

📌 이 글은 권철민 님의 딥러닝 CNN 완벽가이드를 바탕으로 작성한 포스팅입니다.

목차
- GoogLeNet Architecture
- GoogLeNet의 특징
- Inception Module의 구조
- 1×1 Convolution 연산을 통한 Feature Map 채널(깊이) 압축
- 1×1 Convolution 연산을 이용한 Inception module 구성
- Inception Network의 구조
1. GoogLeNet Architecture
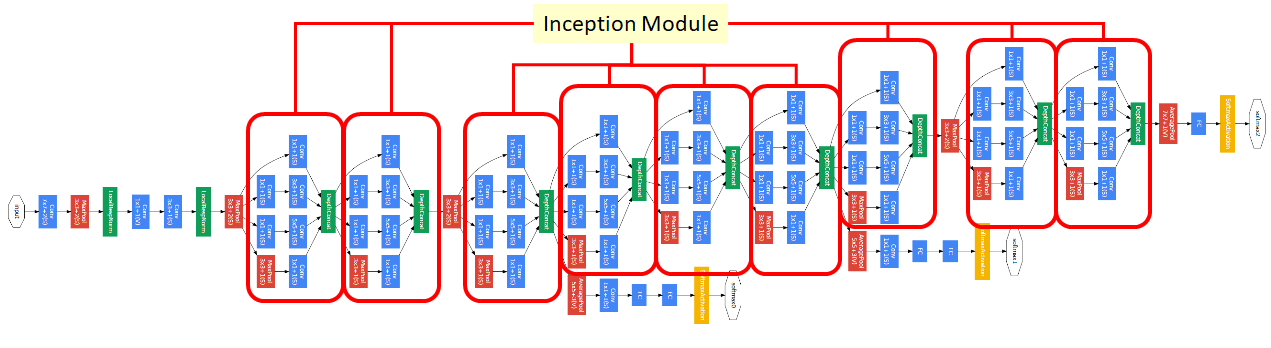
GoogLeNet은 Inception module이 연결되어 있는 구조이다.
1x1 convolution이 굉장히 많이 사용된다.
영화 인셉션을 따와서 이름을 지었다고 한다.
그럼 왜 구글넷은 이런 구조로 만들었을까?
2. GoogLeNet 특징
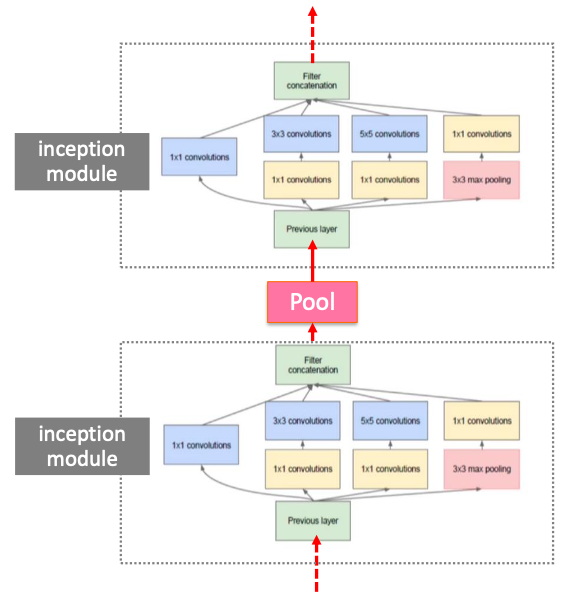
- 큰 사이즈의 Receptive Field가 제공하는 장점은 수용하면서, Weight 파라미터의 수를 줄일 수 있는 네트워크 구성
- 적절한 커널의 필터 사이즈와 Pooling을 고민해서 찾아내기 보다는 여러가지 사이즈의 필터들(3x3 conv, 5x5 conv)을 한꺼번에 결합하는(concat) 방식 제공(논문에서는 이를 Inception module로 지칭한다)
- GoogLeNet은 Inception module들을 연속적으로 이어서 구성
- 여러 사이즈의 필터들이 서로 다른 공간 기반으로 Feature들을 추출하고 이를 결합하면서 보다 풍부한 Feature Extractor layer구성이 가능함.

서로 다른 사이즈의 필터를 통한 보다 다양한 Feature Extraction을 수행한다.
3. Inception Module 의 구조
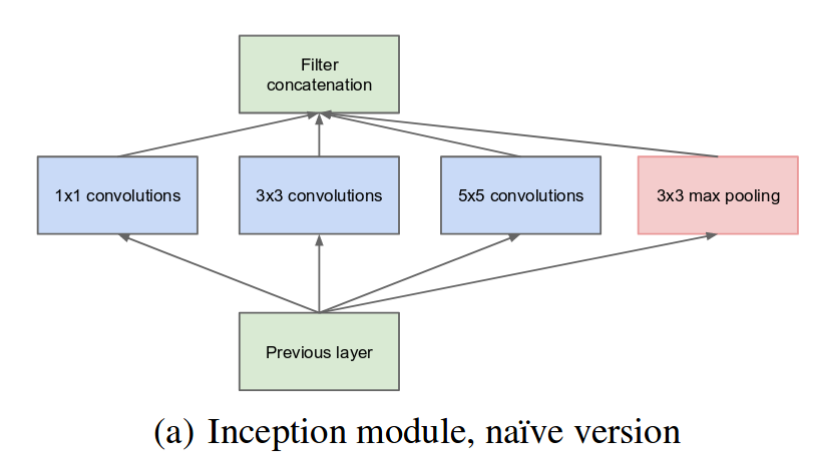
- 여러 사이즈의 커널을 결합하지만 3×3, 5×5 사이즈 커널의 Convolution 연산 수행시, 많은 파라미터 수가 증가되고 연산량이 늘어난다.
- 많은 파라미터 수는 오버피팅을 더 악화시킬 수 있다.
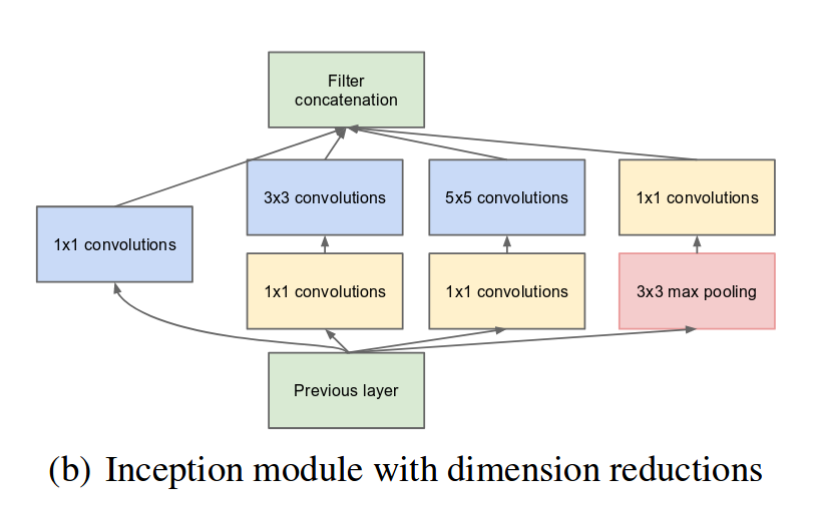
- 3×3, 5×5 Convolution 연산을 수행하기 전에 먼저 1×1 Convolution을 적용하여 파라미터 수를 획기적으로 감소시킨다.
- 1×1 Convolution은 선행 layer의 특징을 함축적으로 표현하면서 파라미터 수를 줄이는 차원 축소 역할을 수행한다.
4. 1×1 Convolution 연산을 통한 Feature Map 채널(깊이) 압축
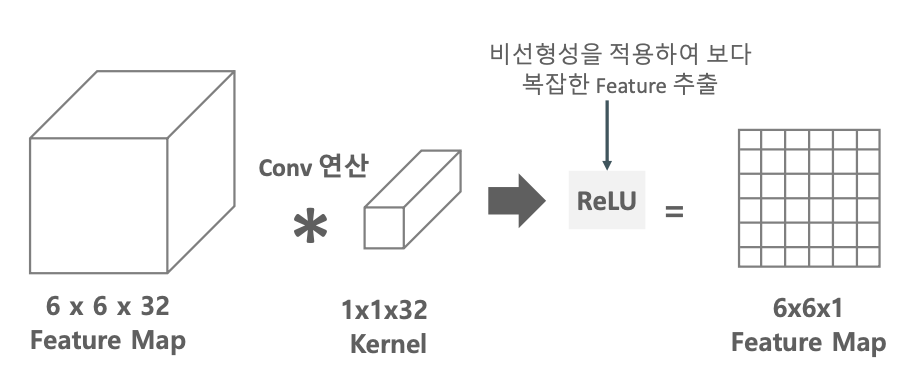
피쳐들의 중요 특성을 끄집어 내기에 1×1 은 너무 작지 않냐라는 생각이 든다.
그러나 1×1 연산은 원본 이미지에 적용하지는 않고, 어느 정도 크기가 감소된 피쳐맵에 적용한다.
그럼에도 불구하고 1×1을 왜할까? 사이즈 그대로 가는데?
1×1 Convolution은 비선형성을 좀더 강화 시켜준다.
1×1 Convolution 하고 ReLU를 거친다.
채널의 깊이가 깊을수록(필터의 채널 수가 많을수록) 파라미터의 수가 증가되면, 피쳐의 특징들이 추상화 되면서 좀더 풍부해진다라고 알고 있지만, 그렇게 하지 않고도 1×1 Convolution를 통해서 비록 필터의 수는 작지만 ReLU 연산을 하고, 그 후에 또 3×3 Convolution 연산을 적용을 하면서 비선형성을 증가시킴으로써, 채널의 깊이가 길어지는(필터의 채널 수를 늘리는) 만큼 이상의 어떤 풍부한 피쳐들의 특징을 가져올 수 있다는 것이다. 그러면 연산량을 줄일 수도 있고, 파라미터 수를 감소시킬 수도 있다.
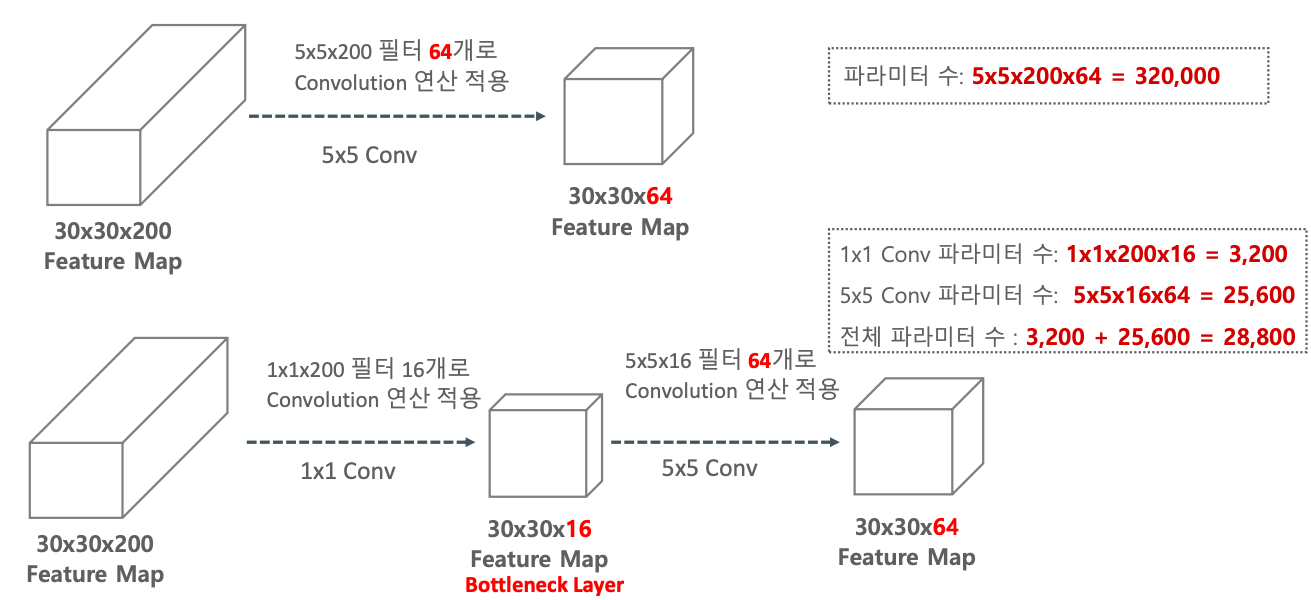
(30×30×200)의 피쳐맵에 (5×5×200) Convolution을 64개 적용하여 (30×30×64)인 피쳐맵이 만들어졌다.
그러면 5×5×200×64 개의 파라미터가 구해진다.
그러지 말고 1×1 Convolution을 적용시켜보자.
(30×30×200)의 피쳐맵에 (1×1×200) Convolution을 16개 적용하면 (30×30×16)인 피쳐맵이 만들어진다.
이렇게 만들어진 피쳐맵에 (5×5×16) Convolution을 64개 적용해주면, 다시 압축시켰다가 풀어주는 Bottleneck Layer가 적용하여 비선형성이 강화됨과 동시에 연산량도 줄고 전체 파라미터 수가 줄어드는 것을 확인할 수 있다.
5. 1×1 Convolution을 이용한 Inception module 구성
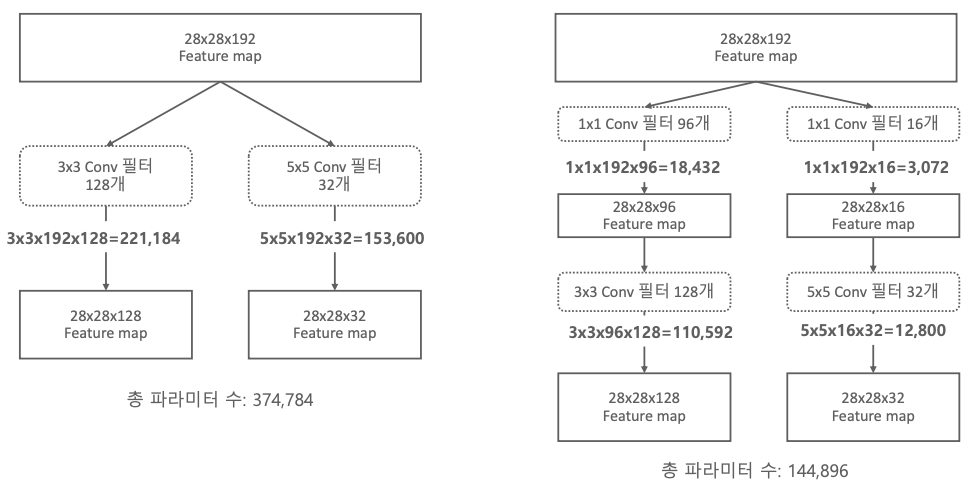
1×1 Convolution Filter를 이용하면 파라미터 수가 확연히 줄어드는 것을 확인할 수 있다.
압축적인 특성을 가져간 후 다시 풀면서 비선형성의 혜택을 얻을 수 있다.
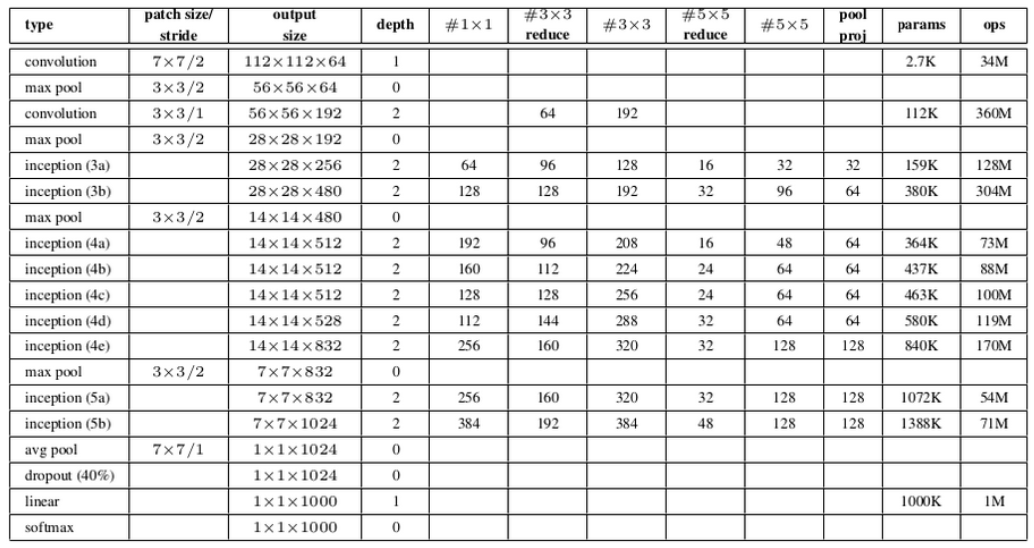
6. Inception Network의 구조
각 마지막 레이어에서 나온 피쳐맵을 채널 레벨로 (concat)합친다. ex) 28×28×(96+64+128)
그리고 또 다음 Inception module에 집어 넣는다.
그 안에서 Pooling을 할 때도 있고 안 할 때도 있다.
중간에 softmax로 결과를 예측하는 것이 있는데 마지막에 좀 섞어서 이미지 분류에 사용을 한다.
이 구조를 GoogLeNet 이라고 하지 않고 Inception Network 라고들 한다.
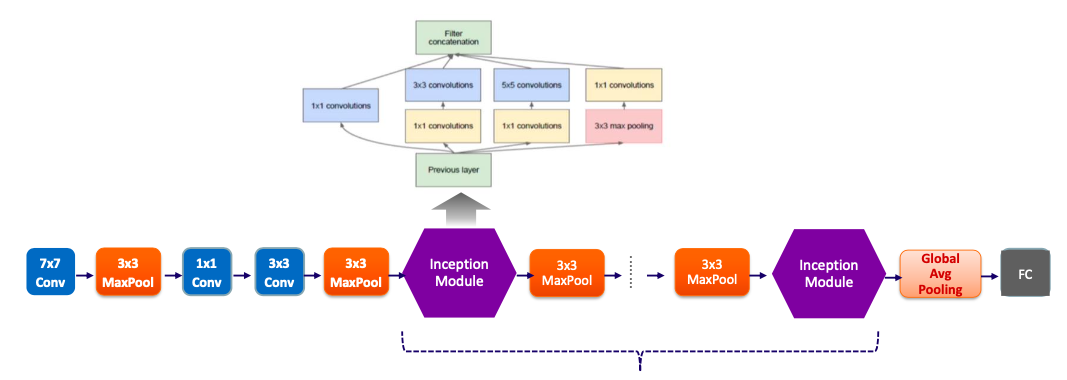
Inception Network는 총 9개의 Inception Block으로 구성된다.
- 2개의 Inception Module 후 3×3 Max Pooling
- 다시 5개의 Inception Module 후 3×3 Max Pooling
- 이후 2개의 Inception Module 후 마지막으로 Global Average Pooling
'🖼 Computer Vision > CNN' 카테고리의 다른 글
| CNN - EfficientNet (0) | 2022.04.04 |
|---|---|
| CNN - ResNet (0) | 2022.04.02 |
| CNN - VGGNet (0) | 2022.04.01 |
| CNN - AlexNet (0) | 2022.03.31 |
| CNN - Image data scaling preprocessing (0) | 2022.03.27 |