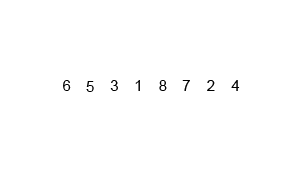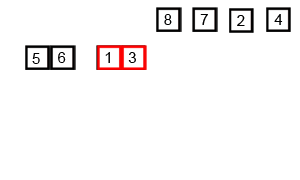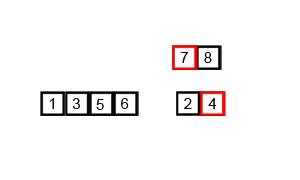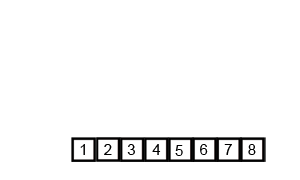
병합 정렬 (Merge sort)
재귀용법을 활용한 정렬 알고리즘
- 리스트를 절반으로 잘라 비슷한 크기의 두 부분 리스트로 나눈다.
- 각 부분 리스트를 재귀적으로 합병 정렬을 이용해 정렬한다.
- 두 부분 리스트를 다시 하나의 정렬된 리스트로 합병한다.
알고리즘 이해
데이터가 네 개 일때 (데이터 갯수에 따라 복잡도가 떨어지는 것은 아니므로, 네 개로 바로 로직을 이해해보자.)
예: data_list = [1, 9, 3, 2]
- 먼저 [1, 9], [3, 2] 로 나누고
- 다시 앞 부분은 [1], [9] 로 나누고, 자를게 없어지면 다시 합병한다.
- 다시 정렬해서 합친다. [1, 9]
- 다음 [3, 2] 는 [3], [2] 로 나누고
- 다시 정렬해서 합친다 [2, 3]
- 이제 [1, 9] 와 [2, 3]을 합친다.
- 1 < 2 이니 [1]
- 9 > 2 이니 [1, 2]
- 9 > 3 이니 [1, 2, 3]
- 9 밖에 없으니, [1, 2, 3, 9]
알고리즘 구현
mergesplit() 함수 만들기

- 만약 리스트 갯수가 한개이면 해당 값 리턴
- 그렇지 않으면, 리스트를 앞뒤, 두 개로 나누기
- left = mergesplit(앞)
- right = mergesplit(뒤)
- merge(left, right)
merge() 함수 만들기
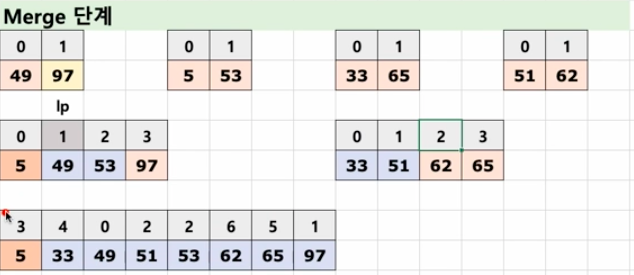
- 리스트 변수 하나 만들기 (sorted)
- left_index, right_index = 0
- while left_index < len(left) or right_index < len(right):
- 만약 left_index 나 right_index 가 이미 left 또는 right 리스트를 다 순회했다면, 그 반대쪽 데이터를 그대로 넣고, 해당 인덱스 1 증가
- if left[left_index] < right[right_index]:
- sorted.append(left[left_index])
- left_index += 1
- else:
- sorted.append(right[right_index])
- right_index += 1
- 만약 left_index 나 right_index 가 이미 left 또는 right 리스트를 다 순회했다면, 그 반대쪽 데이터를 그대로 넣고, 해당 인덱스 1 증가


2등분 하는 함수
def split(data):
medium = int(len(data)/2))
left = data[:medium]
right = data[medium:]
재귀용법 활용하는 mergesplit() 함수
def mergesplit(data):
if len(data) <= 1:
return data
medium = int(len(data)/2)
left = mergesplit(data[:medium]) # 재귀적으로 계속 나눈다.
right = mergesplit(data[medium:]) # 갯수가 2개 이상이라면
return merge(left, right) # 병합
merge() 함수
인덱스 번호로 비교한다.
def merge(left, right):
merged = list() # 새로 만들 리스트 공간
left_point, right_point = 0, 0 # 가리킬 인덱스 번호
# case1 : left, right가 남아있을 때
while len(left) > left_point and len(right) > right_point:
if left[left_point] > right[right_point]:
merged.append(right[right_point])
right_point += 1
else:
merged.append(left[left_point])
left_point += 1
# case2 : left 만 남아있을 때
while len(left) > left_point:
merged.append(left[left_point])
left_point += 1
# case3 : right 만 남아있을 때
while len(right) > right_point:
merged.append(right[right_point])
right_point += 1
return merged
최종 코드
def mergesplit(data):
if len(data) <= 1:
return data
medium = int(len(data)/2)
left = mergesplit(data[:medium]) # 재귀적으로 계속 나눈다.
right = mergesplit(data[medium:]) # 갯수가 2개 이상이라면
return merge(left, right) # 병합
def merge(left, right):
merged = list() # 새로 만들 리스트 공간
left_point, right_point = 0, 0 # 가리킬 인덱스 번호
# case1 : left, right가 남아있을 때
while len(left) > left_point and len(right) > right_point:
if left[left_point] > right[right_point]:
merged.append(right[right_point])
right_point += 1
else:
merged.append(left[left_point])
left_point += 1
# case2 : left 만 남아있을 때
while len(left) > left_point:
merged.append(left[left_point])
left_point += 1
# case3 : right 만 남아있을 때
while len(right) > right_point:
merged.append(right[right_point])
right_point += 1
return merged
import random
data_list = random.sample(range(100), 10)
mergesplit(data_list)
>> [8, 12, 24, 40, 47, 70, 81, 87, 92, 96]알고리즘 분석
몇 단계 깊이까지 만들어지는지를 depth 라고 하고 i로 놓자.
맨 위 단계는 0으로 놓자.
- 다음 그림에서 n/2^2 는 2단계 깊이라고 해보자.
- 각 단계에 있는 하나의 노드 안의 리스트 길이는 n/2^2 가 된다.
- 각 단계에는 2^𝑖 개의 노드가 있다.
따라서, 각 단계는 항상 2^𝑖 ∗ (𝑛/2^𝑖) = 𝑂(𝑛)
단계는 항상 𝑙𝑜𝑔 𝑛개 만큼 만들어진다.
시간 복잡도는 결국 O(log n)
따라서, 단계별 시간 복잡도 O(n) * O(log n) = O(n log n)

'🕶 Algorithm > 알고리즘' 카테고리의 다른 글
| 이진 탐색 (Binary search) (0) | 2021.08.06 |
|---|---|
| 순차 탐색 (Sequential search) (0) | 2021.08.06 |
| 퀵정렬 (Quick sort) (0) | 2021.07.23 |
| 동적 계획법 (Dynamic Programming)과 분할 정복 (Divide and Conquer) (0) | 2021.07.23 |
| 재귀 (Recursion) (0) | 2021.07.22 |