Standardization(표준화) vs Normalization(정규화)
표준화 : 데이터의 피처 각각이 평균이 0이고 분산이 1인 가우시안 정규분포를 가진 값으로 변환하는 것을 의미한다.
정규화 : 서로 다른 피처의 크기를 통일하기 위해 크기를 변환해주는 개념이다. 막 너무 크고 너무 작고 이런걸 편하게 하기 위해서 쓴다.
StandardScaler : 평균이 0, 분산이 1인 정규 분포 형태로 변환
MinMaxScaler : 데이터 값을 0과 1 사이 값으로 변환(음수가 있으면 -1에서 1사이 값으로 변환)
1. iris 데이터의 평균, 분산 값
from sklearn.datasets import load_iris
import pandas as pd
# 붓꽃 데이터 셋을 로딩하고 DataFrame으로 변환합니다.
iris = load_iris()
iris_data = iris.data
iris_df = pd.DataFrame(data=iris_data, columns=iris.feature_names)
print('feature 들의 평균 값')
print(iris_df.mean())
print('\nfeature 들의 분산 값')
print(iris_df.var())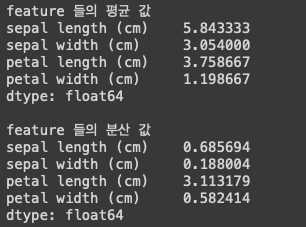
각각의 컬럼들에 대한 평균값과 분산값을 알아 보았다.
2. StandardScaler()
역시나 fit()과 transform()을 이용한다.
from sklearn.preprocessing import StandardScaler
# StandardScaler객체 생성
scaler = StandardScaler()
# StandardScaler 로 데이터 셋 변환. fit( ) 과 transform( ) 호출.
scaler.fit(iris_df)
iris_scaled = scaler.transform(iris_df)
#transform( )시 scale 변환된 데이터 셋이 numpy ndarry로 반환되어 이를 DataFrame으로 변환
iris_df_scaled = pd.DataFrame(data=iris_scaled, columns=iris.feature_names)
print('feature 들의 평균 값')
print(iris_df_scaled.mean())
print('\nfeature 들의 분산 값')
print(iris_df_scaled.var())
평균이 이정도면 그냥 0이다. 분산도 그냥 1이라고 보면 된다.
이처럼 StandardScaler는 각 피쳐들의 컬럼 값을 평균이 0, 분산이 1인 값으로 변경한다.
3. MinMaxScaler()
from sklearn.preprocessing import MinMaxScaler
# MinMaxScaler객체 생성
scaler = MinMaxScaler()
# MinMaxScaler 로 데이터 셋 변환. fit() 과 transform() 호출.
scaler.fit(iris_df)
iris_scaled = scaler.transform(iris_df)
# transform()시 scale 변환된 데이터 셋이 numpy ndarry로 반환되어 이를 DataFrame으로 변환
iris_df_scaled = pd.DataFrame(data=iris_scaled, columns=iris.feature_names)
print('feature들의 최소 값')
print(iris_df_scaled.min())
print('\nfeature들의 최대 값')
print(iris_df_scaled.max())
'💡 AI > ML' 카테고리의 다른 글
| ML - Estimator의 fit()과 비지도 학습의 fit()의 차이 (0) | 2021.09.15 |
|---|---|
| ML - 타이타닉 생존자 예측 (0) | 2021.09.15 |
| ML - 레이블 인코딩, 원핫 인코딩 (0) | 2021.09.15 |
| ML - 교차 검증 (0) | 2021.08.26 |
| ML - 예측 프로세스 (0) | 2021.08.25 |