






크로아티아만 뽑고 싶다?
조건식을 넣어서 추출하면 된다.



apply() : 연산


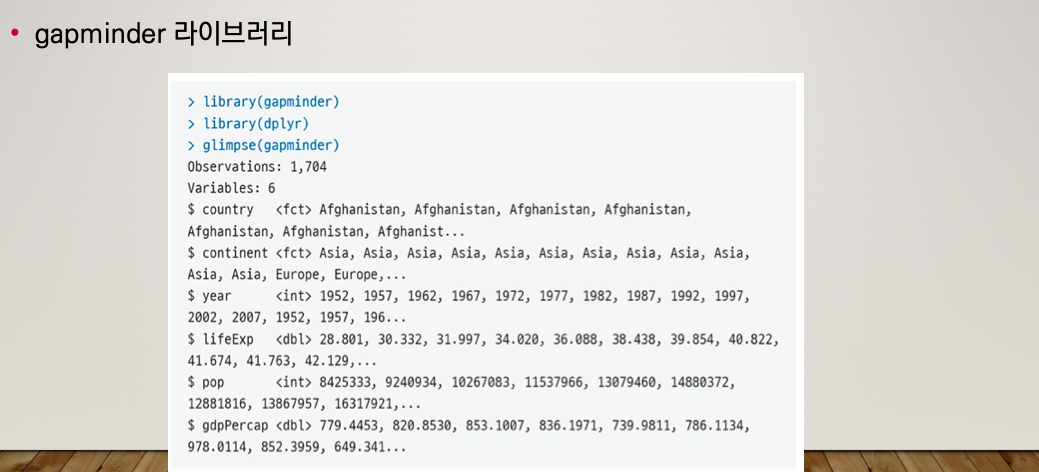
DPLYR 라이브러리

dplyr 팩키지가 데이터프레임을 솜씨있게 조작하는데 유용한 많은 함수를 제공한다. 이를 통해서, 위에서 언급된 반복을 줄이고, 실수를 범할 확률도 줄이고, 심지어 타이핑하는 수고도 줄일 수 있다. 보너스로, dplyr 문법은 훨씬 더 가독성도 높다.
select()

데이터 프레임에서 변수 일부만 뽑아서 작업하고자 할 때 select()를 쓴다.

filter()

꼬박꼬박 쓰지 않아도 돼서 간편하다.
year_country_gdp_euro <- gapminder %>%
filter(continent=="Europe") %>%
select(year,country,gdpPercap)gapminder 데이터프레임을 filter() 함수에 전달하고 나서, 필터링된 gapminder 데이터프레임 버젼을 select() 함수에 전달한다.
주의:연산순서가 이번 경우에 무척 중요하다. select() 함수를 먼저 실행하면, filter() 함수는 대륙 변수를 찾을 수 없는데, 이유는 이전 단계에서 제거했기 때문이다.
group_by(), summarise()

summarize( 데이터, 속성)
group
이제, 기본 R로 작업함으로써 실수를 범하기 쉬운 반복작업을 줄일 것으로 생각했지만, 현재까지 목표를 달성하지 못했다. 왜냐하면, 각 대륙마다 상기 작업을 반복해야 되기 때문이다. filter() 대신에, group_by()를 사용한다.
filter()는 특정 기준을 만족하는 관측점만 넘겨준다(이번 경우: continent=="Europe"). group_by()는 본질적으로, 필터에서 사용할 수 있는 모든 유일무이한 기준을 사용할 수 있다.
str(gapminder %>% group_by(continent))
group_by() 함수를 사용한 데이터프레임 구조(grouped_df)가 원래 gapminder 데이터프레임 구조(data.frame)와 같지 않음에 주목한다. grouped_df는 list 리스트로 간주될 있는데, list에 각 항목이 data.frame으로, 각 데이터프레임은 특정 대륙 continent에 대응되는 행만 담겨진다(적어도 상기 예제의 경우).

group_by() 함수는 summarize()와 함께할 때 훨씬 더 흥미롭다. 두 함수를 조합하면 새로운 변수가 생성되는데, 각 대륙별 데이터프레임에 대해 반복적인 함수 작업을 수행할 수 있다. 다시 말해, group_by() 함수를 사용해서, 최초 데이터프레임을 다수 조각으로 쪼개고 나서, 각각에 대해 함수(예를 들어 mean() 혹은 sd())를 summarize() 내부에서 실행시킨다.

%>% 연산자

%>% : 첫번째 인자값으로 들어온다.
gapminder %>% group_by(continent, country)
= group_by(gapminder, continent, country)

year_country_gdp 데이터프레임을 열게되면, year, country, gdpPercap 변수만 담겨있는 것을 보게 된다. 위에서는 정규 문법이 사용되었지만, dplyr 팩키지의 장점은 파이프를 사용해서 함수 다수를 조합하는데 있다. 파이프 문법은 이전에 R에서 살펴봤던 것과는 사뭇 다른다. 위에서 파이프를 사용했던 것을 다시 작성해본다.
year_country_gdp <- gapminder %>% select(year,country,gdpPercap)파이프를 사용해서 작성한 이유에 대한 이해를 돕기 위해서, 단계별로 살펴보자. 먼저 gapminder 데이터프레임을 불러오고 나서, %>% 파이프 기호를 사용해서 다음 작업단계(select() 함수)로 전달했다. 이번 경우에는 select() 함수에 데이터 객체를 명세하지 않았다. 이유는 이전 파이프에서 건네받았기 때문이다.
재미난 사실: 쉘에서 이전에 파이프를 접해봤을 것이다. R에서 파이프 기호가 %>%인 반면, 쉘에서는 |을 사용한다. 하지만, 개념은 동일하다!




















substr(속성값, 어디서부터?, 어디까지?) : 데이터 자르기
두번째 글자부터, 끝까지
nchar() : 문자열의 길이






'📌 R' 카테고리의 다른 글
| R (10) - ggplot2 (0) | 2020.10.14 |
|---|---|
| R (9) - 데이터 시각화, 상관관계, legend, matplot, treetop (0) | 2020.10.07 |
| R (7) - 산점도, 상관분석, 선그래프 (0) | 2020.09.24 |
| R (6) - 자료의 종류, table, barplot, pie, quantile, hist, boxplot (0) | 2020.09.23 |
| R (5) - if else, 반복문, 결측값, 이상값 (0) | 2020.09.22 |