
분자생물학 9장 (2) - 복제분기점, Primase, Helicase, DNA polymerase
2020. 10. 10. 15:52
🧬 Bio/분자생물학
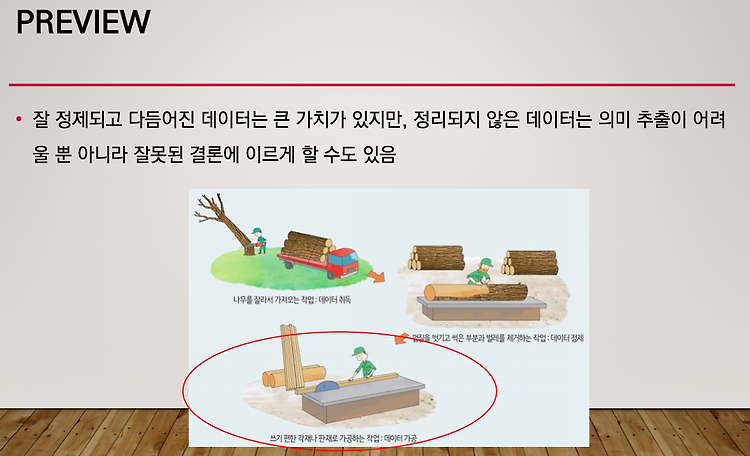
복제분기점 DNA의 두 가닥 모두 복제분기점에서 함께 합성된다. 선도가닥(leading strand)은 한번 시작이 되면 연속적으로 쭉 진행되고 지체가닥(lagging strand)은 조각조각 복제된 다음에 연결된다. 선도가닥이든 지체가닥이든 프라이머가 있어야하고 프라이머를 합성하는 효소가 Primase다. 프라이머는 RNA 조각이다. 왜 DNA를 복제하는데 RNA 조각을 짧게 연결하는가? RNA 중합효소와 복제의 주역인 DNA 중합효소는 차이가 있다. DNA 중합효소의 첫번째 염기부터 시작은 못하지만 RNA 중합효소는 첫번째 염기부터 갖다 놓을 수 있다. (나중에 다시 언급) 새로운 가닥을 주형으로 작용하게 되면 상보적인 새로운 가닥이 생겨나게 된다. 기존의 부모가닥이 벌어지는 부분이 있다. 그곳이 바..

R (9) - 데이터 시각화, 상관관계, legend, matplot, treetop
2020. 10. 7. 18:18
📌 R
거의 비슷한 데이터처럼 보인다. 거의다 유사한 데이터인 것 같았는데 시각화 해보니 다르게 보였다. 가시화를 왜 해야 하는지 보여주는 데이터이다. 단순하게 그림으로 본다 이런게 아니라 데이터의 신뢰성을 상승시키는 작업이 데이터 시각화이다. x좌표는 연도 y 좌표는 합산된 값 사용자 입장에서는 이 그래프는 무엇을 말하는지 모를 수 있다. 색깔이 다 똑같기 때문에 그래서 하나하나 옵션을 집어넣어 보자. col = y$continent : 대륙끼리는 다른 색깔로 칠해달라 모양을 바꿔보자. pch pch = 몇 ## 으로 하면 하나의 모양으로 바뀐다. pch = c(1:5) # 5개의 모양으로 pch = c(1:length(levels(y$continent))) # 만약 5개로 끝나지 않고 계속 바뀔거 같으면 l..
R (8) - 데이터 가공, apply(), select(), filter(), group_by(), summaries()
2020. 10. 4. 21:17
📌 R
크로아티아만 뽑고 싶다? 조건식을 넣어서 추출하면 된다. apply() : 연산 DPLYR 라이브러리 dplyr 팩키지가 데이터프레임을 솜씨있게 조작하는데 유용한 많은 함수를 제공한다. 이를 통해서, 위에서 언급된 반복을 줄이고, 실수를 범할 확률도 줄이고, 심지어 타이핑하는 수고도 줄일 수 있다. 보너스로, dplyr 문법은 훨씬 더 가독성도 높다. select() 데이터 프레임에서 변수 일부만 뽑아서 작업하고자 할 때 select()를 쓴다. filter() 꼬박꼬박 쓰지 않아도 돼서 간편하다. year_country_gdp_euro % filter(continent=="Europe") %>% select(year,country,gdpPercap) gapminder 데이터프레임을 filter() 함수..

분자생물학 9장 (1) - DNA 복제
2020. 10. 4. 17:52
🧬 Bio/분자생물학
9장 DNA 복제 DNA 복제 3요소 DNA 합성에는 디옥시뉴클레오티드 3인산과 프라이머, 주형가닥이 필요하다. a. 가장 안쪽 인산기가 알파-인산, 바깥쪽 인산기가 감마-인산이다. b. 주형가닥의 원본, 주형과 짝을 이룬 프라이머(시발체), 디옥시뉴클레오티드 DNA는 프라이머 3' 말단의 신장에 의해 합성된다. OH는 음전기적인 특정이 있어서 양전기적인 특성을 지닌 인산기를 붙일 수 있다. 2인산이 날아가면서 고에너지인산결합이 쓰이고 이것이 화학반응의 원동력이다. DNA 중합효소는 DNA 합성을 촉매하기 위해 단일 활성 부위를 이용한다. DNA 중합효소는 단일 활성부위를 가지고 4종류의 디옥시뉴클레오티드 삼인산의 어느 것이 첨가되든지 그 반응을 촉매한다. DNA 중합효소가 이렇게 촉매적 유연성을 가지는..

분자생물학 8장 (2)
2020. 9. 25. 11:59
🧬 Bio/분자생물학
다수의 DNA 염기서열 비의존적인 접촉이 히스톤 중심과 DNA 사이의 결합을 유도한다. 히스톤 아미노 말단 꼬리는 DNA가 8량체 주위를 에워싸는 것을 안정화 한다. N말단은 바깥에 있으면서 뉴클레오솜을 감쌀 수 있어서 안정화에 기여한다. 히스톤 단백질 중심을 둘러싸고 있는 DNA는 음성의 초나선 구조를 가진다. 손상이 없는 cccDNA : 환형, 두가닥 완벽한 왓슨크릭의 나선 꼬임, 어느 부위도 끊어지지 않는 DNA 히스톤 복합체를 집어넣어서 염색체가 형성되도록 만든다. 인당 backbone을 끊는게 아니라 음성초나선으로 감게 되면 끊지 않는 상태에서 초나선을 만들어서 L값이 변하지 않는다. 이 그림을 통해서 음성초나선을 생체에서 형성한다는 것을 알 수 있다. 그림 잘보기 Topoisomerase를 통..

분자생물학 8장 - 유전체 구조, 염색질 그리고 뉴클레오솜
2020. 9. 25. 11:19
🧬 Bio/분자생물학
유전체 구조 염색질(Chromatin) : DNA + 단백질 결합체 히스톤 : 결합단백질 비히스톤 : DNA 복제, 전사 담당 뉴클레오솜 : DNA + 히스톤 염색체는 원형 혹은 선형일 수 있다. Topoisomerase : 원형 염색체가 복제된 후 딸 분자를 분리하는 역할 모든 세포는 특정수의 염색체를 가진다. 원핵세포는 핵양체(nucleoid)라는 염색체를 가지고 있다. 플라스미드를 가지고 있기도 하다. 핵양체 : 핵과 유사한 물체 진핵세포는 이배체(diploid)이며 주어진 염색체의 두 복사체를 상동체(homolog) 라고 한다. 진핵세포는 내부공간을 나누어 놨다. 유전체의 크기는 생물의 복잡성과 연관되어 있다. 1. 비암화서열은 바로 뒤의 암호화부위의 전사조절부위로 작용한다. Ex) 프로모터 2...
R (7) - 산점도, 상관분석, 선그래프
2020. 9. 24. 13:51
📌 R
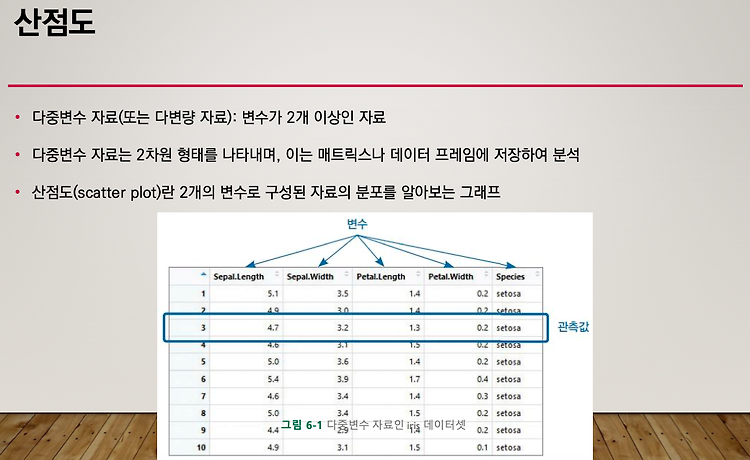
산점도 : plot() 두개의 변수로 구성된 자료의 분포를 알아보는 그래프 pch 번호 두 변수 사이의 관련성을 확인하는데에 산점도가 쓰인다. 여러 변수들 간의 산점도 : pairs() 4개 중 2개씩 짝지어 지므로 다양한 산점도가 나타난다. 대각선을 기준으로 대칭되는 특징이 있다. 속성값이 많을 때에는 다중 산점도로 표현할 수 있다. 그룹 정보가 있는 두 변수의 산점도 : plot() 꽃잎의 길이와 폭의 상관관계를 알 수 있다. 관측값의 비교 뿐만 아니라 그룹간의 관계도 알 수 있다. 상관분석 : cor() r이 1이면 거의 선의 모양 r이 0.5이면 선형성이 있긴 하지만 약간 분포가 되어 있다. 약한 선형성을 가진다. r이 0인 경우엔 선형성의 거의 없다라고 판단할 수 있다. cor() : 두 변수 ..

R (6) - 자료의 종류, table, barplot, pie, quantile, hist, boxplot
2020. 9. 23. 22:19
📌 R
범주형 자료 연속형 자료 단일변수 자료 & 다중변수 자료 벡터는 여러개의 변수를 사용할 수 없기 때문에 단일변수 자료는 벡터에 넣는다. 크기를 측정할 수 없는 자료 : 범주형 자료 도수분포표 : table() 막대그래프 : barplot() 원 그래프 : pie() 자료값의 이름을 colors로 바꾼다. col = colors 라고 하면 실제로도 색깔을 지정하게 된다. 평균과 중앙값 사분위 수 : quantile() 사분위 수 : 4등분 하는 지점의 값 제2 사분위 수 : 중앙값 3개를 기준으로 판단하기 때문에 더 많은 정보를 얻을 수 있다. 산포 분산고 표준편차가 작으면 자료의 관측값이 평균값 부근에 많이 모여있다는 뜻 range() : 자료값의 범위를 알려준다. diff(range()) : 어느정도의..

R (5) - if else, 반복문, 결측값, 이상값
2020. 9. 22. 22:12
📌 R
데이터 프레임의 경우 행과 열의 조건을 모두 표기할 수 있어서 쉼표로 나타낸다. 벡터는 그럴 수가 없어서 일렬로 나타낸다. if 문 파이썬은 들여쓰기로 파악하지만 R은 괄호로 파악한다. ifelse 문 warning message : 실행은 됐는데 에러는 아니지만 확인해보아라. if (){ } else { } 이런식으로 if문의 } 가 끝나는 라인에 else를 붙여줘야한다. 반복문 repeat 문 계속 반복되기 때문에 break를 걸어줘야 한다. while 문 for 문 함수 데이터 정제 : 결측값 처리 is.na 로 TRUE 값이 44가 나왔으므로 NA 값이 44개 라는 뜻이다. TRUE 값이 나오지 않았다면 NA 값이 존재하지 않는 것이다. 평균 값이 달라졌는데 na.omit으로 na가 있는 모든 열..
R (4) - 엑셀, csv, txt 파일 가져오기, 데이터 추출, 조건문
2020. 9. 15. 15:58
📌 R
리스트는 숫자와 문자를 같이 넣을 수 있다 = 다중형 R studio 엑셀파일 가져오기 : read_excel() R studio 메뉴로 .txt 파일 가져오기, .csv 파일, 엑셀 파일 가져오기 R studio .rda 파일로 저장하고 불러오기 저장하기 : save(데이터 셋, file = "파일명") 불러오기 : load("경로/파일명") Rstudio .csv 또는 .txt 파일로 저장하기 write.table(데이터셋, file = "경로/파일명") 쉼표로 구분된 .txt 파일 가져오기, 변수명을 추가하여 가져오기 쉼표로 구분 : read.table("경로/파일명", header=TRUE, sep=",") 변수명 추가 : read.table("경로/파일명", sep=",", col.names=v..

R (3) - 배열, 매트릭스, 데이터프레임, 리스트, 팩터
2020. 9. 14. 18:36
📌 R
매트릭스(matrix) : 모든 셀의 자료형이 동일한 컬럼들로 구성 데이터프레임(data frame) : 자료형이 다른 컬럼들로 구성 한칸 = 셀 matrix(매트릭스에 저장될 값, nrow = 행의 수, ncol = 열의 수) matrix(매트릭스에 저장될 값, nrow = 행의 수, ncol = 열의 수, byrow=T) 행의 방향으로 값을 대입한다. cbind() : 열방향 결합 rbind() : 행방향 결합 cbind(x,y) : 열들로 만들어서 결합하여 매트릭스 생성 rbind(x,y) : 행들로 만들어서 결합하여 매트릭스 생성 인덱스값을 이용하여 매트릭스에서의 값 추출하기 매트릭스에서 여러개의 값을 추출하기 매트릭스의 행과 열에 이름을 지정하기 데이터 프레임 표 형태의 데이터구조이다. 행렬과 ..

분자생물학 4장 - DNA 입체구조 (2)
2020. 9. 11. 13:17
🧬 Bio/분자생물학
수소결합과 소수성 인력은 서로 상호 협력적이다. 이중나선구조가 유지되려면 양전기적인 요소가 있어야 이중나선 주변이 전기적으로 중성이 되고 두 사이의 거리가 가까워져서 수소결합이 이루어질 수 있다. 진핵세포의 경우 히스톤단백질이 음전하를 상쇄시켜준다. 양쪽가닥에 존재하는 염기들 사이에서 상쇄되므로 두가닥이 묶이게 된다. 안쪽으로 모여서 차곡차고 쌓여야 정렬이되고 수소결합이 가능하게 된다. Base stacking 인력은 상호 협력적이다. 만약 수소결합을 끊으면 더 이상 마주보아야할 이유가 없으므로 구조가 무너지게 된다. 수소결합과 소수성결합은 상호 협력적이다. 또한 수소결합끼리에도 상호 협력적이고 소수성결합끼리도 상호협력적이다. 위에서 A와 T가 수소결합이 되어있으면 그 밑에 수소결합도 위가 결합되어 있으..

python - 이상형이 뭐에요?
2020. 9. 9. 22:59
📌 Python
파이썬에서는 모든 함수를 def 라고 만들고 한줄 들여쓴 상태로 시작한다. 다시 한번 강조하지만 어디서 함수가 시작하고 끝나는지 구분하기 위해선 꼭 들여쓰기를 해줘야한다. def make_dolcelatte(): print("1. 얼음을 넣는다.") print("2. 연유를 30ml 넣는다.") print("3. 찬 우유를 넣는다.") print("4. 에스프레소샷을 넣는다.") def make_blueberry_smoothie(): # 괄호와 콜론을 꼭 써야한다 print("1. 블루베리 20g을 넣는다.") print("2. 유유를 300ml 넣는다.") print("3. 얼음을 넣는다.") print("4. 믹서기에 간다.") def make_simple_latte(): print("1. 커피를 넣..
python - 리스트, 딕셔너리, 집합
2020. 9. 9. 21:55
📌 Python
리스트, 딕셔너리 for x in range(30): print(x) foods = ["된장찌개", "피자", "제육볶음"] for x in range(3): print(foods[x]) for x in foods: print(x) information = {"고향":"수원", "취미":"영화관람", "좋아하는 음식":"국수"} for x, y in information.items(): print(x) print(y) 30개의 수를 >> x 안에 넣고 >> 30번 반복한다. food를 >> x 안에 넣고 >> 하나씩 반복한다. 딕셔너리는 Key와 Value, 총 2개이므로 x,y 라는 2개의 변수에 넣어야 한다. 그리고 .items() 를 추가해 준다. 집합 리스트는 각 리스트마다 순서가 있다. 그러나 ..