나이브 베이즈 분류기는 각 클래스에 대한 가능도(Likelihood) 비교를 통한 분류이다.
또한 베이즈 정리의 철학을 기반으로 작동하는 분류기이다.
베이즈 정리 : 확률을 갱신해 나가는 정리
사전 지식을 이용한 분류 : prior
확률적인 배경 지식을 가지고 특별한 추가 정보 없이 어떤 샘플을 분류하는 예시를 생각해보자.
가령 아무 사람이나 데리고 와서 어떤 정보도 없이 이 사람이 남자인지 여자인지 분류하라고 하면 어떻게 생각할 수 있을까?
세상에 절반은 남자고, 절반은 여자라고 생각한다면 50% 확률로 어림짐작 할 수 밖에 없다.
아마 랜덤하게 두 성별 중 하나를 얘기할 수 밖에 없을 것이다.
이것이 사전적인 정보만으로 어림짐작을 하는 방법이다.
그런데, 가령 삼색이 고양이를 데리고 와서 고양이의 성별이 암컷인지 수컷인지 물어본다고 하자.
자세한 이유는 몰라도, 삼색이 고양이는 성염색체와 관련된 이유로 거의 대부분이 암컷이라고 알려져있다.
그렇다면, 삼색이 고양이를 봤다고 하면 높은 확률로 암컷이라고 생각하지 않을까?
이렇게 사전 확률을 참고할 수 밖에 없다.
하지만, 실제로 어떤 데이터를 분류한다고 할 때에는 최소한의 판단 근거가 될만한 데이터를 제공하지 않을까?
특정 정보가 추가되는 경우: likelihood
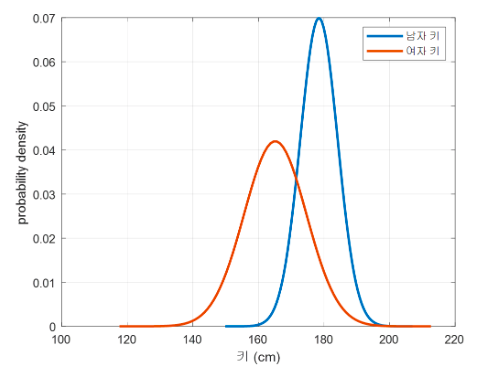
키(즉, 특정 정보)에 따라 이 사람이 남자인지, 여자인지 판별하는 문제에 맞딱드렸다고 생각해보자.
우리는 주어진 training sample들을 통해 다음과 같이 남자와 여자의 키 분포가 다르다는 것을 알고 있다고 해보자.
(이러한 분포 모델링은 정규 분포를 가정하는 경우 training sample들의 평균과 분산을 계산함으로써 쉽게 구축할 수 있다.)
이 때, 우리가 분류하고자 하는 사람의 키가 가령 175cm라고 해보자.
그러면 175 cm에 대해 우리가 구축해놓은 확률밀도함수의 분포는 뭐라 말할까?

정보를 얻게 되면 그것을 Likelihood 라고 한다.
미리 얻어둔 분포를 가지고 얻는다.
그러나 Likelihood만 가지고 판단하기는 어렵다.
사전지식에 추가적인 정보(Likelihood)를 얹어주는 방식으로 계산하는 것이 더 바람직하다. 함께 이용하는 것이다.
남자라고 판단했을 때의 키가 175cm일 likelihood는 다음과 같이 쓸 수 있다.
반면, 여자라고 판단했을 때 키가 175cm일 likelihood는 다음과 같이 쓸 수 있다.
이번 예시에서는 식(1)과 식(2)의 두 likelihood의 값이 다음과 같다는 것 또한 알 수 있었다.

몸무게 정보까지 추가되면 또 사전정보에 Likelihood를 곱해주면 된다.
순진하게 계속 곱해주므로 Naive Bayes Rule 이라고 한다.

Ref : https://angeloyeo.github.io/2020/08/04/naive_bayes.html#시작하기에-앞서
'✏️ Mathemathics > Statistics and Probability' 카테고리의 다른 글
| Statistics/Math - interview (0) | 2022.03.23 |
|---|---|
| 베이즈 정리의 의미 (0) | 2021.05.29 |
| 최대우도법 (0) | 2021.05.29 |
| 사전 확률과 사후 확률 (1) | 2021.05.29 |
| 단순 선형 회귀분석 - 회귀계수의 가설검정 (0) | 2020.04.09 |