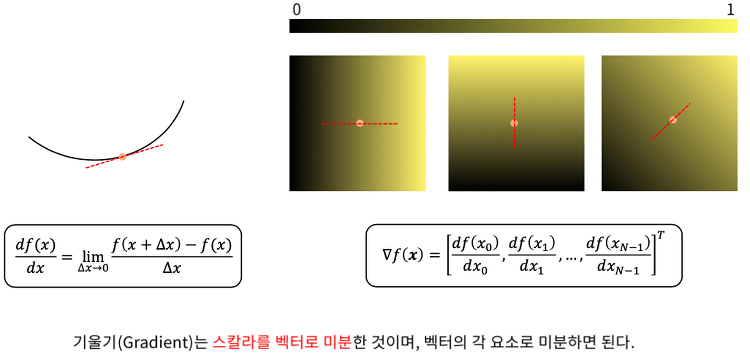
경사하강법의 수학적 표현
2021. 1. 31. 14:15
💡 AI/DL
미분과 기울기 2D, 3D로도 표현이 가능하다. 편미분을 이용해야 x에 대해서, x1에 대해서, xN-1에 대해서 편미분 할 수 있다. 경사하강법 양수일 때 반대로 이동하기 위해서 (-)를 곱해준다. 최종적으로 최소값을 따라가게 된다. f(x)값이 변하지 않을 때까지 반복한다. 학습률의 선택
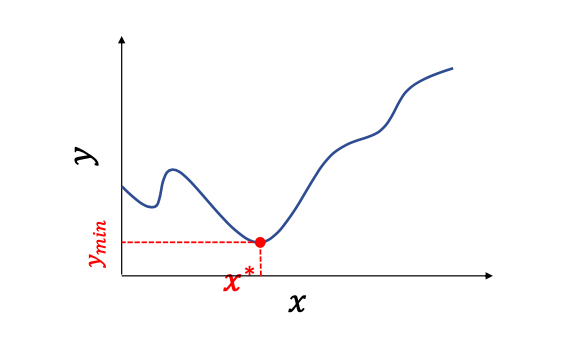
최적화 이론의 수학적 표현
2021. 1. 28. 09:39
💡 AI/DL
최적화 이론의 수학적 표현 개념은 이해했으니 이제 수학적으로 어떻게 표현하는지 알아보자. 최적화 이론 (Optimization Theory) f(x)라는 함수가 주어진다. 이 함수는 Loss function이다. 우리는 이것을 minimize 해야한다. 가장 작게 하는 x값이 중요하다. g(x)와 h(x)는 제약 조건이다. 몇개라도 제약을 줄 수 있고 어떻게 제약을 주냐에 따라서 최적화 문제를 어떻게 풀 것인가가 달라지게 된다. 제약 조건에 맞는 x들 중에서 최적해(f(x)의 최소값)를 찾는다. 최소화 문제나 최대화 문제는 사실 동일한 문제이다. 왜냐하면 - 만 붙이면 되기 때문이다. 딥러닝에서는 제약조건을 사용하지 않는다. Analytical method vs Numerical method 최적화 문제..
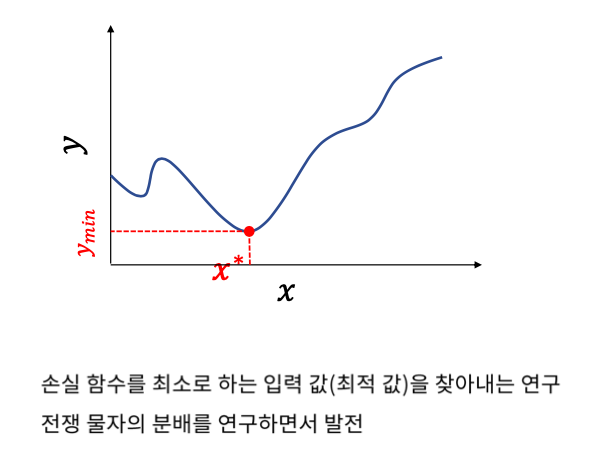
Gradient Descent 란?
2021. 1. 28. 09:12
💡 AI/DL
최적화 이론 최적화 이론은 함수의 출력이 최대나 최소가 되게하는 입력값을 찾는 것이라고 하였다. 무차별 대입법 (Brute-Force) Brute Force는 최적화 방법의 가장 단순한 방법이다. 실제로 사용할 수는 없다. 범위를 알아야 하기 때문에 아무리 다 대입해봐야 찾지 못할 수도 있다. 주변에 더 작은 f(x)의 값이 있을 수 있기 때문에 무한하게 조사해야 한다. 따라서 계산복잡도가 매우 높다. 이것을 알고리즘이라고 하기엔 어렵다. 경사하강법 (Gradient Descent) Gradient는 기울기를 의미한다. 경사를 따라서 여러번 스텝을 밟아 최적점으로 다가가는 것을 경사하강법이라고 한다. 랜덤한 시작점에서 미분을 하게되면 하나의 기울기를 얻게 된다. 그러면 어느 방향으로 가야 더 내려가는지 ..
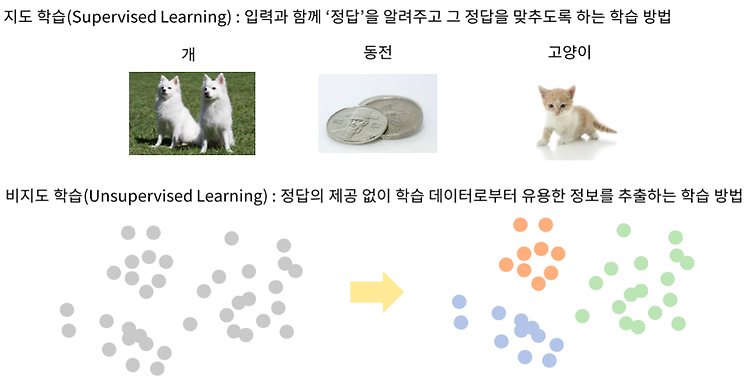
Supervised Learning, Unsupervised Learning, Loss function
2021. 1. 28. 08:54
💡 AI/DL
지도학습 vs 비지도학습 지도 학습 : 입력과 함께 정답을 알려준다. 비지도 학습 : 정답이 없이 입력만 잔뜩 받는다. 그러면 컴퓨터가 이렇게 묶어서 주어지는 특성들을 이용해 유용한 정보를 추출해내는 학습법 사람의 지도학습 점점 공부를 하다보면 어떤 것이 나무인지 일반화할 수 있다. 데이터셋이 굉장히 중요하다. 데이터셋을 가지고 학습을 해주면 어떤 데이터가 나무인지 동전인지 개인지 알 수 있다. 학습 매개변수 (Trainable Parameters) 초기에는 a=0, b=1 이다. 점점 학습이 되면서 점점 더 점들을 잘 표현할 수 있는 직선을 가지게 된다. 학습 매개변수가 변화하면 출력이 변하게 된다. 손실 함수 (Loss Function) 손실함수 : 알고리즘이 얼마나 잘못하고 있는지 표현해주는 지표 ..
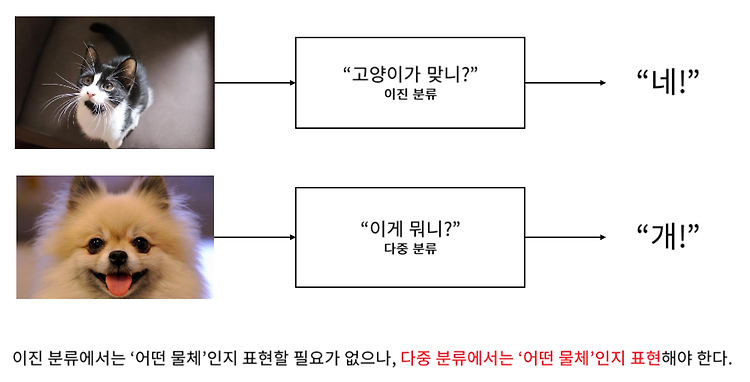
SNN을 이용한 Multi-Class Classification
2021. 1. 27. 19:50
💡 AI/DL
다중 클래스 분류 (Multi-Class Classification) 이진 분류의 경우 "네", "아니오"로만 답하여 출력이 하나면 된다. 다중 분류의 경우 "이게 뭐냐?" 라고 물었을 때 "개" 라고 답할 수 있어야 한다. 그럼 정답을 어떻게 표현해야 할까? One-Hot Encoding : 정답을 어떻게 표현할 것인가? 전부다 0이고 하나만 1인 경우, 하나만 자극을 받아서 원 핫이라고 한다. 벡터의 각 element가 의미가 있다. 인코딩을 위해 테이블을 만들어 주어야 한다. 총 N개의 레이블이 있어야 한다. One-Hot Encoding의 희소표현 (Sparse Vector) 대부분의 값이 0이고 희소하게 나타나는 벡터를 희소벡터라고 한다. SNN을 이용한 다중 클래스 분류 Softmax를 이용하..
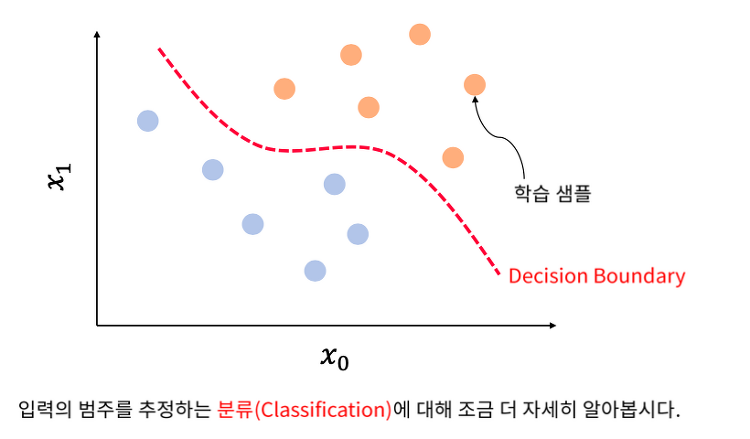
SNN을 이용한 Classification, Sigmoid function
2021. 1. 27. 18:52
💡 AI/DL
분류 (Classification) x0과 x1의 입력을 받는 샘플을 잘 나눌 수 있는 선을 그었다면 Classification 문제를 잘 풀었다고 할 수 있다. 이 선은 Decision Boundary 라고 한다. 로지스틱 회귀 (Logistic Regression) 로지스틱 회귀는 사람, 계, 돼지 등의 범주형 데이터를 대상으로 한다. 그저 구분하기 위함이다. 선형 회귀는 숫자를 대상으로 한다. 범주형 데이터를 분류하는 방향이기 때문에 범주가 다른 서로 다른 데이터를 잘 구분하는 것이 로지스틱 회귀이다. Sigmoid function Sigmoid function은 모든 실수, 즉 무한대에 가까운 입력 값에 대해서도 출력이 가능하고, 이를 확률로 표현할 수 있다. 0을 기준으로 주변을 보았을 때 빠르..
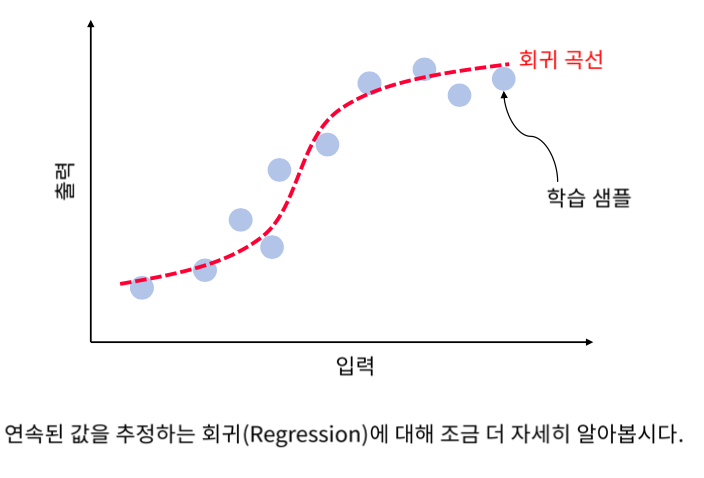
회귀 문제의 이해
2021. 1. 27. 18:17
💡 AI/DL
회귀 (Regression) 단순 선형 회귀 (Linear Regression) 가장 작은 MSE를 찾는 것이 목적이다. 평균 제곱 오차 (Mean Squared Error) 길이와 체중을 추정하는 알고리즘이 있다. y 정답에 대해서 어떤 알고리즘으로 ~y의 추정을 했을 때 5.8의 오차가 있다. 이것을 더 좋은 알고리즘을 통해 ~y의 추정으로 1.2의 오차를 표현할 수 있다. 이 추정은 MSE를 이용한다. 다중 선형 회귀 입력이 여러개가 된다면 변수가 여러개가 되고 각각의 가중치를 곱해주게 된다. 다중 선형 회귀의 기하학적 해석 얕은 신경망과 회귀 알고리즘 Hidden Layer : 출력이 여러개일 때는 매트릭스 형태로 연산하게 된다. M x N Output Layer : 출력이 하나일 때는 매트릭스 ..
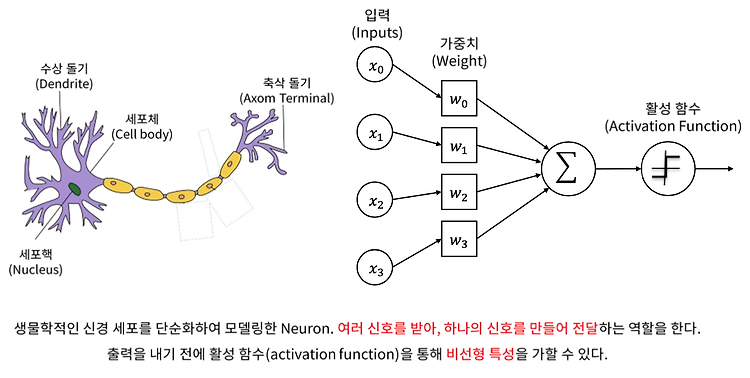
Shallow Neural Network의 수식적 이해 (Weight, Bias)
2021. 1. 27. 17:25
💡 AI/DL
얕은 신경망은 입력, 은닉, 출력 계층으로 이루어져 있다. 뉴런의 수학적 표현 뉴런은 입력이 들어오면 각 입력의 가중치가 곱해지고, 그것을 전부 더해줘서 마지막에 활성함수를 통해 출력을 낸다. 출력이 y라면 입력 xi에 가중치 wi를 곱해서 Bias를 더한 후 활성함수 a() 를 통과한다. 입력치와 가중치를 곱한 것은 두 벡터의 내적과 같다. Bias가 없을 경우 뉴런이 표현할 수 있는 그래프는 원점을 지나는 선밖에 없다. 따라서 Bias는 항상 있는 것으로 생각해 주어도 된다. 가중치(weight)란? 뉴런의 연결선 색이 다르다는 것은 입력 데이터가 각기 다른 값으로 뉴런으로 전달되었다는 의미이다. 데이터의 값은 같은데 다른 값으로 전달되려면 이 입력값에 각기 다르게 곱해지는 수치가 있어야할 것이다. ..
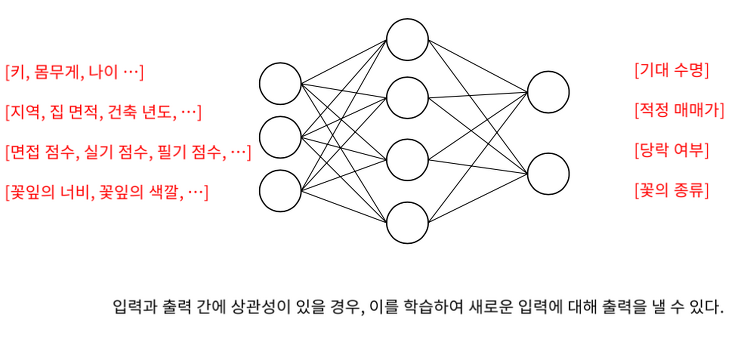
Shallow Neural Network를 이용한 분류와 회귀
2021. 1. 27. 17:02
💡 AI/DL
얕은 신경망(Shallow Neural Network)으로 무엇을 할 수 있을까? 회귀 (Regression) 입력과 출력이 있을 때 기대수명(training sample)이 있을 때, 새로운 입력에 대한 출력을 내기 위해서 선을 그어야 한다. 그것이 바로 회귀(Regression) 곡선이다. 엑셀에서는 추세선으로 쓰인다. 회귀라는 것은 입력에 대해서 출력이 정확하게 떨어지지 않는 것에 대해서, 잡음에 대해서 규칙을 찾아서 연속된 값을 추정해 내는 것이다. 분류(Classification) 연속된 값을 출력으로 내는 회귀와 달리, 입력 값에 대해서 특정 범주로 구분하는 작업을 분류(Classification)이라고 한다. 얕은 신경망을 이용한 회귀 활성함수에 대해서 달라진다. 얕은 신경망을 이용한 이진 ..
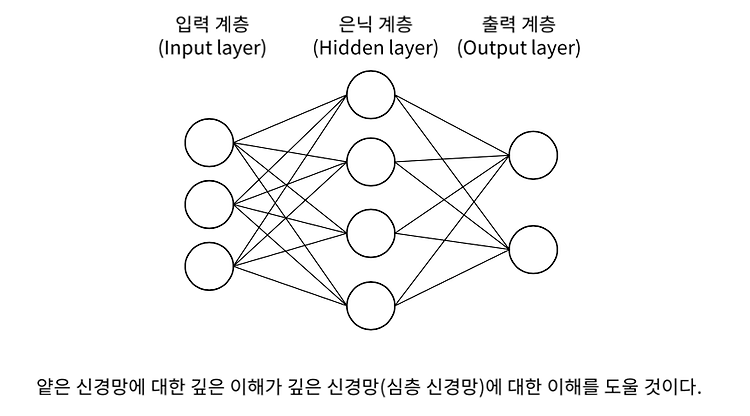
Shallow Neural Network의 구조
2021. 1. 27. 16:46
💡 AI/DL
신경세포 뉴런에서 입력이 여러개가 들어오고 가중치를 통해 합쳐지게 되고 활성함수를 통해 다음 출력으로 전달된다. 입력 = 수상돌기 활성함수 = 축삭돌기 linear한 특성을 가진 것들을 출력을 내기 전에 활성함수에서 비선형적인 특성을 갖게 할 수 있다. 뉴런의 그래프 표현 노드안에서 연산이 이루어진다. 활성함수를 적용하는 것 Node = 연산 Edge = 데이터가 흘러 들어오는 연결성 인공신경망 (Artificial Neural Network) 노드들이 어떤 형태로든 연결되면 인공신경망이라고 할 수 있다. 모든 DNN은 인공신경망 구조로 구성되어 있다. 하나의 레이어와 다음 레이어가 모두 연결된 것을 Fully-Connected Layer 라고 한다. 얕은 신경망 계층 (Shallow Neural Net..