
📌 이 글은 권철민 님의 딥러닝 CNN 완벽가이드를 바탕으로 작성한 포스팅입니다.
목차
- VGG 개요
- VGGNet의 장점
- VGGNet 구조
- VGGNet 구현 코드
VGG 개요
- 네트워크의 깊이와 모델 성능 영향에 집중했다.
- Convolution 커널 사이즈를 3 x 3으로 고정시켰다. 커널 사이즈가 크면 이미지 사이즈 축소가 급격하게 이뤄져서 더 깊은 층을 만들기 어렵고, 파라미터 개수와 연산량도 더 많이 필요하기 때문이다.
VGGNet의 장점
- 단일화된 Kernel 크기, Padding, Strides 값으로 단순한 네트워크를 구성하지만 AlexNet 보다 더 나은 성능
- AlexNet의 11x11, 5x5와 같은 큰 Receptive Field를 가진 Kernel 크기를 적용하지 않고도, 3X3 Kernel을 연속으로 적용
- AlexNet보다 더 깊은 Network을 구성
- 하나 더 적은 Parameter 개수로 연산 성능을 개선
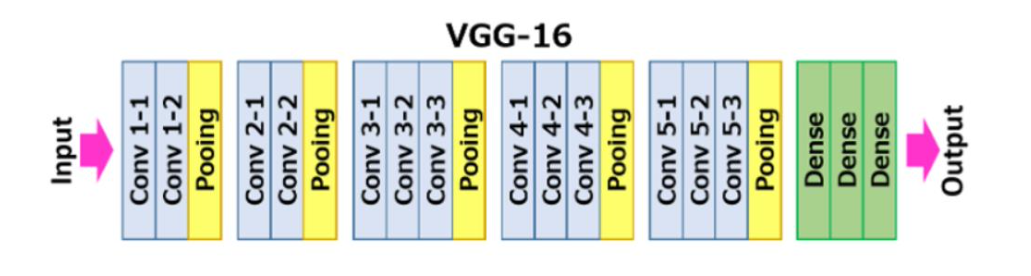
VGGNet 구조
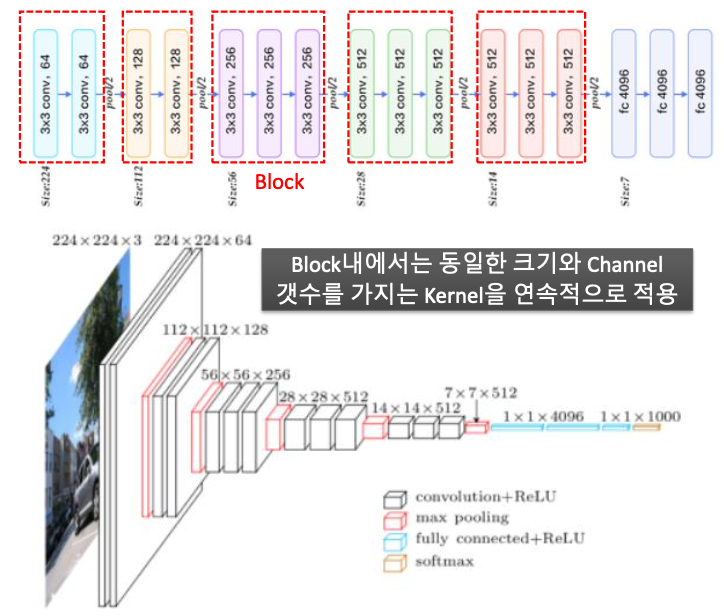
- 11X11, 5X5 와 같은 넓은 크기의 Kernel로 Convolution 연산을 적용하는 것보다 여러 개의 3X3 Convolution 연산을 수행하는 것이 더 뛰어난 Feature 추출 효과를 나타낸다.
- AlexNet 대비 더 많은 채널수와 더 깊은 Layer 구성된다.
- 3x3 크기의 Kernel을 (2번 또는 3번)연속해서 Convolution 적용한 뒤, Max Pooling 적용하여 일련의 Convolution Feature map Block을 생성한다.
- 개별 Block내에서는 동일한 커널 크기와 Channel 갯수를 적용하여 동일한 크기의 feature map들을 생성한다.
- 이전 Block 내에 있는 Feature Map 대비 새로운 Block내에 Feature Map 크기는 2배로 줄어 들지만 채널 수는 2배로 늘어난다.(맨 마지막 block 제외)
VGGNet 구현 코드
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense , Conv2D , Dropout , Flatten , Activation, MaxPooling2D , GlobalAveragePooling2D
from tensorflow.keras.optimizers import Adam , RMSprop
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.callbacks import ReduceLROnPlateau , EarlyStopping , ModelCheckpoint , LearningRateScheduler
def create_vggnet(in_shape=(224, 224, 3), n_classes=10):
input_tensor = Input(shape=in_shape)
# Block 1
x = Conv2D(64, (3, 3), activation='relu', padding='same', name='block1_conv1')(input_tensor)
x = Conv2D(64, (3, 3), activation='relu', padding='same', name='block1_conv2')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block1_pool')(x)
# Block 2
x = Conv2D(128, (3, 3), activation='relu', padding='same', name='block2_conv1')(x)
x = Conv2D(128, (3, 3), activation='relu', padding='same', name='block2_conv2')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block2_pool')(x)
# Block 3
x = Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv1')(x)
x = Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv2')(x)
x = Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv3')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block3_pool')(x)
# Block 4
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv1')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv2')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv3')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block4_pool')(x)
# Block 5
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv1')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv2')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv3')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block5_pool')(x)
x = GlobalAveragePooling2D()(x)
x = Dropout(0.5)(x)
x = Dense(units = 120, activation = 'relu')(x)
x = Dropout(0.5)(x)
# 마지막 softmax 층 적용.
output = Dense(units = n_classes, activation = 'softmax')(x)
model = Model(inputs=input_tensor, outputs=output)
model.summary()
return model일정 부분이 반복되는 부분은 Block으로 한번 만들어보자.
VGG16을 연속된 Conv를 하나의 block으로 간주하고 이를 생성할 수 있는 conv_block()함수 생성
- conv_block()함수는 인자로 입력 feature map과 Conv 연산에 사용될 커널의 필터 개수와 사이즈(무조건 3x3)
- 출력 feature map을 크기를 줄이기 위한 strides를 입력 받음
- 또한 repeats인자를 통해 연속으로 conv 연산 수행 횟수를 정함.
from tensorflow.keras.layers import Conv2D, Dense, MaxPooling2D, GlobalAveragePooling2D, Input
from tensorflow.keras.models import Model
# 인자로 입력된 input_tensor에 kernel 크기 3x3(Default), 필터 개수 filters인 conv 연산을 n회 연속 적용하여 출력 feature map을 생성.
# repeats인자를 통해 연속으로 conv 연산 수행 횟수를 정함
# 마지막에 MaxPooling(2x2), strides=2 로 출력 feature map의 크기를 절반으로 줄임. 인자로 들어온 strides는 MaxPooling에 사용되는 strides임.
def conv_block(tensor_in, filters, kernel_size, repeats=2, pool_strides=(2, 2), block_id=1):
'''
파라미터 설명
tensor_in: 입력 이미지 tensor 또는 입력 feature map tensor
filters: conv 연산 filter개수
kernel_size: conv 연산 kernel 크기
repeats: conv 연산 적용 회수(Conv2D Layer 수)
pool_strides:는 MaxPooling의 strides임. Conv 의 strides는 (1, 1)임.
'''
x = tensor_in
# 인자로 들어온 repeats 만큼 동일한 Conv연산을 수행함.
for i in range(repeats):
# Conv 이름 부여
conv_name = 'block'+str(block_id)+'_conv'+str(i+1)
x = Conv2D(filters=filters, kernel_size=kernel_size, activation='relu', padding='same', name=conv_name)(x)
# max pooling 적용하여 출력 feature map의 크기를 절반으로 줄임. 함수인자로 들어온 strides를 MaxPooling2D()에 인자로 입력.
x = MaxPooling2D((2, 2), strides=pool_strides, name='block'+str(block_id)+'_pool')(x)
return x요즘 나오는 모델들은 Block 형태로 설계가 되어 있다.
따라서 Block 단위로 이해하는 것이 좋다.
생성한 conv_block()을 이용하여 convolution block을 생성하고 확인
input_tensor = Input(shape=(224, 224, 3), name='test_input')
x = conv_block(tensor_in=input_tensor, filters=64, kernel_size=(3, 3), repeats=3, pool_strides=(2, 2), block_id=1)
conv_layers = Model(inputs=input_tensor, outputs=x)
conv_layers.summary()VGG 16 모델 생성
- 앞에서 만든 conv_block()을 이용하여 block별로 feature map들을 생성. 총 5개의 block 생성.
- 1번~ 4번 block까지는 입력 feature map 대비 출력 feature map의 필터수는 2배, 크기는 절반으로 줄임. 5번 block은 filter수는 그대로, 크기만 절반으로 줄임.
- 논문 대로 네트웍 구성시 Fully connected layer에서 많은 파라미터가 필요하므로 GlobalAverage Pooling을 적용
def create_vggnet_by_block(in_shape=(224, 224,3), n_classes=10):
input_tensor = Input(shape=in_shape, name='Input Tensor')
# (입력 image Tensor 또는 Feature Map)->Conv->Relu을 순차적으로 2번 실행, 출력 Feature map의 filter 수는 64개. 크기는 MaxPooling으로 절반.
x = conv_block(input_tensor, filters=64, kernel_size=(3, 3), repeats=2, pool_strides=(2, 2), block_id=1)
# Conv연산 2번 반복, 입력 Feature map의 filter 수를 2배로(128개), 크기는 절반으로 출력 Feature Map 생성.
x = conv_block(x, filters=128, kernel_size=(3, 3), repeats=2, pool_strides=(2, 2), block_id=2)
# Conv연산 3번 반복, 입력 Feature map의 filter 수를 2배로(256개), 크기는 절반으로 출력 Feature Map 생성.
x = conv_block(x, filters=256, kernel_size=(3, 3), repeats=3, pool_strides=(2, 2), block_id=3)
# Conv연산 3번 반복, 입력 Feature map의 filter 수를 2배로(512개), 크기는 절반으로 출력 Feature Map 생성.
x = conv_block(x, filters=512, kernel_size=(3, 3), repeats=3, pool_strides=(2, 2), block_id=4)
# Conv 연산 3번 반복, 입력 Feature map의 filter 수 그대로(512), 크기는 절반으로 출력 Feature Map 생성.
x = conv_block(x, filters=512, kernel_size=(3, 3), repeats=3, pool_strides=(2, 2), block_id=5)
# GlobalAveragePooling으로 Flatten적용.
x = GlobalAveragePooling2D()(x)
x = Dropout(0.5)(x)
x = Dense(units = 120, activation = 'relu')(x)
x = Dropout(0.5)(x)
# 마지막 softmax 층 적용.
output = Dense(units = n_classes, activation = 'softmax')(x)
# 모델을 생성하고 반환.
model = Model(inputs=input_tensor, outputs=output, name='vgg_by_block')
model.summary()
return model
model = create_vggnet_by_block(in_shape=(224, 224, 3), n_classes=10)'🖼 Computer Vision > CNN' 카테고리의 다른 글
| CNN - ResNet (0) | 2022.04.02 |
|---|---|
| CNN - GoogLeNet (0) | 2022.04.01 |
| CNN - AlexNet (0) | 2022.03.31 |
| CNN - Image data scaling preprocessing (0) | 2022.03.27 |
| OpenCV 이미지 로딩시 BGR을 RGB로 변환해야 하는 이유 (0) | 2022.03.27 |