목차
- 고유값(eigen value)와 고유벡터(eigen vector)에 대해 설명해주세요. 그리고 왜 중요할까요?
- 샘플링(Sampling)과 리샘플링(Resampling)에 대해 설명해주세요. 리샘플링은 무슨 장점이 있을까요?
1. 고유값(eigen value)와 고유벡터(eigen vector)에 대해 설명해주세요. 그리고 왜 중요할까요?
정방행렬 A (n x n) 는 임의의 벡터 x (n x 1) 의 방향과 크기를 변화시킬 수 있다.
수많은 벡터 x 중 어떤 벡터들은 A 행렬에 의해 선형 변환되었을 때에도 원래 벡터와 평행한 경우가 있다.
이렇듯 Ax 가 원래 x 에 상수(람다)를 곱한 것과 같을 때의 x 를 고유 벡터, 람다를 고유값이라 한다.
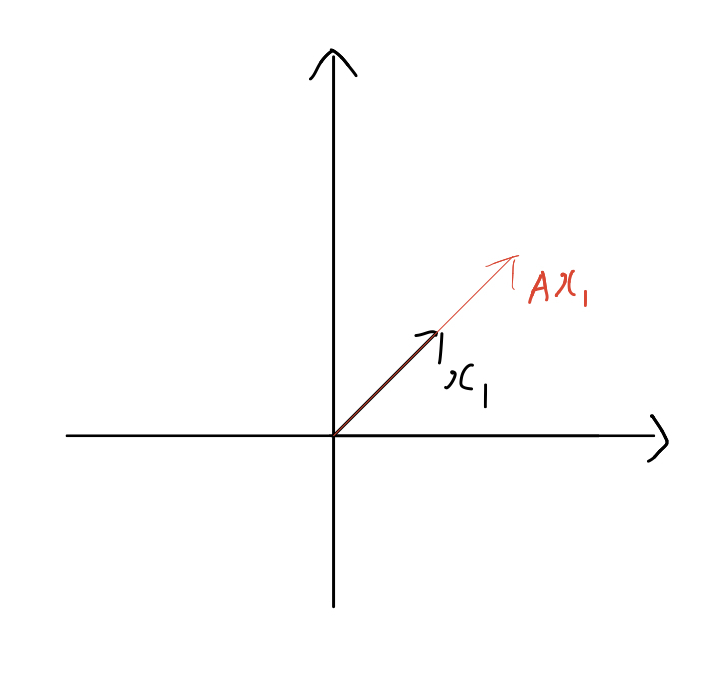
아래처럼 x1 은 A에 의해 변환되었음에도 x1 과 평행하다. 따라서 x1 은 고유벡터이다.
고유값과 고유벡터를 통해 A 를 고유값과 고유벡터들로 분해하는 고유값 분해 (eigen decomposition), 정방행렬 뿐만 아닌 m x n 행렬도 분해할 수 있는 특이값 분해 (SVD), 데이터들을 차원 축소시킬 때 가장 원래 의미를 잘 보존시키는 주성분 분석 (PCA) 등에 활용할 수 있으므로 중요하다.
2. 샘플링(Sampling)과 리샘플링(Resampling)에 대해 설명해주세요. 리샘플링은 무슨 장점이 있을까요?
샘플링이란 표본추출을 의미하는 것으로, 모집단 전체에 대한 추정치(estimate)를 얻기 위해 임의의 sample을 뽑아내는 것이다. 모집단 전체에 대한 조사는 불가능하기 때문에 sample을 이용하여 모집단에 대한 추론(inference)을 하게되는 것이다. 하지만 표본은 모집단을 닮은 모집단의 mirror image 같은 존재이지만, 모집단 그 자체일수는 없다. 따라서 표본에는 반드시 모집단의 원래 패턴에서 놓친 부분, 즉 noise가 존재할 수 밖에 없다.
리샘플링은 모집단의 분포 형태를 알 수 없을 때 주로 사용하는 방법이다. 즉, 모분포를 알 수 없으므로 일반적인 통계적 공식들을 사용하기 힘들 때, 현재 갖고 있는 데이터를 이용하여 모분포와 비슷할 것으로 추정되는 분포를 만들어 보자는 것이다. 리샘플링은 가지고 있는 샘플에서 다시 샘플 부분집합을 뽑아서 통계량의 변동성(variability of statistics)을 확인하는 것이라고 할 수 있다. 즉, 같은 샘플을 여러 번 사용해서 성능을 측정하는 방식이다. 가장 많이 사용되는 방법이며 종류로는 K-fold 교차 검증, 부트스트래핑이 있다.
리샘플링은 표본을 추출하면서 원래 데이터 셋을 복원하기 때문에 이를 통해서 모집단의 분포에 어떤 가정도 필요 없이 표본만으로 추론이 가능하다는 장점이 있다.
'✏️ Mathemathics > Statistics and Probability' 카테고리의 다른 글
| 나이브 베이즈 분류기 (0) | 2021.05.29 |
|---|---|
| 베이즈 정리의 의미 (0) | 2021.05.29 |
| 최대우도법 (0) | 2021.05.29 |
| 사전 확률과 사후 확률 (1) | 2021.05.29 |
| 단순 선형 회귀분석 - 회귀계수의 가설검정 (0) | 2020.04.09 |