


거의 비슷한 데이터처럼 보인다.
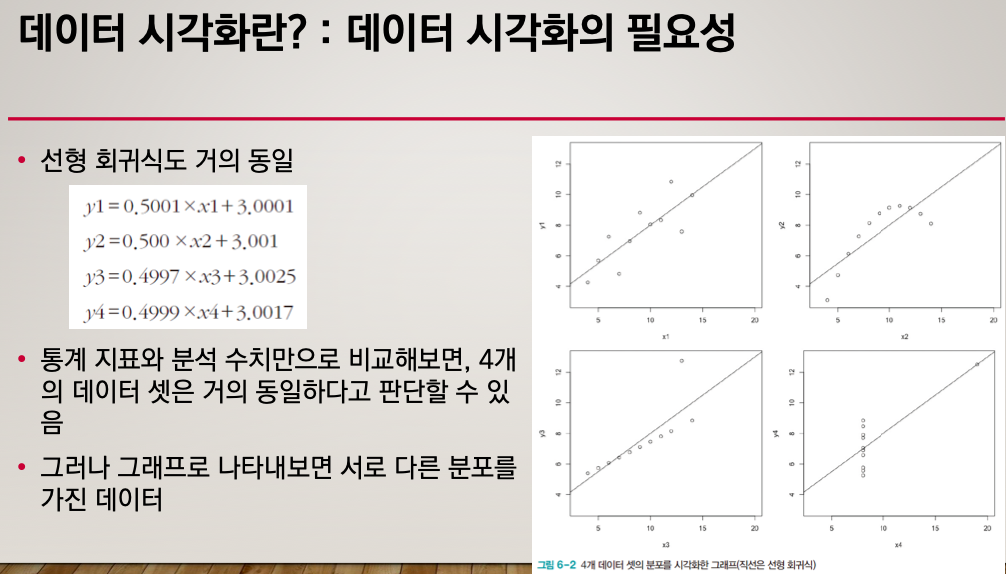
거의다 유사한 데이터인 것 같았는데 시각화 해보니 다르게 보였다.
가시화를 왜 해야 하는지 보여주는 데이터이다.
단순하게 그림으로 본다 이런게 아니라 데이터의 신뢰성을 상승시키는 작업이 데이터 시각화이다.

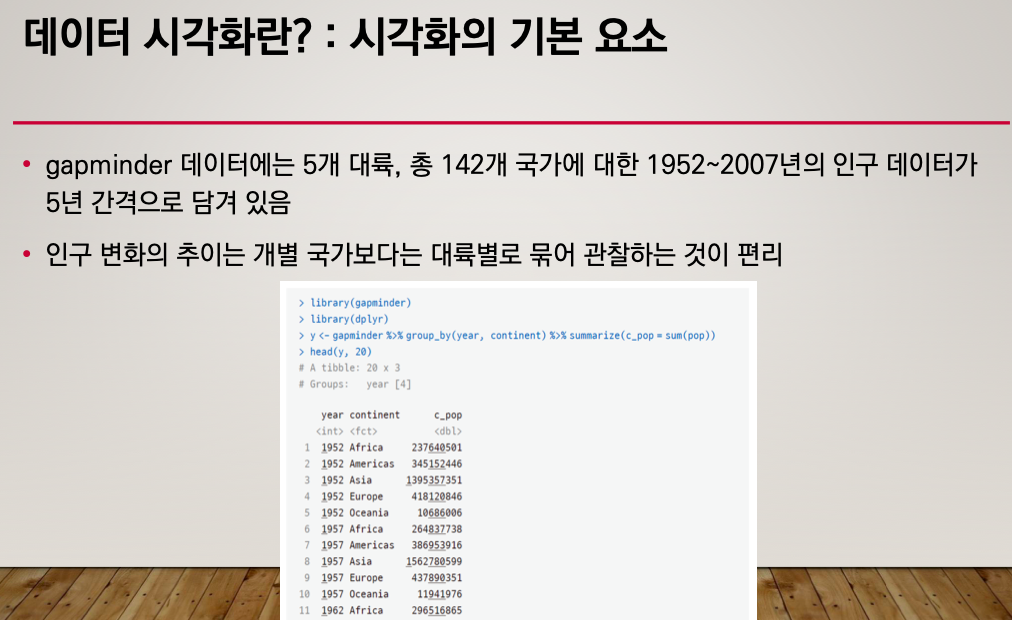
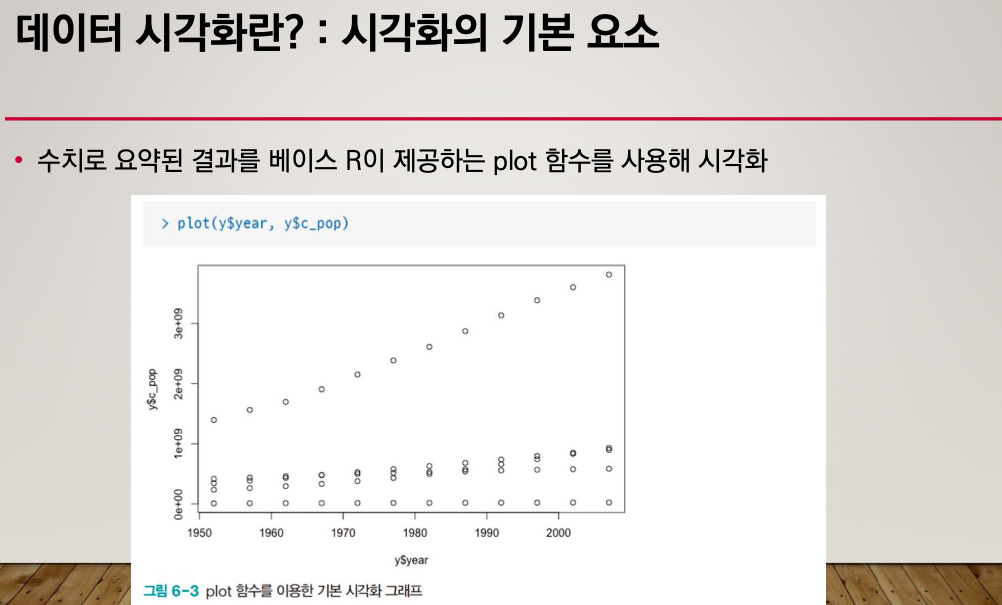
x좌표는 연도 y 좌표는 합산된 값
사용자 입장에서는 이 그래프는 무엇을 말하는지 모를 수 있다. 색깔이 다 똑같기 때문에
그래서 하나하나 옵션을 집어넣어 보자.

col = y$continent : 대륙끼리는 다른 색깔로 칠해달라
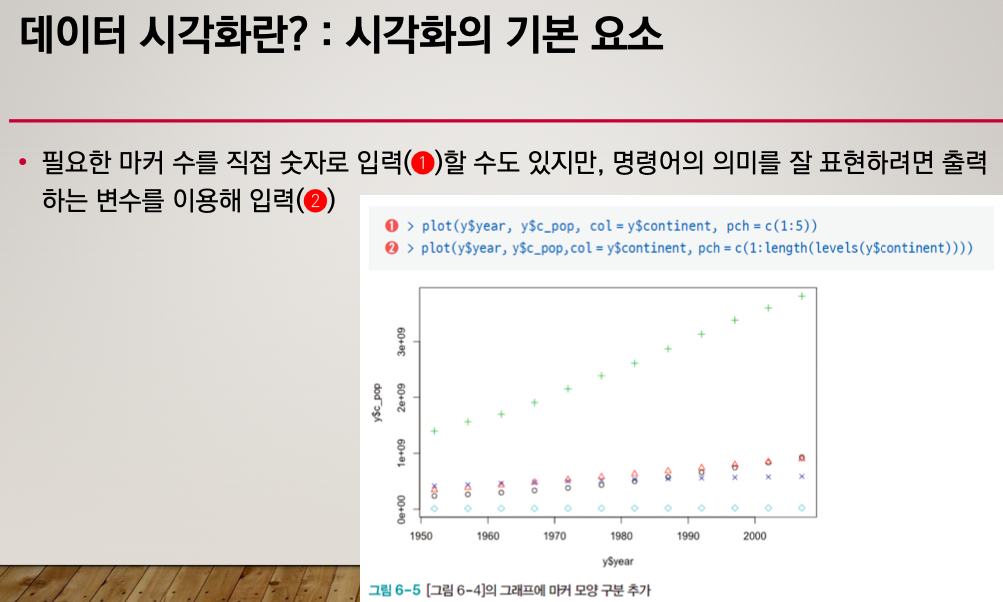
모양을 바꿔보자. pch
pch = 몇 ## 으로 하면 하나의 모양으로 바뀐다.
pch = c(1:5) # 5개의 모양으로
pch = c(1:length(levels(y$continent))) # 만약 5개로 끝나지 않고 계속 바뀔거 같으면 levels을 이용할 수 있다.
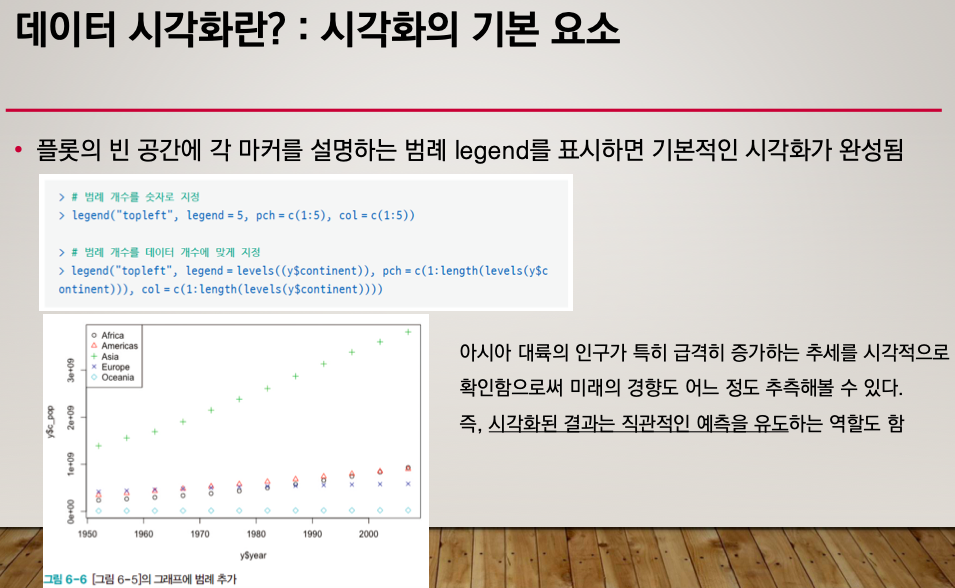
그럼 초록색은 뭐고 세모는 뭐지?
범례를 추가해야 한다.
legend

데이터를 가지고 가치를 가질 수 있게, 신뢰도를 높이기 위해 데이터 시각화를 사용한다.
- 직관적으로
- 핵심을 명확하게
- 경향과 이상값 확인
- 데이터의 문제점

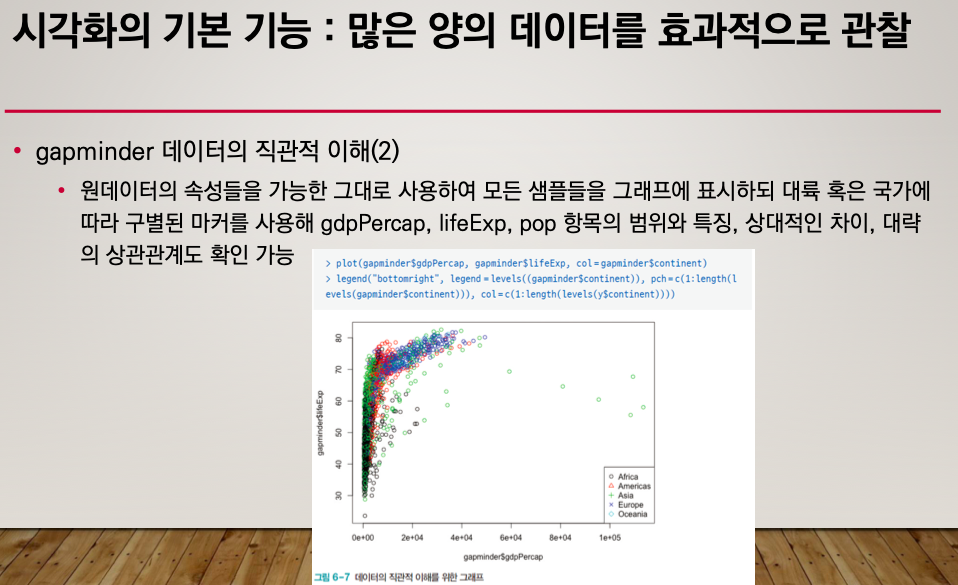
gdp, 기대수명, 인구수의 항목의 범위 특징을 확인해보자.
plot(gapminder$gdpPercap, gapminder$lifeExp, col=gapminder$continent)
legend("bottomright", legend = levels(gapminder&continent)), pch=c(1:length(levels(gapminder$continent))), col=c(1:length(levels(y$continent))))legend("범례의 위치", legend = 어떤 범례?)
그러나 이 그래프는 기호가 구분이 안되어 있다.
plot 에다가 pch를 추가해주면 된다.
그래프가 앞부분에 너무 몰려있다.
이럴 때는 log를 사용한다.
log scale
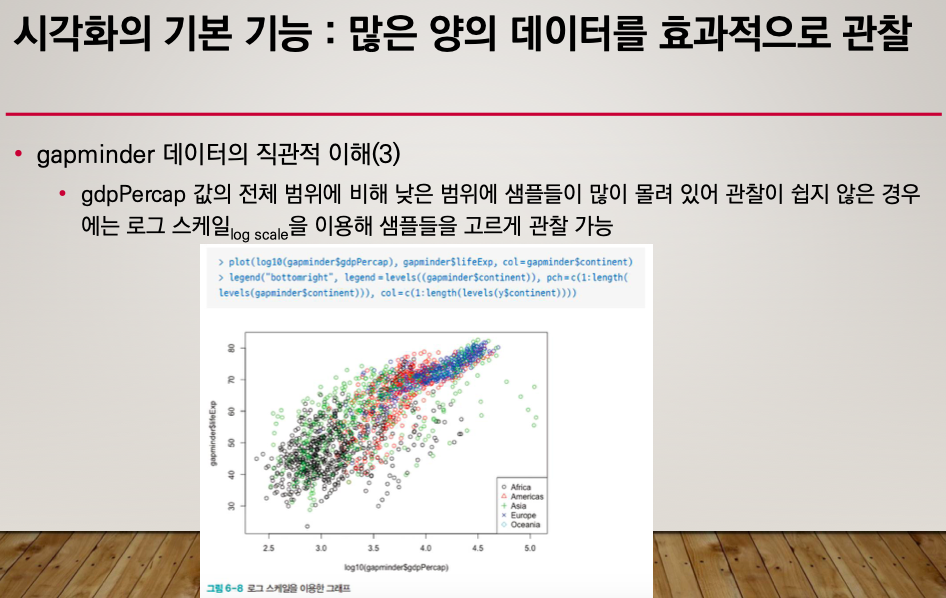
plot(log10
ggplot

ggplot은 더 다양한 옵션값이 있다.
범례를 자동으로 나타내어 준다.
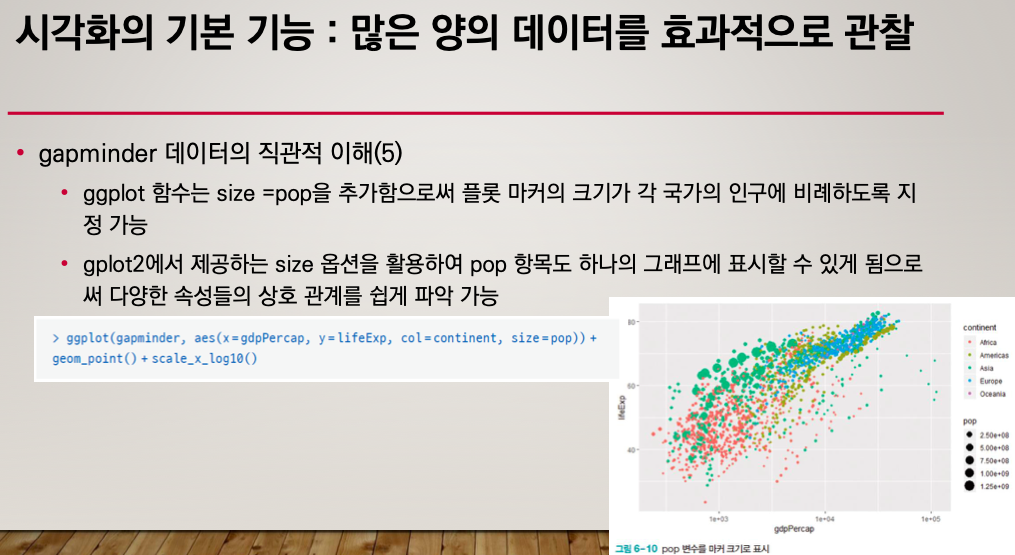
size = pop을 이용하면 크기에 따라 마커가 커진다.

투명도는 50%로 놓겠다. alpha = 0.5


관측연도 속성대로 보려면?
facet_wrap(~year)
어떠한 범례가 얼마만큼의 사이즈인지 알려주는 범례도 자동으로 추가된다.

비교/순위
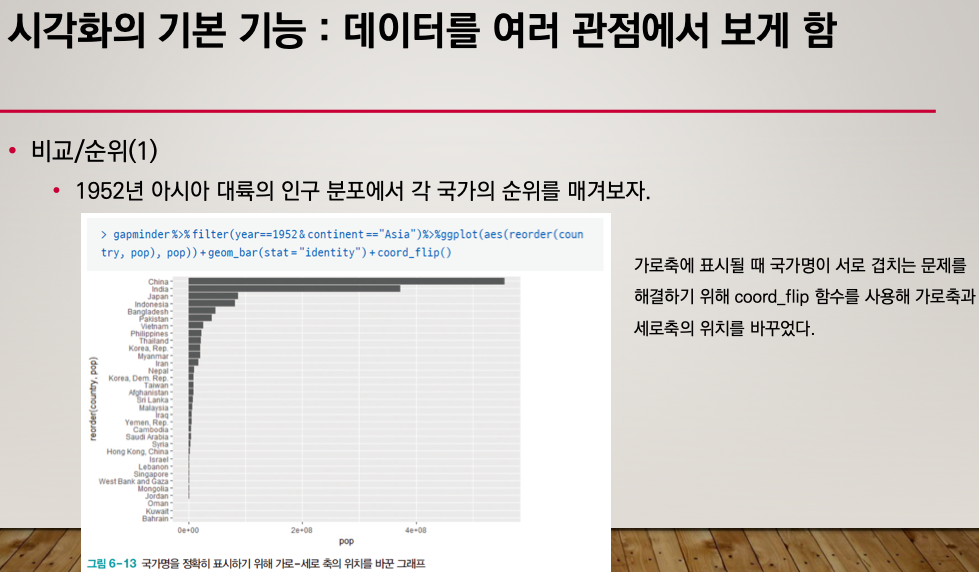
데이터를 가로축에 놓으면? 글자가 겹쳐서 보기가 힘들다.
따라서 다른 시각으로 보기 위해서 x축 y축으로 바꾼다.
로그 스케일
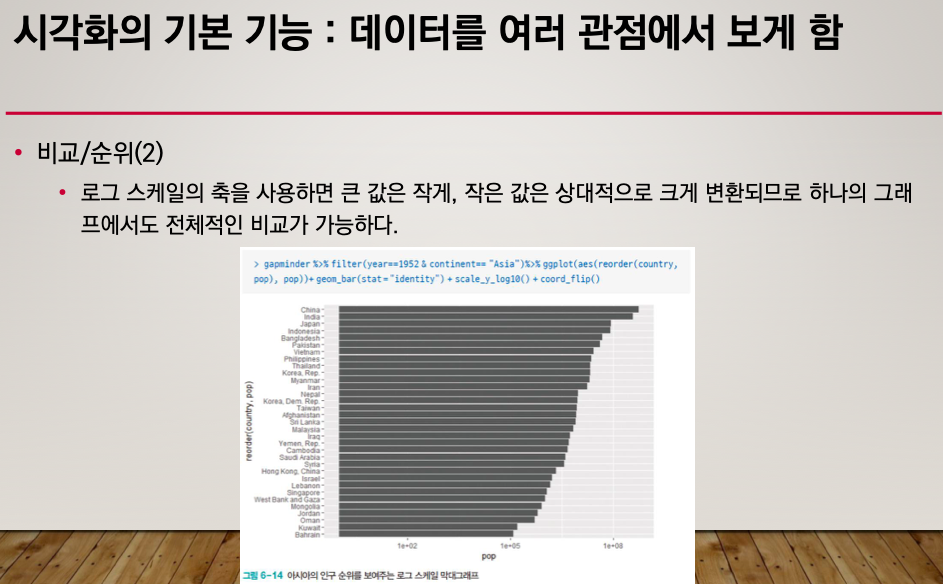
reorder() : 재정렬
geom_bar() : 막대그래프
scale_y_log10() : 데이터가 구분이 안돼서 로그 스케일 씌운다.
coard_flip() : x축 y축 변경
변화 추세
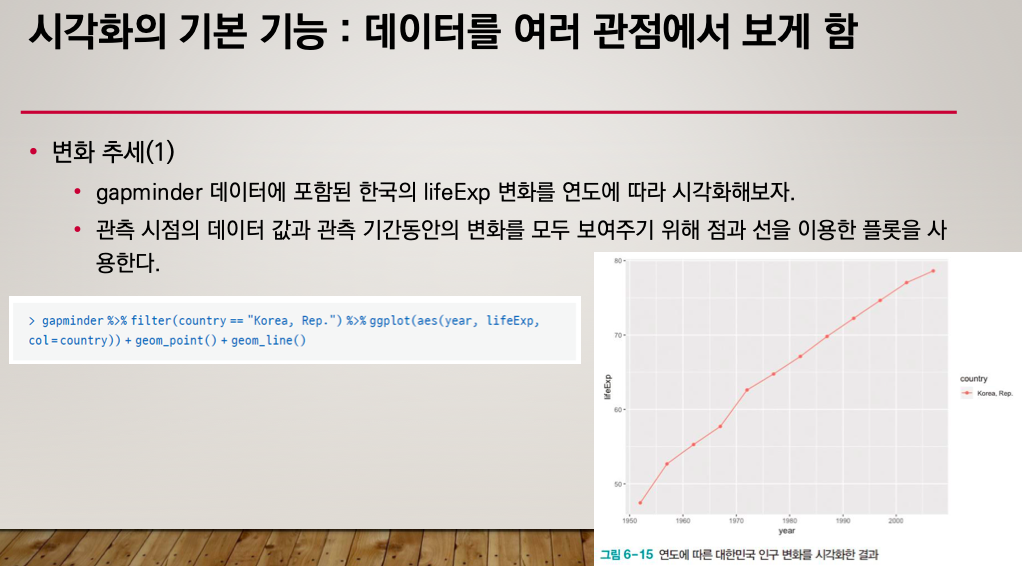

투명도 alpha
geom_smooth() : 추세선
분포, 구성비율

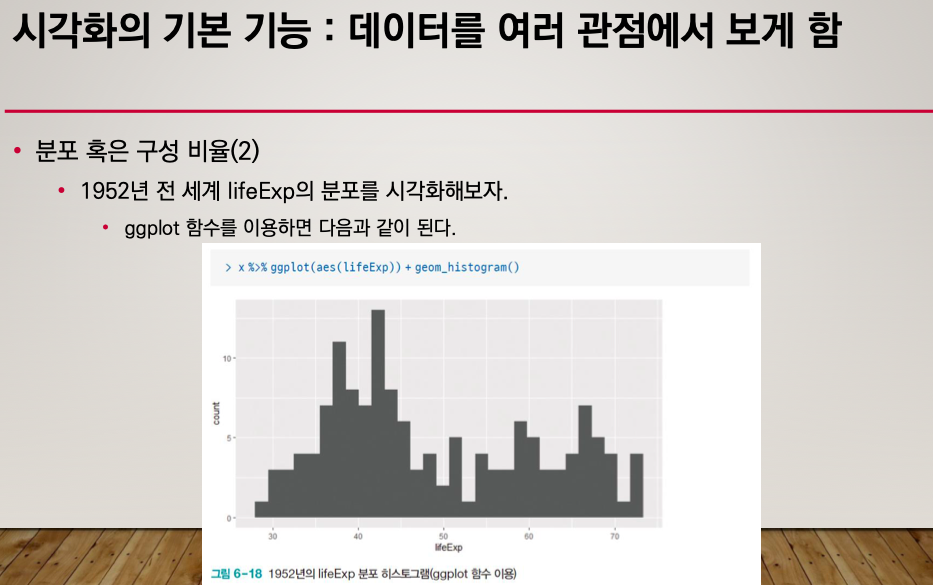

boxplot은 이상한 값을 제거하거나 확인하는 데에도 사용할 수 있다.
상관관계
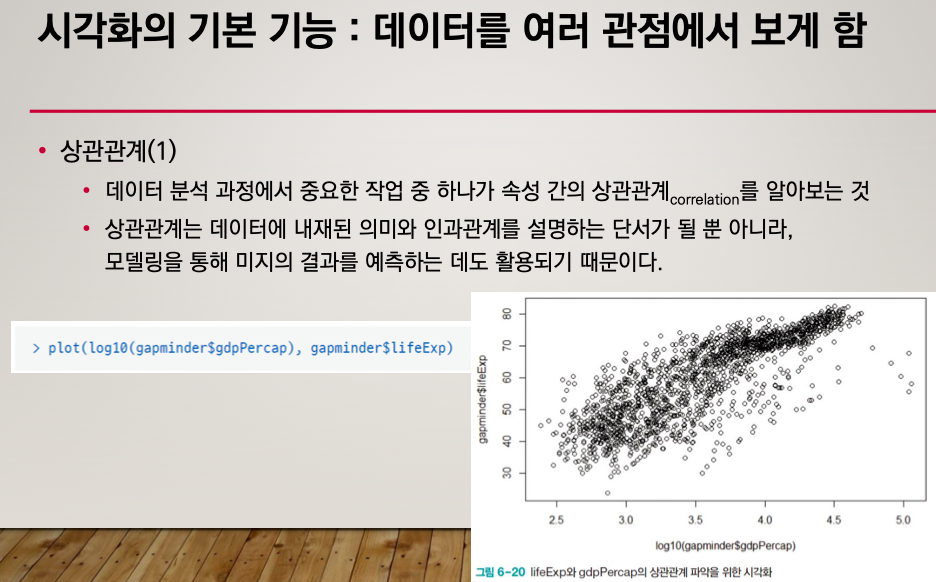

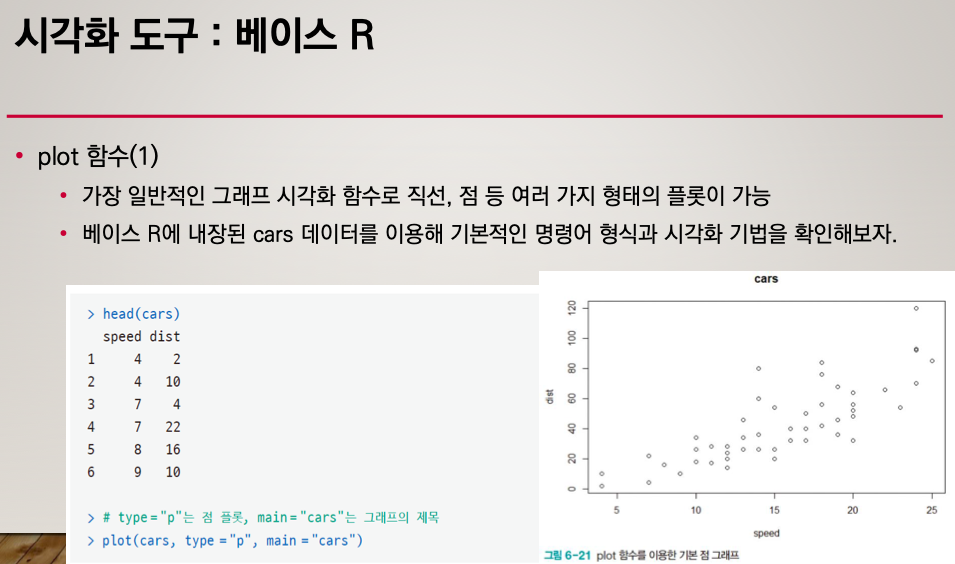
plot()
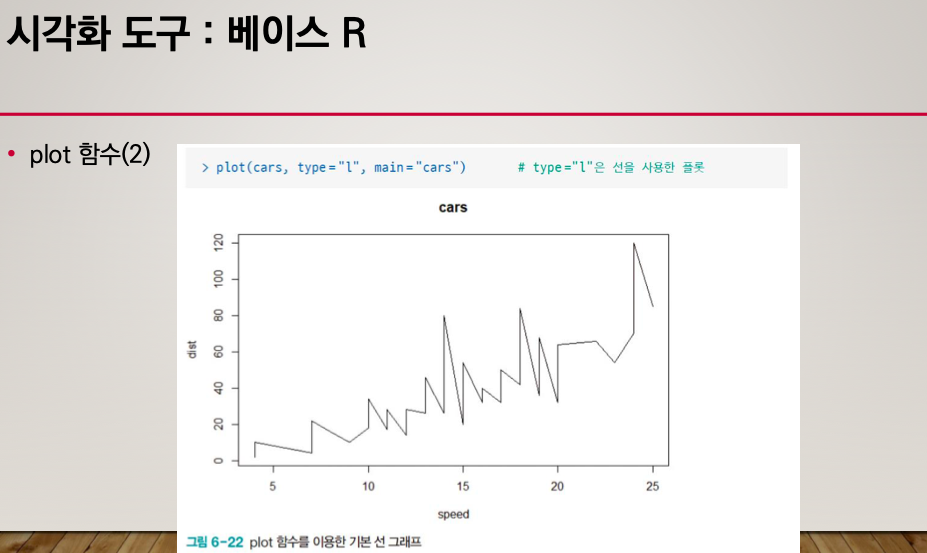
type = "l" # line 선
type = "p" # point 점

type = "b" # both 점 선 둘다

type = "h" # histogram 히스토그램
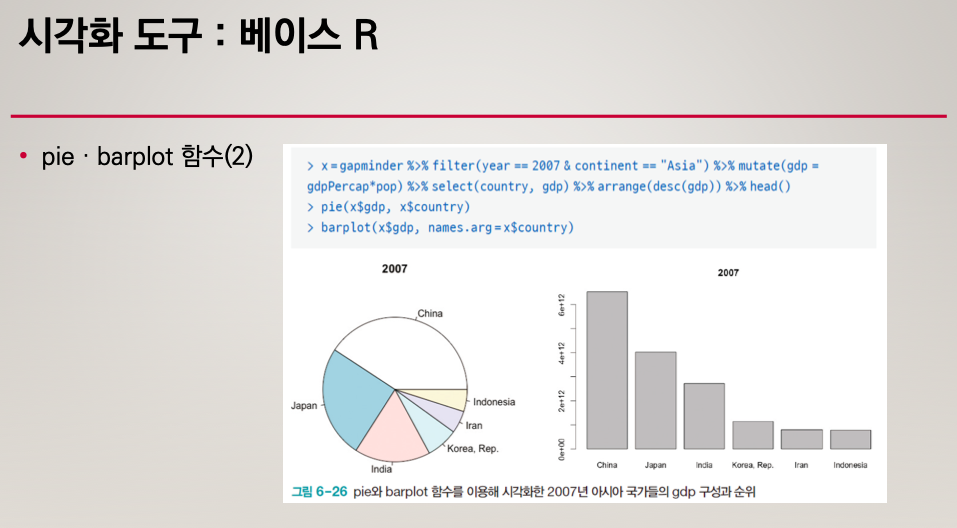
pie, barplot()

matplot()
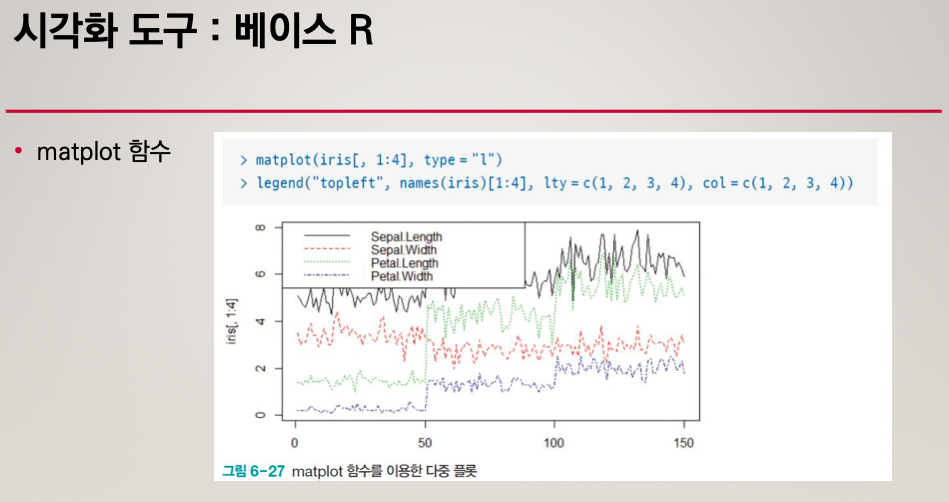
matplot 함수는 벡터나 행렬의 데이터를 사용해서 다중 플롯을 구현하는데에 유용하다.
여러개의 플롯이 하나의 그래프를 나타낼 수 있다.
범례를 써야한다.
hist()

벨런스와 분포를 확인하는 히스토그램
트리맵
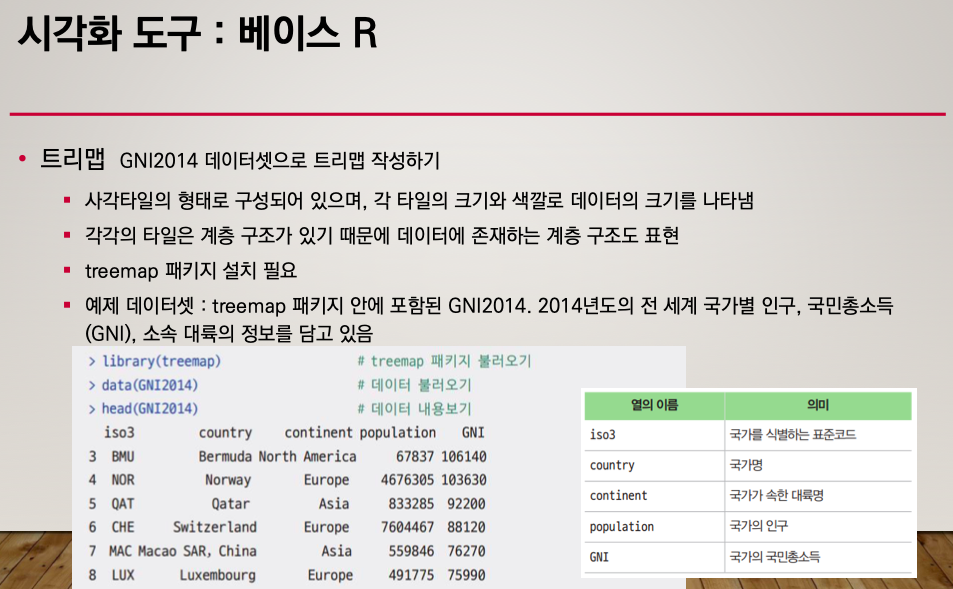
사각형 타일의 형태로 나타난다.
비율과 크기를 나타낼 수 있다.
데이터에 존재하는 계층구조로 표현된다.

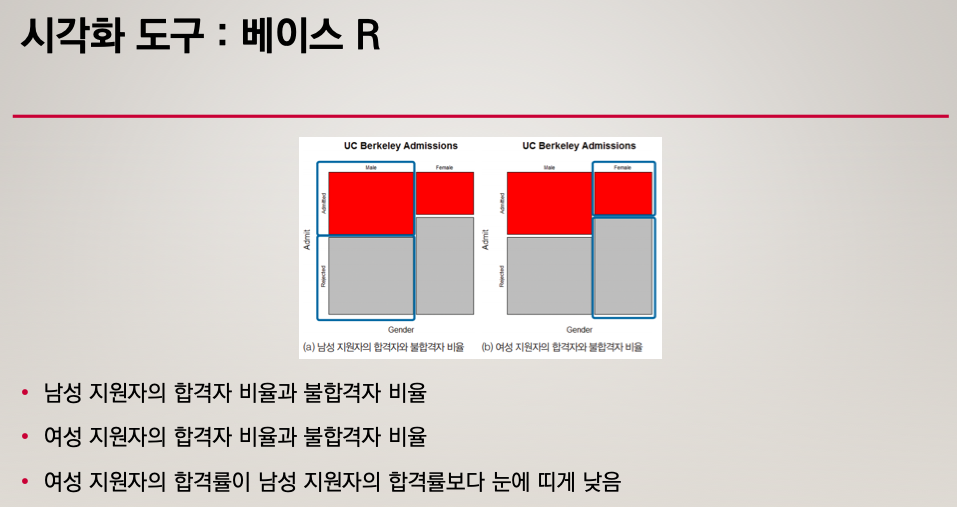
모자이크 플롯
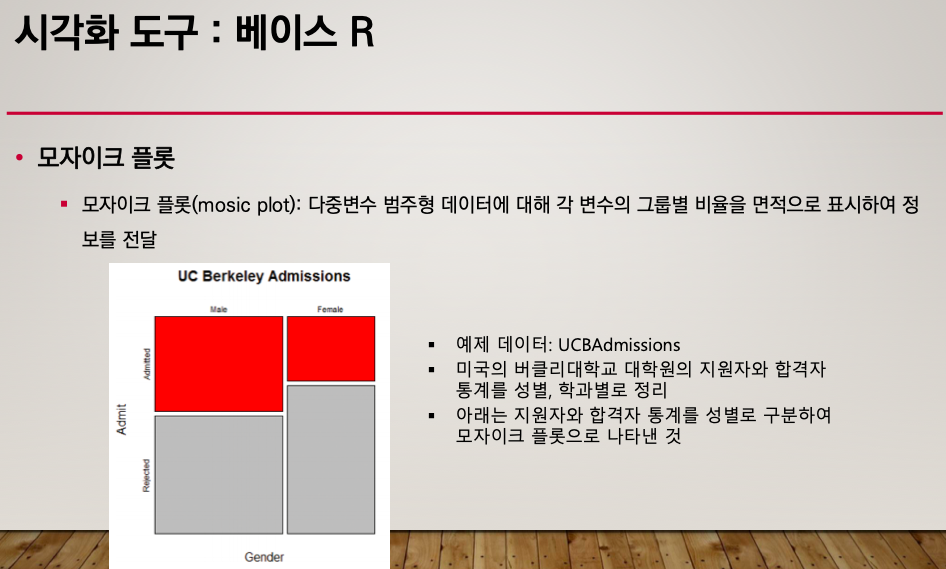
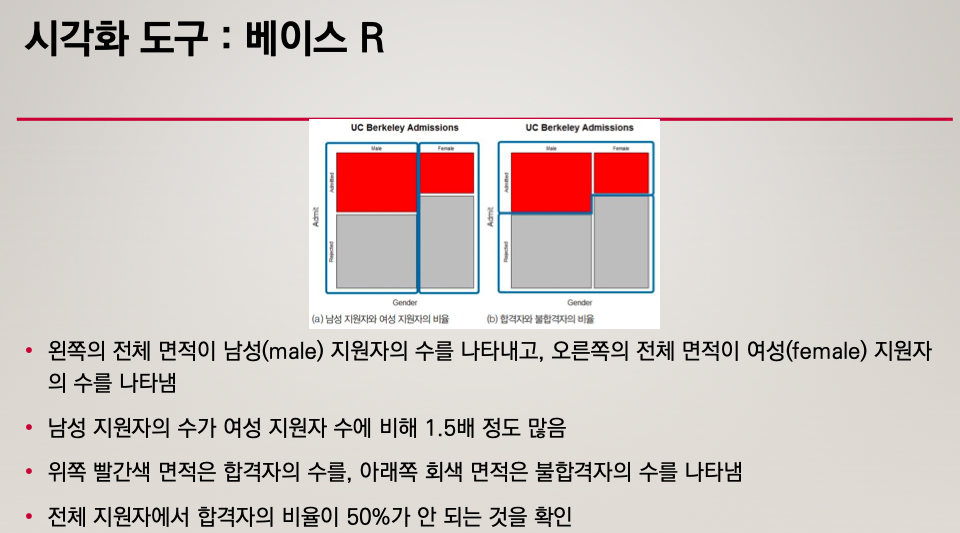

'📌 R' 카테고리의 다른 글
| R (11) - 구글맵 (0) | 2020.10.15 |
|---|---|
| R (10) - ggplot2 (0) | 2020.10.14 |
| R (8) - 데이터 가공, apply(), select(), filter(), group_by(), summaries() (0) | 2020.10.04 |
| R (7) - 산점도, 상관분석, 선그래프 (0) | 2020.09.24 |
| R (6) - 자료의 종류, table, barplot, pie, quantile, hist, boxplot (0) | 2020.09.23 |