ML - interview
2022. 4. 11. 09:11
💡 AI/ML
목차 알고 있는 metric에 대해 설명해주세요. (ex. RMSE, MAE, recall, precision ...) 정규화를 왜 해야할까요? 정규화의 방법은 무엇이 있나요? Local Minima와 Global Minima에 대해 설명해주세요. 차원의 저주에 대해 설명해주세요. Dimension reduction 기법으로 보통 어떤 것들이 있나요? PCA는 차원 축소 기법이면서, 데이터 압출 기법이기도 하고, 노이즈 제거 기법이기도 합니다. 왜 그런지 설명 해주실 수 있나요? PCA, LSA, LDA, SVD 등의 약자들이 어떤 뜻이고 서로 어떤 관계를 가지는지 설명할 수 있나요? Markov Chain을 고등학생에게 설명하려면 어떤 방식이 제일 좋을까요? SVM은 왜 반대로 차원을 확장시키는 방식으..
ML - Ensemble Learning
2021. 11. 22. 15:33
💡 AI/ML
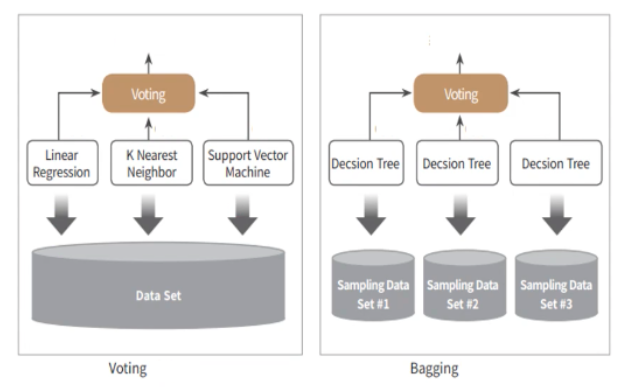
Ensemble Learning Ensemble Learning : 여러 개의 Classifier를 생성하고, 예측을 결합해서, 단일 Classifier보다 정확한 예측 결과를 도출하는 기법 Voting, Bagging, Boosting 으로 구분할 수 있다. + Stacking Bagging : Random forest Boosting : 에이다 부스팅, 그래디언트 부스팅, XGBoost, LightGBM 특징 단일 Classifier의 약점을 다수의 모델들을 결합하여 보완 뛰어난 성능의 모델로만 구성하는 것보단 성능이 떨어지더라도, 서로 다른 유형의 모델을 섞는 것이 나을 수 있다. Voting & Bagging Voting과 Bagging은 여러개의 Classifier가 투표를 통해 최종 예측 결과..
ML - Decision Tree
2021. 11. 21. 15:12
💡 AI/ML
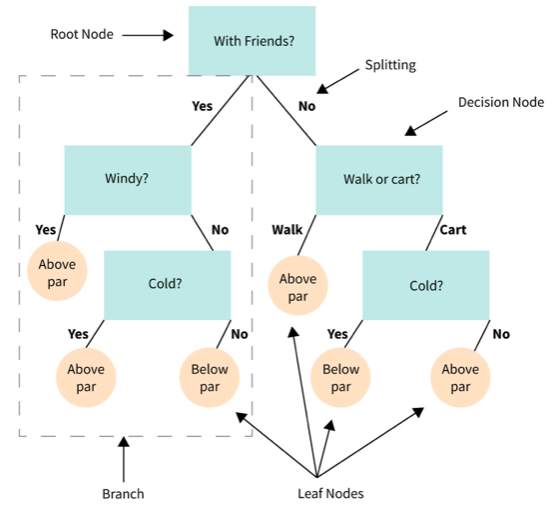
목차 Decision Tree 구조 Decision Tree의 규칙 - 균일도 기반 Information Gain Gini Coefficient (지니 계수) Decision Node 생성 프로세스 Decision Tree의 특징 Decision Tree 주요 하이퍼 파라미터 Graphviz를 통한 시각화 Decision Tree의 Feature 선택 중요도 Classification 나이브 베이즈(Naive Bayes) : 베이즈 통게와 생성 모델에 기반한 나이브 베이즈 로지스틱 회귀(Logistic Regression) : 독립변수와 종속변수의 선형 관계성에 기반한 로지스틱 회귀 결정 트리(Decision Tree) : 데이터 균일도에 따른 규칙 기반의 결정 트리 서포트 벡터 머신(Support Ve..
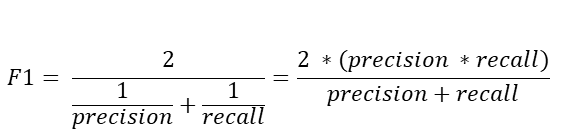
ML - F1 score, ROC-AUC
2021. 11. 19. 19:35
💡 AI/ML
F1 score F1 score는 정밀도와 재현율을 결합한 지표이다. F1 score는 정밀도와 재현율 중 한쪽으로 치우치지 않았을 때 높은 값을 가진다. 사이킷 런은 f1_score() 함수를 제공한다. ROC 곡선, AUC 머신러닝 이진 분류 모델의 예측 성능을 판단하는 지표가 된다. ROC (Receiver Operating Charateristic curve) : FPR을 x축, TPR(재현율)을 y축으로 놓고 그린 그래프 AUC (Area Under Curve) : ROC 곡선의 아래쪽 영역의 면접 = 분류 성능의 지표로 사용된다. p = prediction(predictions, labels) roc = performance(p, measure='tpr', 'x,measure='fpr') au..
ML - Confusion Matrix, Precision, Recall
2021. 11. 18. 15:45
💡 AI/ML
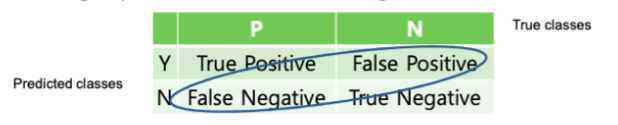
1. Confusion Matrix (오차 행렬) 오차행렬은 이진 분류의 예측 오류가 얼마인지, 어떤 유형의 예측 오류가 발생하고 있는지를 나타내는 지표이다. 예측결과, 예측 True Positive : 참으로 예측했는데, 실제로도 참일 때 = 맞음 False Positive : 참으로 예측했는데, 실제로는 거짓일 때 = 틀림 False Negative : 거짓으로 예측했는데, 실제로는 참일 때 = 틀림 True Negative : 거짓으로 예측했는데, 실제로도 거짓일 때 = 맞음 오차행렬로 예측 결과를 살펴보자. from sklearn.metrics import confusion_matrix # 앞절의 예측 결과인 fakepred와 실제 결과인 y_test의 Confusion Matrix출력 confu..

ML - 평가(evaluation)
2021. 11. 12. 15:25
💡 AI/ML
머신러닝 모델 성능 평가 지표 Accuracy(정확도) 직관적으로 모델 예측 성능을 나타낼 수 있지만, 이진분류의 경우 숫자 놀음이 될 수 있다. (예측 결과랑 동일한 데이터 수) / (전체 예측 데이터 수) Confusion Matrix(오차 행렬) Precision(정밀도) Recall(재현율) F1 score : 정밀도와 재현율이 얼마나 균형 잡혀 있는 지 확인한다. ROC AUC : 이진분류에서 굉장히 많이 사용된다. import numpy as np from sklearn.base import BaseEstimator class MyDummyClassifier(BaseEstimator): # BaseEstimator를 상속받는다. # fit( ) 메소드는 아무것도 학습하지 않음. 원래라면 학습하..
ML - fit(), transform() 과 fit_transform()의 차이
2021. 9. 15. 20:39
💡 AI/ML
사이킷런은 데이터를 변환하는 대부분의 로직에서 fit()과 transform()을 쌍으로 사용합니다. 예를 들어 sklearn.preprocessing의 StandardScaler, MinMaxScaler 나 PCA클래스, 그리고 텍스트의 Feature Vectorization 클래스들(CountVectorizer, TFIDF등) 모드 fit()과 transform()을 같이 이용합니다. 변환만을 생각한다면 fit() , transform()을 함께 사용하지 않고 transform()만 사용하면 될텐데 두개 메소드를 함께 사용하는 이유가 아래와 같이 있을 거라 추정됩니다(이 중 두번째 이유가 중요합니다. ) 사이킷런의 지도학습의 주요 메소드인 fit()과 predict()와 비슷한 API로 사용자들의 보..
ML - Estimator의 fit()과 비지도 학습의 fit()의 차이
2021. 9. 15. 20:31
💡 AI/ML
Estimator 이해 및 fit(), predict() 메서드 사이킷런은 API 일관성과 개발 편의성을 제공하기 위한 노력이 엿보이는 머신러닝 학습에 최적인 패키지입니다. 사이킷런은 머신러닝 모델 학습을 위해서 fit() 메서드와 학습된 모델의 예측을 위해 predict() 메서드를 제공합니다. 사이킷런에서는 분류 알고리즘을 구현한 클래스를 Classifier로, 회귀 알고리즘을 구현한 클래스를 Regressor로 지칭하고, 이 둘을 합쳐 Estimator 클래스라고 부릅니다.(지도학습의 모든 알고리즘을 구현한 클래스를 통칭함) 이 Estimator 클래스는 fit()과 predict()만을 이용해 간단하게 학습과 예측 결과를 반환합니다. Scikit-learn class 구현 클래스 Estimator..
ML - 타이타닉 생존자 예측
2021. 9. 15. 16:15
💡 AI/ML
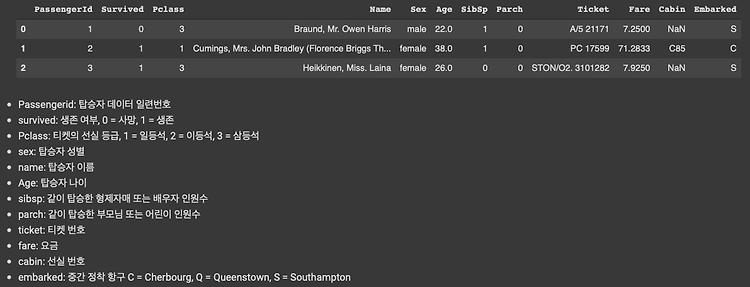
데이터 전처리 Null 처리 불필요한 속성 제거 레이블 인코딩 수행 = 간략하게 하기 위함 모델 학습 및 검증/예측/평가 모델 학습 : 결정트리, 랜덤포레스트, 로지스틱 회귀 학습 비교 검증 평가 : K-fold 교차 검증, cross_val_score(), GridSearchCV() 수행 1.1 데이터 확인 import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline titanic_df = pd.read_csv('./titanic_train.csv') titanic_df.head(3) 분석 시작 전 : 등급(높은 등급 먼저), 성별(여성), 나이(어린아이, 노약자)..
ML - 정규화
2021. 9. 15. 15:34
💡 AI/ML
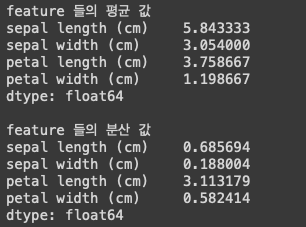
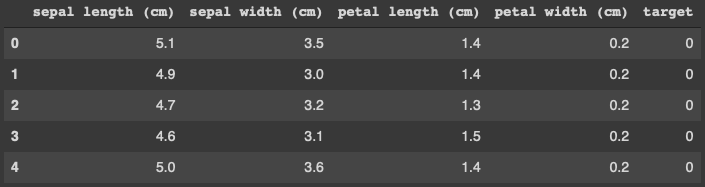
Standardization(표준화) vs Normalization(정규화) 표준화 : 데이터의 피처 각각이 평균이 0이고 분산이 1인 가우시안 정규분포를 가진 값으로 변환하는 것을 의미한다. 정규화 : 서로 다른 피처의 크기를 통일하기 위해 크기를 변환해주는 개념이다. 막 너무 크고 너무 작고 이런걸 편하게 하기 위해서 쓴다. StandardScaler : 평균이 0, 분산이 1인 정규 분포 형태로 변환 MinMaxScaler : 데이터 값을 0과 1 사이 값으로 변환(음수가 있으면 -1에서 1사이 값으로 변환) 1. iris 데이터의 평균, 분산 값 from sklearn.datasets import load_iris import pandas as pd # 붓꽃 데이터 셋을 로딩하고 DataFrame..

ML - 레이블 인코딩, 원핫 인코딩
2021. 9. 15. 15:25
💡 AI/ML
데이터 전처리 (Preprocessing) 머신러닝은 데이터의 영향을 받는다. 쓰레기 값이 들어가면 쓰레기 같은 결과가 나온다. 데이터 클린징 결손값 처리 (Null/NaN 처리) : 결손값이 없어야 한다. 데이터 인코딩 (레이블, 원핫인코딩) : 머신러닝 알고리즘은 숫자형 값만 받아드린다. 데이터 스케일링 : 정규화, 표준화 등 ex) 신장,몸무게 맞춰줄 때 이상치 제거 : 택도 없는 값 제거해주는 것 Feature 선택, 추출 및 가공 : 어떤 Feature들만 선택하면 훨씬 예측 성능이 좋을 수 있다. 1. 레이블 인코딩(Label encoding) 문자열로 들어간 코드 값을 숫자형으로 매핑하는 것 상품 분류가 [TV, 냉장고, 전자렌지] 이렇게 되어있을 때, [0,1,2] 이런식으로 바꿔준다. f..

ML - 교차 검증
2021. 8. 26. 17:06
💡 AI/ML
교차 검증 1. k-fold from sklearn.model_selection import KFold iris = load_iris() features = iris.data label = iris.target dt_clf = DecisionTreeClassifier(random_state=156) # 5개의 폴드 세트로 분리하는 KFold 객체와 폴드 세트별 정확도를 담을 리스트 객체 생성. kfold = KFold(n_splits=5) cv_accuracy = [] n_iter = 0 # KFold객체의 split( ) 호출하면 폴드 별 학습용, 검증용 테스트의 로우 인덱스를 array로 반환 for train_index, test_index in kfold.split(features): # kfol..
ML - 예측 프로세스
2021. 8. 25. 19:58
💡 AI/ML
예측 프로세스 1. 데이터 셋 분리 (train data, test data로 분리) ↓ 2. 모델 학습 (train data 기반 ML 알고리즘을 적용해 모델을 학습) ↓ 3. 예측 수행 (학습된 ML 모델로 test data 예측) ↓ 4. 평가 (예측된 test data의 결과와 실제 test data의 결과 비교 후 성능 평가) Skitlearn Estimator fit() : 학습 predict() : 예측 Classifier (분류) DecisionTreeClassifier RandomForestClassifier GradientBoostingClassifier GaussianNB SVC Regressor (회귀) LinearRegression Ridge Lasso RandomForestReg..

ML - pandas 기본
2021. 8. 24. 17:07
💡 AI/ML
1. 판다스(pandas) 파이썬에서 데이터 처리를 위해 존재하는 가장 인기있는 라이브러리이다. 대부분의 데이터 셋은 2차원이다. 1.1. 판다스의 구성요소 DataFrame : Column x Row 로 구성된 2차원 데이터 셋 Series : 1개의 Column 만으로 구성된 1차원 데이터 셋 Index 1.2. 기본 API read_csv() head() shape info() describe() Value_counts() Sort_values() 1.3. DataFrame의 생성 딕셔너리 형태로 만든다. key 가 컬럼명으로 들어가고, 나머지 value가 나머지 값들로 들어가게 된다. dic1 = {'Name': ['Chulmin', 'Eunkyung','Jinwoong','Soobeom'], '..
ML - 머신러닝과 numpy 기본
2021. 8. 23. 21:26
💡 AI/ML
머신러닝의 개념 머신러닝은 세가지로 나뉜다. 지도학습(Supervised Learning) : 명확한 결정값이 주어진 데이터를 학습 분류 회귀 비지도학습(Un-supervised Learning) : 결정값이 주어지지 않은 데이터를 학습 군집화(클러스터링) 차원 축소 강화학습(Reinforcement Learning) 머신러닝 알고리즘의 유형 기호주의 : 결정트리 연결주의 : 신경망/딥러닝 (심층신경망을 기초로한) 유전 알고리즘 베이지안 통계 (기존의 가설을 새로운 데이터를 받으며 갱신) 유추주의 : KNN, SVM (유사한 것들의 추정) 머신 러닝의 단점 데이터에 의존적이다. 편향된 데이터만 넣으면 편향된 결과만 나온다. 최적의 결과를 도출하기 위한 머신러닝 모델은 실제 환경 데이터에 맞지 않을 수 있..