ML W14 - Representing and Mining Text
2021. 6. 12. 10:48
💡 AI/ML
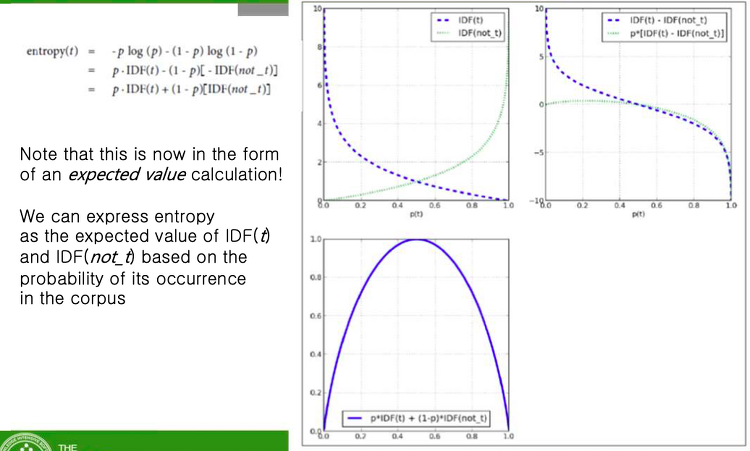
IDF : term이 rare하면 올라가고, term이 보편적이면 값이 떨어진다. 엔트로피가 가장 크게 나타나는 곳은 그래프가 겹칠 때이다. Beyond Bag of words N-gram Sequences 시퀀스를 보호해주는 것 전후좌우 몇개까지 봐줘야 될까? = N개 Named Entity Extraction Topic Models 문서를 요약하는 방법은 키워드이다. 그럴려면 document와 키워드를 연결해주어야 하고 그것을 가능하게 해주는 것이 Topic layer이다. 또한 이러한 모델을 Topic Model 이라고 한다. Topic Models Text Mining Example Problems and Assumptions Mining News Stories to Predict Stock Pr..

ML W13 - Representing and Mining Text
2021. 6. 11. 12:25
💡 AI/ML
Dealing with Text 텍스트의 형태 Why Text is Difficult 문맥 : 앞 뒤 전 후 상황 Text Representation document를 모아놓은 것을 corpus 라고 한다. document 안에는 token 이 있다. token = 그냥 단어 document를 하나의 instance로 본다. “Bag of Words” Bag of words 는 문법이나 순서나 마침표 같은 것을 구분하지 않고 그냥 bag에 넣었을 때 Value는 무엇인가? -> 그 단어가 존재하지 않으면 그 document는 boolean으로 0으로 표현하고 있으면 1로 표현한다. Pre-processing of Text Stop-words : the and of 같은 그렇게 의미 없는 단어들 이것을 찾..

ML W12-2 - Evidence and Probabilities: Prediction via Evidence Combination
2021. 6. 10. 22:26
💡 AI/ML
Evidence and Probabilities 데이터로부터 결론을 낼 적에는 데이터 인스턴스가 우리들한테는 하나의 evidence로 작동하고 있고 얼마나 strong 한지 weak 한지가 중요하다. 통계학적으로 중요한 evidence evidence의 strength를 알 수 있다면 타겟을 결정 지을 수 있다. Example: Targeting Online Consumers with Ads 광고의 효과를 보기 위해서는 인스턴스가 무엇인지 정확히 정의해야 한다. Example: Targeting Online Consumers with Ads Target variable : 고객이 광고를 본 후 그 방을 예약을 할까 안할까 하는 binary value가 있다. Prediction : 얼마나 이 광고에 반응..

ML W12-2 - Visualizing Model Performance
2021. 6. 10. 19:09
💡 AI/ML
나이브 베이즈는 낮은 정확도 였는데 높은 AUC 값이 나왔다. KNN은 Y로 예측 하는데 거의 0%이다. 전혀 못하고 있다. 반면 나이브 베이즈는 굉장히 실수를 많이 한다. 그러나 맞추는 거도 많이 한다. ROC curve 위 그래프를 보면 높은 정확도를 갖는 kNN은 오버피팅 되었다는 것을 알 수 있다. 나이브 베이즈 > Decision 트리 > 선형 회귀 > kNN 순으로 정확도가 높은 것을 확인할 수 있다. 단, 일반화는 하지 말라. 데이터에 따라 다를 수 있다. Lift Curve Lift Curve에서는 x축이 테스트 인스턴스의 비율이다. 영양가 좋은 테스트 인스턴스를 주었을 때 거기에 얼마나 부응하느냐, 얼마나 퍼포먼스가 좋으냐 물어보는 것이다. 아무리 좋은 밥을 줘도 제 성능을 못하는 것은 ..

ML W11-2 - Visualizing Model Performance
2021. 5. 15. 14:45
💡 AI/ML
Profit Curve 모든 컨디션은 불확실하고 안정되어 있지 않다. 따라서 다양한 모델을 만들어봐야 조합해 봐야한다. Tree 썼을 때 가장 큰 profit ROC ROC(Receiver Operating Characteristic) curve는 다양한 threshold에 대한 이진분류기의 성능을 한번에 표시한 것이다. 이진 분류의 성능은 True Positive Rate와 False Positive Rate 두 가지를 이용해서 표현하게 된다. ROC curve를 한 마디로 이야기하자면 ROC 커브는 좌상단에 붙어있는 커브가 더 좋은 분류기를 의미한다고 생각할 수 있다. x축 False Positive, y축 True Positive “Positive”의 의미는 판단자가 “그렇다”라고 판별했다는 의미이..

ML W6-1 Overfitting and Its Avoidance
2021. 4. 5. 13:10
💡 AI/ML
Why Is Overfitting Bad? (p.125) Need for holdout evaluation 어떻게 두개를 나눌 수 있을까? 어떻게 Classifiy 할 수 있을까? 단순하게 나눌려고 하기 때문에, memorizing 하려고 하기 때문에 오버피팅이 생기는 것이다. Over-fitting 점점 노드가 많아질수록 변수가 많아지고 specific한 값들이 나타나면서 오버피팅이 된다. 새로운 데이터들을 기억하게 되면서 오버피팅이 된다. 그러면 어떻게 퍼포먼스를 올릴 수 있을까? -> Holdout Holdout validation 주어진 데이터가 전부이다. 아무 데이터나 합치면 안된다. 데이터의 소스가 다르기 때문이다. Ref: m.blog.naver.com/ckdgus1433/2215995178..

ML W5-2 Overfitting and its Avoidance
2021. 4. 1. 10:19
💡 AI/ML
Model Performance Analytics 교과서 열심히 읽어라 Over-fitting the data unknown한 instance는 overfitting될 가능성이 굉장히 높다. Over-fitting expense of generalization : 너무 두루뭉실 해져버리기 때문에 문제가 된다. generalization을 희생하고 specific한 것을 취하는 방법도 있다. 대다수는 조금씩 오버피팅 하는 경우이다. 열심히 노력하면 패턴을 찾아낼 것이다. 그러나 우리는 좀더 정확히 예측가능한 모델을 원한다. Ex) 테이블 모델이란 것이 있다. Charm problem 에 있는 고객들을 과거데이터에서 찾아내서 feature vector로 모아놨다. 과거데이터를 봤을 때 그 안에서 Charm ..

ML W5-1 Fitting a Model to Data [OO]
2021. 3. 29. 14:39
💡 AI/ML
Support Vector Machines (SVMs) 가장 대표적인 머신러닝 알고리즘 중 하나이다. 선을 중심으로 최대한(두꺼운)의 여백을 만들기 얼마만큼의 두께로 두개의 클래스를 나눌 수 있을까? 보수적인 벡터 여백의 선을 안쪽으로 넘었을 때는 패널티가 부과되고 Loss function을 작동시킨다. 여백의 선 바깥으로 멀어질수록 랭킹이 높아지고 가까울수록 랭킹이 낮아진다. Support Vector Machines (SVMs) Margin을 최대한 크게 하는 것이 SVM의 목표이다. Hinge loss : 잘못 판달 되었을 때 어떤 페널티를 주고 극복해 나갈 것인가 고려해야할 점 1. 복잡도가 높아질수록 일반화하기가 힘들다. 2. 새로운 차원을 도입할 때 기존의 데이터와 새로운 데이터의 상관관계가 ..

ML W4-1-2 Fitting a Model to Data
2021. 3. 22. 17:40
💡 AI/ML
Discriminant Functions 차별화 Fitting a Model to Data 모델에 가장 적합한 Heat map of XYZ Hotels geographic brand affinity Heat maps Tree Complexity and Over-fitting 다양한 문제에 맞는 다양한 알고리즘 중 적절한 모델을 선택하는 것이 중요하다. 그렇지 않으면 overfitting하게 될 가능성이 크다. Trees on Churn Pruning (가지치기) 오버피팅 막고 노이즈도 줄일 수 있다. Post pruning을 더 선호한다. Post-pruning a tree meaningful 한 변수만 남겨놓고 pruning 한다. Decision Boundaries Instance Space Line..

ML W4-1-1 Supervised Segmentation
2021. 3. 22. 14:55
💡 AI/ML
Visualizing Segmentations 데이터를 Age라는 변수로 나눈다. entropy와 Information gain을 기준으로 나눈다. x축 : Age y축 : Balance 어떤식으로 Decision boundary가 결정되었는지 알 수 있다. 여기서 어떻게 바운더리를 설정해야 정확성을 유지할 수 있을까? Geometric interpretation of a model 아무리 잘해도 완벽하지 않다. 의사결정트리 말고 어떤 다른 방법으로 자를 수 있을까? 줄을 하나 그음으로써 Classification이 달라질 수 있다. Trees as Sets of Rules 의사결정 트리는 rule set과 같다. Trees as Sets of Rules What are we predicting? 빨간 ..

ML W3-2-2 - Supervised Segmentation
2021. 3. 18. 13:07
💡 AI/ML
Attribute Selection Example: Attribution Selection with Information Gain 엔트로피를 계산하고 feature selection을 통해서 가지를 만들어 나간다. 가지를 만들어 나가는 기준이 되는 attribute의 엔트로피를 계산한다. 현재 엔트로피가 96%로 굉장히 높고 우리의 목표는 엔트로피를 낮춰서 purity를 높이는 것이다. GILL-COLOR : 주름 이 슬라이드는 과정을 보여주는 슬라이드이다. 우리가 찾아야 되는 것은 엔트로피가 작고 데이터셋의 양도 많은 것이다. odor(냄새)로 segmentation을 만들었다. 냄새가 없는 버섯들이 상당히 있는 것을 볼 수 있다. : n 냄새가 있는 버섯들은 엔트로피가 굉장히 낮다. odor는 의미있..

ML W3-2-1 Supervised Segmentation
2021. 3. 18. 11:21
💡 AI/ML
Supervised Segmentation 의미있는 attribute target과 직접적, 간접적으로 correlate를 가지는 변수를 잘 활용하면 정확한 Classification이 가능하다. 지도학습을 통한 데이터셋의 학습은 target variable과 관계를 갖는 중요한 정보를 찾는 것이다. 얼마만큼 informative 하고, 중요한 정보가 들어있느냐? 고객들을 찾아내고 솎아내고, 차별화 해야한다. 전문직에 있는 사람인지, 나이, 거주지, 수입, 받아온 서비스에 얼만큼 만족했는지에 대한 변수를 알아야 한다. 과거의 데이터를 보니 이러한 관계를 갖는 사람을 보면 떠난다, 떠나지 않는다. 특정 지역에 사는 사람은 꼭 떠나더라, 등 특별한 변수가 존재할 수 있다. 아니면 그런사람과 그렇지 않은 사람..

ML W3-1-2 - Predictive Modeling
2021. 3. 15. 14:53
💡 AI/ML
많은 양의 데이터가 과연 어디에 쓰일지, 질적으로 퀄리티가 얼마나 좋을지 염려가 되기도 한다. 의미있는 정보를 포함하는 target variable를 확보하는 것이 중요하다. 도메인 전문가와 머신러닝 전문가가 같이 소통하면서 일을 하게 된다. 어떤 성향의 고객은 떠나고 어떤 성향의 고객은 떠나지 않았다는 정보들로 레이블을 만들 수도 있다. 문제에 따라서 적절한, 데이터의 종류에 따라서 적절한 테크닉을 사용하는 것이 중요하다. 기계학습의 결과는 우리들의 좋은 의사결정에 쓰인다. 우리가 겪는 데이터는 굉장히 작다. 지식 기반의 프레임워크를 만드는 이유가 이것이기도 하다. 다른 많은 데이터를 고찰을 해봐야한다. 상황이라는 것이 의사결정의 방향을 다르게 할 수 있기 때문이다. Classification : in..