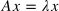
Statistics/Math - interview
2022. 3. 23. 10:46
✏️ Mathemathics/Statistics and Probability
목차 고유값(eigen value)와 고유벡터(eigen vector)에 대해 설명해주세요. 그리고 왜 중요할까요? 샘플링(Sampling)과 리샘플링(Resampling)에 대해 설명해주세요. 리샘플링은 무슨 장점이 있을까요? 1. 고유값(eigen value)와 고유벡터(eigen vector)에 대해 설명해주세요. 그리고 왜 중요할까요? 정방행렬 A (n x n) 는 임의의 벡터 x (n x 1) 의 방향과 크기를 변화시킬 수 있다. 수많은 벡터 x 중 어떤 벡터들은 A 행렬에 의해 선형 변환되었을 때에도 원래 벡터와 평행한 경우가 있다. 이렇듯 Ax 가 원래 x 에 상수(람다)를 곱한 것과 같을 때의 x 를 고유 벡터, 람다를 고유값이라 한다. 아래처럼 x1 은 A에 의해 변환되었음에도 x1 과 ..
나이브 베이즈 분류기
2021. 5. 29. 16:23
✏️ Mathemathics/Statistics and Probability
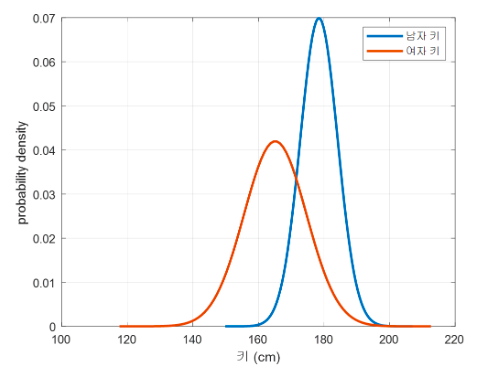
나이브 베이즈 분류기는 각 클래스에 대한 가능도(Likelihood) 비교를 통한 분류이다. 또한 베이즈 정리의 철학을 기반으로 작동하는 분류기이다. 베이즈 정리 : 확률을 갱신해 나가는 정리 사전 지식을 이용한 분류 : prior 확률적인 배경 지식을 가지고 특별한 추가 정보 없이 어떤 샘플을 분류하는 예시를 생각해보자. 가령 아무 사람이나 데리고 와서 어떤 정보도 없이 이 사람이 남자인지 여자인지 분류하라고 하면 어떻게 생각할 수 있을까? 세상에 절반은 남자고, 절반은 여자라고 생각한다면 50% 확률로 어림짐작 할 수 밖에 없다. 아마 랜덤하게 두 성별 중 하나를 얘기할 수 밖에 없을 것이다. 이것이 사전적인 정보만으로 어림짐작을 하는 방법이다. 그런데, 가령 삼색이 고양이를 데리고 와서 고양이의 성..
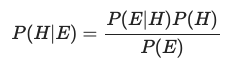
베이즈 정리의 의미
2021. 5. 29. 15:38
✏️ Mathemathics/Statistics and Probability
기본적으로 활용되는 베이즈 정리에 대해 알아보자. 우선 베이즈 정리의 공식부터 확인해보도록 하자. 총 네 개의 확률값이 적혀져 있으며, 생김새도 거의 비슷비슷해 그냥 보기에는 의미를 파악하기가 어렵다. P(H) : 사전 확률 P(H|E) : 사후 확률 네 개의 확률 값 중 P(H)와 P(H|E)는 각각 사전 확률, 사후 확률이라고 부른다. 베이즈 정리는 근본적으로 사전확률과 사후확률 사이의 관계를 나타내는 정리이다. 그렇다면, 우리는 사전확률과 사후확률의 의미를 파악함으로써 베이즈 정리가 말하는 바와 그 의의를 이해할 수 있을 것이다. 베이즈 정리를 이해하기 어려웠던 이유 베이즈 정리를 이해함에 있어서 가장 먼저 정리해야 할 개념은 ‘확률’에 관한 관점이다. 베이즈 정리의 의미를 이해하기 어려운 이유 중..
최대우도법
2021. 5. 29. 13:45
✏️ Mathemathics/Statistics and Probability
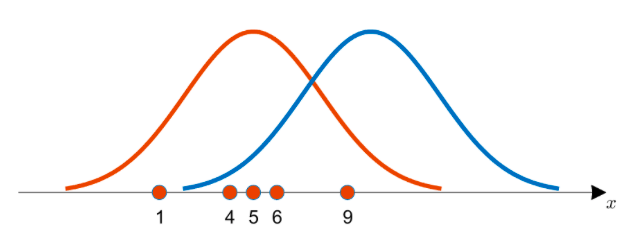
최대우도법 최대우도법(Maximum Likelihood Estimation, 이하 MLE)은 모수적인 데이터 밀도 추정 방법이다. 다양한 파라미터 θ=(θ1,⋯,θm)으로 구성된 어떤 확률밀도함수 P(x|θ)에 대해서 관찰하고 표본 데이터 집합을 x=(x1,x2,⋯,xn)이라 할 때, 이 표본들에서 파라미터 θ=(θ1,⋯,θm)를 추정하는 방법이다. 당연히, 이 말만 보면 MLE가 뭔지 이해하기는 불가능하기 때문에 예시를 들어 MLE에 대해 알아보도록 하자. 위와 같이 5개의 데이터 {1, 4, 5, 6, 9} 를 얻었다고 하자. 이 데이터를 어떤 분포로 부터 얻었을까? 를 알고 싶다. 주황색 분포, 파란색 분포 중 어떤 데이터에서 얻었을까? 아마 주황색 분포가 좀더 가능성이 있을 것이다. 그럼 이것을 ..
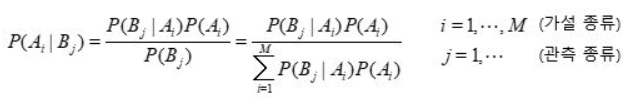
사전 확률과 사후 확률
2021. 5. 29. 13:21
✏️ Mathemathics/Statistics and Probability
사전 확률 ( Prior Probability ) 현재 가지고 있는 정보를 기초로하여 정한 초기 확률 확률 시행 전에 이미 가지고 있는 지식을 통해 부여한 확률 ex) 동전을 던져 앞면이 나올 확률 : 1/2 사후 확률 ( Posteriori Probability) 사건 발생 후에 어떤 원인으로부터 일어난 것이라고 생각되어지는 확률 추가된 정보로부터 사전정보를 새롭게 수정한 확률 ( 수정 확률 ) 조건부 확률을 통해 사후 확률을 표현할 수 있음 사후확률은 베이즈 정리로 부터 구할 수 있다. 사후 확률의 계산 => 베이즈 정리 사후확률 P(A|B)을 사전확률 P(A),P(B) 및 조건부확률 P(B|A)로 표현할 수 있음 - 여기서 P(Ai|Bj)는 사후확률 B는 관측, A는 원인, 즉, 관측 B를 보고 원..


단순 선형 회귀분석 - 회귀계수의 구간추정
2020. 4. 9. 20:52
✏️ Mathemathics/Statistics and Probability
더보기 베타 1은 Sxy/Sxx다 x,y의 공분산/x의 편차제곱 통계는 뭐라 그랬냐? 통계는 다 변동성이다. 딱 결정된것이 아니라 변동성이 있다. 하나의 값이 아니라 구간으로 추정한다. 평균을 추정하든 분산을 추정하든 비율을 추정하든 점추정이 있고 구간추정이 있다. 지난시간 점추정을 했고 이번시간 구간추정을 배워보자 더보기 확률변수는 입실론이다. 베타0 베타1은 파라미터 모수다. 근데 yi가 확률변수가 된다는 의미는 오차항이 확률변수이기 때문이다. 오차항이 정규분포를 따른다는 것을 가정하고 있다. 베타1의 추정량을 살펴보자. 더보기

단순 선형 회귀분석 - 회귀식 추정 및 결정계수
2020. 4. 9. 18:19
✏️ Mathemathics/Statistics and Probability
점추정 값, 구간추정 값이 있다. 마찬가지로 회귀 식에서도 점추정할 수 있고 구간 추정할 수 있다. 그러려면 분산의 개념을 알아야 한다. 오차가 작으면 구간도 작다. 분산이 작을수록 베타1 베타0의 구간이 작게 나타날 것이다. 상세설명 더보기 베타0 베타1 은 파라미터 모수가 된다. 확률변수 yi 가 될수 있는 것은 입실론이다. 입실론은 N(0,분산) 즉 정규분포를 따르고, 따라서 yi가 정규분포를 따른다. 우리는 오차항에 대한 분포를 알아야 yi의 분포도 알 수 있다. 점추정을 할 수 도있고 구간 추정을 할 수도 있다. 오차분산이 작을수록 회귀직선에 더욱 가깝다. 분산이 작을수록 추정하고자하는 베타0와 베타1의 구간도 작게 나타날 것이다. 오차분산은 ^yi와 실제 관측값 yi의 편차를 이용하여 추정한다..

3주차 과제
2020. 4. 2. 12:15
✏️ Mathemathics/Statistics and Probability
최소 제곱법
2020. 3. 25. 10:44
✏️ Mathemathics/Statistics and Probability
최소제곱법은 자료들 사이에서 패턴을 도출해내는데 쓰인다. 아주 직관적이고 간단하기 때문에, 수치해석, 회귀분석 등 다양한 통계학적 접근의 기본이 된다. 다음 그래프를 보자, 각 자료가 흩뿌려져 있는데, 이 점 들 사이에 일관성을 찾기 위해 그래프 f(x)를 도출한다고 가정하자. 각 점들과 그래프 간의 차이를 residual이라고 한다. 그래프는 가장 오차가 적어야 한다. 오차가 적어야 하다는 것은 각 점들과 그래프 간의 오차가 가장 최소가 되는 f(x)를 찾아야한다는 것을 의미한다. 수식으로 나타내면 아래와 같다. 변수 x와 상수 B가 주어졌을 때, 식은 다음과 같다. f(x)는 선형인 일차 함수로 가정을 한다. x와 y는 주어지는 값이니, residual의 최소값은 기울기 a와 절편 b로 결정된다. 각..
p-value
2020. 3. 23. 22:34
✏️ Mathemathics/Statistics and Probability
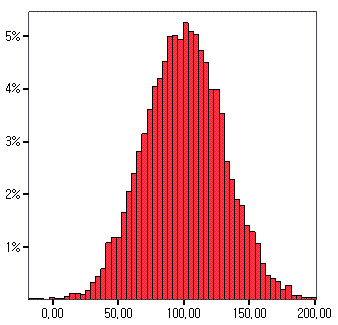
p-value는, 귀무가설(null hypothesis, H0)이 맞다는 전제 하에, 통계값(statistics)이 실제로 관측된 값 이상일 확률을 의미한다. 일반적으로 p-value는 어떤 가설을 전제로, 그 가설이 맞는다는 가정 하에, 내가 현재 구한 통계값이 얼마나 자주 나올 것인가, 를 의미한다고 할 수 있다. p-value는 가설검정이라는 것이 전체 데이터를 갖고 하는 것이 아닌 sampling 된 데이터를 갖고 하는 것이기 때문에 필요하게 되는데, 다음과 같은 경우를 살펴 보자. 다음과 같이 모분포가 10,000 개의 값으로 되어 있다고 하자. 위 모분포의 평균은 100.3023 이다. 가설 검증이라는 것은 모분포를 전부 검증할 수 없기 때문에 모분포에서 일부만 추출하여(그렇게 추출된 것을 s..
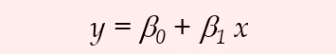
단순 선형 회귀분석
2020. 3. 23. 13:52
✏️ Mathemathics/Statistics and Probability
어느 화학자가 온도에 따른 화학물질의 반응속도를 예측하고자 한다. 그러면 온도(x)와 속도(y)를 나타내는 두 변수에 의해 표현되는 함수 관계를 얻을 수 있다. 이때, 화학반응물의 속도와 상품의 판매량에 영향을 미치는 변수를 독립변수(independent variable) 또는 설명변수(explanatory variable)이라고 한다. 그리고 속도와 판매량을 나타내는 변수와 같이 독립변수의 변화에 영향을 받는 변수를 종속변수(dependent variable) 또는 반응변수(response variable)라고 한다. x : 독립변수, 설명변수, 입력변수 y : 종속변수, 반응변수, 출력변수 독립변수와 종속변수 사이의 관계를 통계적으로 분석하는 방법을 회귀분석(regression analysis)라 한..
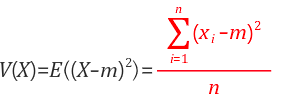
왜 n-1로 나누는가?
2020. 3. 17. 20:39
✏️ Mathemathics/Statistics and Probability
모집단의 분산 모집단에서 표본은 뽑았다. 이 표본의 분산을 구할 때는 n이 아닌 n-1로 나눠준다. 그 이유에 대해 알아보자 불편추정량 때문이고, 결과적으로는 자유도와 연결된다. 면저 용어 설명부터 가자. 자유도는 독립변수의 개수를 의미한다. 예를 들어 x + y + z = 3 이라는 방정식이 있을 때, 독립변수가 3개 인 것처럼 보이지만 실제로는 그렇지 않다. x, y가 1과 0으로 결정되었다면 z = 2를 갖게 된다. z는 종속변수인 것이다. 따라서 이 방정식의 독립변수는 2개이고 자유도는 2가 된다. 이번에는 불편추정량에 대해 알아보자. 불편추정량의 '편'이란 글자는 '편의'이다. 영어로는 bias이다. 불편추정량은 '편의가 없는 추정량' 이라는 뜻이다. 이제 '편의'가 무슨 의미인지 알아야 한다...

감마 분포 (Gamma Distribution)
2020. 3. 17. 20:26
✏️ Mathemathics/Statistics and Probability
번개를 한번 맞을 때까지의 시간이 지수분포라면 번개를 n 번 맞을 때까지의 시간은 감마분포이다. 따라서 지수분포는 감마분포의 한 종류이다. n = 1 이면 지수분포 n > 1 이면 감마분포 알파 = 발생 횟수 베타 = 1회 발생 간격 지수분포의 합이 곧 감마분포다 라고 이해해라

지수분포 (Exponential Distribution)
2020. 3. 16. 17:19
✏️ Mathemathics/Statistics and Probability
기하분포의 개념을 연속적으로 가져간 것이 지수분포이다. 지수분포는 첫번째 사고가 발생할 때까지 걸린 시간에 대한 확률분포이다. 통계에서 대문자가 의미하는 것은 확률변수이다. 소문자는 그 확률변수가 갖는 값이다. T>t는 사고가 발생하지 않았다는 것이다. 건수 = 0이다 F(t)에서 확률밀도함수(누적분포함수) 구하기 : F(t) 미분하기 지수분포는 어떤 사건에 대한 발생을 알기 때문에 굉장히 중요하다. 포아송분포를 거꾸로 하면 지수분포가 나온다. 엄밀히 말하면 기하 분포는 n번의 실패중에 첫번째 성공할 확률이고 지수 분포는 기하분포의 시간버젼이다. 처음에 크다가 점점 작아지는 분포 1년에 평균 4회정도 발생한다. 1년에 1/4년이니까 3개월에 한번씩 발생한다는 것을 알 수 있다. 1개월 이내에 발생할 확률..

균등 분포 (Uniform Distribution)
2020. 3. 16. 16:10
✏️ Mathemathics/Statistics and Probability
밀도함수의 면적은 곧 확률이다. 밀도함수의 면적을 적분 = 면적 = 확률 분포함수 는 항상 누적이란 말을 앞에 생략해 놓는다 : 누적분포함수 (x-1)/4은 x까지의 누적 확률이다. 참 쉽죠?