
📌 이 글은 권철민 님의 딥러닝 CNN 완벽가이드를 바탕으로 작성한 포스팅입니다.
목차
- ResNet : 깊은 네트워크를 Identity layer로 구성한 모델
- ResNet의 주요 특징 : Short Cut & Identity Block
- 깊은 네트워크를 Identity layer로 구성한다면?
- ResNet - Residual Learning & Identity Mapping
- ResNet 구조
- ResNet 구조 비교
- identity block 생성
- 위에서 생성한 identity_block()을 호출하여 어떻게 identity block이 구성되어 있는지 확인
- identity block을 연속으로 이어서 하나의 Stage 구성.
- 각 stage내의 첫번째 identity block에서 입력 feature map의 크기를 절반으로 줄이는 block을 생성하는 함수 conv_block() 만들기
- conv_block()과 identity_block()을 호출하여 stage 구성.
- ResNet50 모델 생성
- ResNet50 Pretrained 모델 학습
ResNet : 깊은 네트워크를 Identity layer로 구성한 모델

ResNet은 152개의 레이어를 가진 모델이다. 오차율도 굉장히 많이 떨어졌다.
ResNet 열풍이 불 정도로...
VGG이후 더 깊은 Network에 대한 연구 증가했다.
하지만 Network 깊이가 깊어질수록 오히려 성능이 저하됐다.

Kernel 사이즈 조절, dropout이나 Weight Decay등으로 Overfitting을 줄이는 방식으로 Network 깊이를 늘려가는 한계점 봉착
이렇게 깊게 Network를 파면 ReLU를 써도 Vanishing Gradient 문제가 발생하고, 제대로 최적의 loss가 감소되지 않는 문제가 발생했다.
ResNet의 주요 특징 : Short Cut & Identity Block

ResNet은 이전 Layer의 출력값을 Conv Layer로 거치지 않고 그대로 전달하는 Short Cut을 구성했다.

일반적으로 인풋에서 아웃풋을 거치고 다시 그 아웃풋이 인풋이 되는데, Short Cut은 이걸 거치지 않고 그대로 전달 해버리는 것이다.
그냥 전달된 x와 레이어를 거친 아웃풋을 합친 다음 ReLU를 거친다.
깊은 네트워크를 Identity layer로 구성한다면?
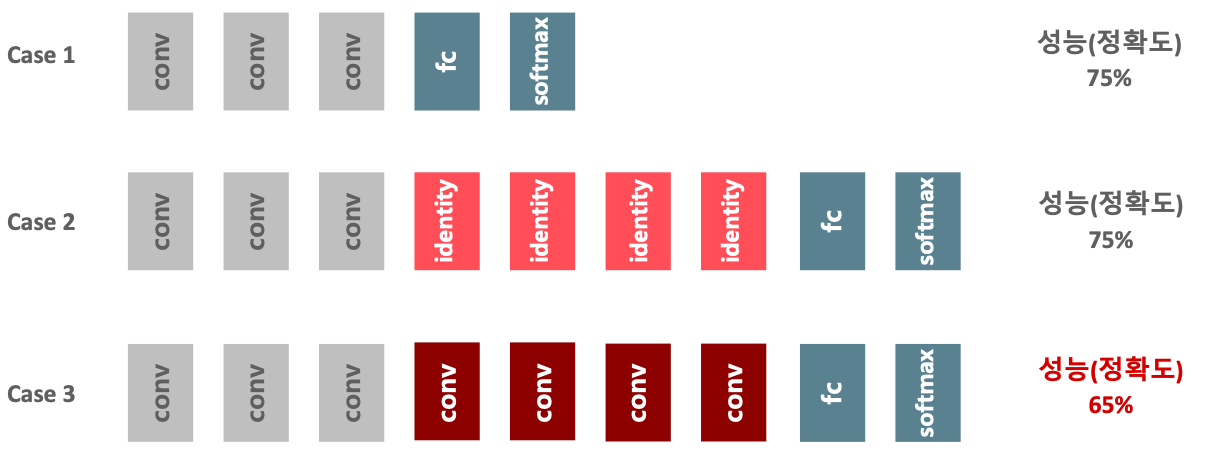
Case 1 Network에서 identity layer를 추가하여 Case 2와 같은 더 깊은 네트웍을 만들어도, 네트워크의 성능은 Case1과 동일하다.
하지만 Case 3와 같이 Conv layer로 더 깊은 네트웍을 만들면 성능은 오히려 저하한다.
그럼 Case 3의 Conv layer를 identity 역할을 하게 생성하면 어떻게 될까?
라는 가정으로 태어난 것이 ResNet 이다.
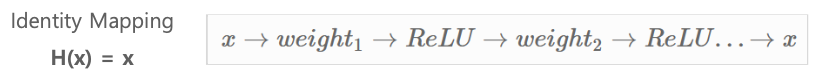
ReLU와 같은 비선형성 Layer로 인하여 identity mapping이 어렵다.
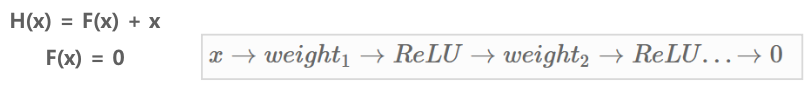
0을 학습하는 것이 상대적으로 쉽다. (weight를 0으로 한다.)
H(x) = x 를 학습하는 것보다 H(x) - x = F(x) 를 학습하는게 훨씬 쉽다.
ResNet - Residual Learning & Identity Mapping

기존 Network의 목표는 입력값 X를 타겟값 Y로 최적으로 매핑할 수 있는 함수 H(X)를 찾는 것이다.
따라서 H(X)–Y가 최소값이 되는 방향으로 학습을 진행하면서 H(X)를 찾는다.
H(x) = F(x) + x 에서 H(x)가 아니라 F(x)를 최적화되게 학습 할 수 있는 방법을 찾아보자.
그러면 F(x) = H(x) – x를 최소화 할 수 있도록 학습해야 한다.
F(x)는 '잔차' 처럼 보여서 Residual learning으로 구성된 Network이고, 그렇기 때문에 ResNet이라 불린다.
F(x)는 원 매핑 함수에서 입력 값의 차이이므로 F(x)는 잔차(Residual) 함수이다.
이 F(x)를 최소화 하는 학습이 바로 Residual Learning이다.
이때 F(x)를 0으로 매핑 될 수 있도록, 즉 H(x) = x 인 identity mapping 이 될 수 있도록 학습한다면, 더 깊은 네트워크를 효율적으로 구성할 수 있다는 것이 ResNet의 주요 아이디어이다.
ResNet은 F(x)가 0이 되도록, 즉 H(x) = x와 같이 identity mapping이 될 수 있도록 한다.
F(x) + x = H(x) 이므로 미분해도 F(x) + x의 미분값은 최소 1로 Vanishing Gradient 현상을 극복할 수 있다.
F(x)가 0으로 학습되면, 단순히 0이 되는 것이 아니라 0으로 학습하면서 기존 CNN과 유사하게 입력값의 비선형적인 특성을 학습한다.
0으로 최적 수렴하는 것이 깊은 네트워크에서 최소 Loss 최적화를 더 빠르고 효율적으로 수행 가능하다.

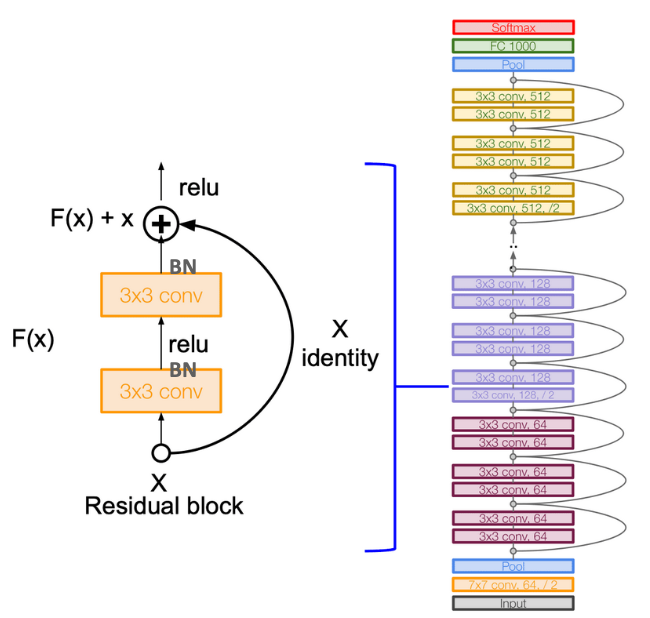
ResNet 구조
- 여러 개의 Residual Block이 연결되어 구성되어 있다.
- Residual Block = Conv(3x3) → BN → ReLU → Conv(3x3) → BN → Add(F(x) + x(identity)) → ReLU
- 이전 입력 값이 Skip Connection을 통해서 Conv Residual block을 skip 해서 output으로 Direct하게 연결된다.
- Residual Block 과 이전 입력 값(Identity Mapping)을 더한(Add) 뒤에 다시 Relu 적용
- Residual block 내에서는 기본적으로 두개의 3X3 Conv Layer를 가짐.
- Residual Block 내에서 CNN 커널은 동일한 크기와 동일한 Depth(필터 수)를 유지한다(1x1을 적용하지 않을 경우).
- 연속된 Residual block(ResNet 50 기준 3, 4 또는 6회) 이후에는 커널 크기는 절반, Depth(필터 수)는 2배로 변화하면서 Residual block들을 순차적으로 구성

입력으로 들어온 256차원의 input을 1x1 Conv로 차원 압축을 한다. 그래야 연산량도 줄고 파라미터 개수도 줄기 때문이다.
줄어든 만큼 3x3 Conv 연산을 하고 나서 다시 1x1 Conv을 필터수 256개로 다시 연산해준다.
ResNet 50을 포함한 깊은 네트워크(50/101/152)에서는 1x1 Conv을 통한 Bottleneck Layer를 이용하여 Parameter 갯수를 효과적으로 줄인다.

FLOPs : 연산량
ResNet 구조 비교

VGG의 3x3 Conv 연산 정신을 계승함.
VGG의 레이어 깊이의 한계를 34까지 늘림.
Identity block 생성
from tensorflow.keras.layers import Conv2D, Dense, BatchNormalization, Activation
from tensorflow.keras.layers import add, Add
# identity block은 shortcut 단에 conv layer가 없는 block 영역
def identity_block(input_tensor, middle_kernel_size, filters, stage, block):
'''
함수 입력 인자 설명
input_tensor는 입력 tensor
middle_kernel_size 중간에 위치하는 kernel 크기. identity block내에 있는 두개의 conv layer중 1x1 kernel이 아니고, 3x3 kernel임.
3x3 커널이 이외에도 5x5 kernel도 지정할 수 있게 구성.
filters: 3개 conv layer들의 filter개수를 list 형태로 입력 받음. 첫번째 원소는 첫번째 1x1 filter 개수, 두번째는 3x3 filter 개수, 세번째는 마지막 1x1 filter 개수
stage: identity block들이 여러개가 결합되므로 이를 구분하기 위해서 설정. 동일한 filter수를 가지는 identity block들을 동일한 stage로 설정.
block: 동일 stage내에서 identity block을 구별하기 위한 구분자
'''
# filters로 list 형태로 입력된 filter 개수를 각각 filter1, filter2, filter3로 할당.
# filter은 첫번째 1x1 filter 개수, filter2는 3x3 filter개수, filter3는 마지막 1x1 filter개수
filter1, filter2, filter3 = filters
# conv layer와 Batch normalization layer각각에 고유한 이름을 부여하기 위해 설정. 입력받은 stage와 block에 기반하여 이름 부여
conv_name_base = 'res' + str(stage) + block + '_branch'
bn_name_base = 'bn' + str(stage) + block + '_branch'
# 이전 layer에 입력 받은 input_tensor(함수인자로 입력받음)를 기반으로 첫번째 1x1 Conv->Batch Norm->Relu 수행.
# 첫번째 1x1 Conv에서 Channel Dimension Reduction 수행. filter1은 입력 input_tensor(입력 Feature Map) Channel 차원 개수의 1/4임.
x = Conv2D(filters=filter1, kernel_size=(1, 1), kernel_initializer='he_normal', name=conv_name_base+'2a')(input_tensor)
# Batch Norm적용. 입력 데이터는 batch 사이즈까지 포함하여 4차원임(batch_size, height, width, channel depth)임
# Batch Norm의 axis는 channel depth에 해당하는 axis index인 3을 입력.(무조건 channel이 마지막 차원의 값으로 입력된다고 가정. )
x = BatchNormalization(axis=3, name=bn_name_base+'2a')(x)
# ReLU Activation 적용.
x = Activation('relu')(x)
# 두번째 3x3 Conv->Batch Norm->ReLU 수행
# 3x3이 아닌 다른 kernel size도 구성 가능할 수 있도록 identity_block() 인자로 입력받은 middle_kernel_size를 이용.
# Conv 수행 출력 사이즈가 변하지 않도록 padding='same'으로 설정. filter 개수는 이전의 1x1 filter개수와 동일.
x = Conv2D(filters=filter2, kernel_size=middle_kernel_size, padding='same', kernel_initializer='he_normal', name=conv_name_base+'2b')(x)
x = BatchNormalization(axis=3, name=bn_name_base+'2b')(x)
x = Activation('relu')(x)
# 마지막 1x1 Conv->Batch Norm 수행. ReLU를 수행하지 않음에 유의.
# filter 크기는 input_tensor channel 차원 개수로 원복
x = Conv2D(filters=filter3, kernel_size=(1, 1), kernel_initializer='he_normal', name=conv_name_base+'2c')(x)
x = BatchNormalization(axis=3, name=bn_name_base+'2c')(x)
# Residual Block 수행 결과와 input_tensor를 합한다.
x = Add()([input_tensor, x])
# 또는 x = add([x, input_tensor]) 와 같이 구현할 수도 있음.
# 마지막으로 identity block 내에서 최종 ReLU를 적용
x = Activation('relu')(x)
return x
위에서 생성한 identity_block()을 호출하여 어떻게 identity block이 구성되어 있는지 확인
from tensorflow.keras.layers import Input
from tensorflow.keras.models import Model
# input_tensor로 임의의 Feature Map size를 생성.
input_tensor = Input(shape=(56, 56, 256), name='test_input')
# input_tensor의 channel수는 256개임. filters는 256의 1/4 filter수로 차원 축소후 다시 마지막 1x1 Conv에서 256으로 복원
filters = [64, 64, 256]
# 중간 Conv 커널 크기는 3x3
kernel_size = (3, 3)
stage = 2
block = 'a'
# identity_block을 호출하고 layer들이 어떻게 구성되어 있는지 확인하기 위해서 model로 구성하고 summary()호출
output = identity_block(input_tensor, kernel_size, filters, stage, block)
identity_layers = Model(inputs=input_tensor, outputs=output)
identity_layers.summary()
input tensor (56, 56, 256) 이 들어갔을 때, 첫번째 Residual Block을 통과하게되면 Output도 똑같은 (56, 56, 256)으로 나온다. 그래야 Add가 될 수 있다.
identity block을 연속으로 이어서 하나의 Stage 구성.
- 아래는 input tensor의 크기가 feature map 생성시 절반으로 줄지 않음. input tensor의 크기가 절반으로 줄수 있도록 구성 필요.
- 동일한 Stage 내에서 feature map의 크기는 그대로 대신, block내에서 filter 개수는 변화
input_tensor = Input(shape=(56, 56, 256), name='test_input')
x = identity_block(input_tensor, middle_kernel_size=3, filters=[64, 64, 256], stage=2, block='a')
x = identity_block(x, middle_kernel_size=3, filters=[64, 64, 256], stage=2, block='b')
output = identity_block(x, middle_kernel_size=3, filters=[64, 64, 256], stage=2, block='c')
identity_layers = Model(inputs=input_tensor, outputs=output)
identity_layers.summary()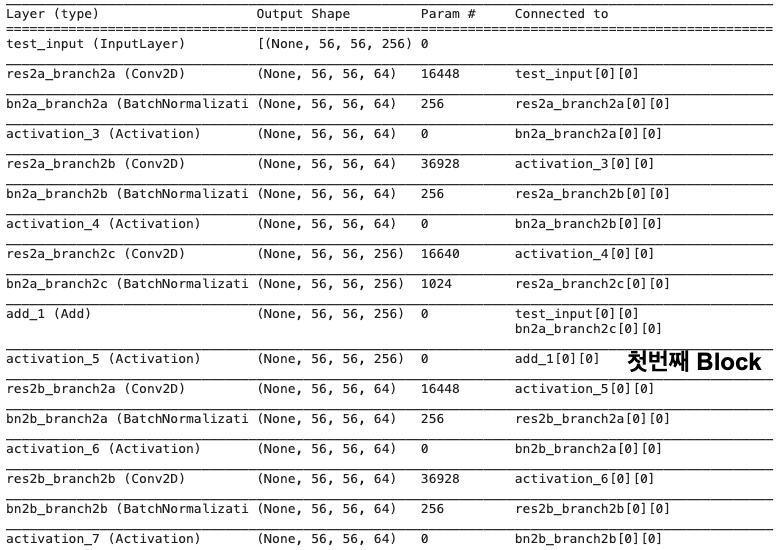

Block 안에서 입력 피쳐맵의 shape와 출력 피쳐맵의 shape가 같다는 것을 확인할 수 있다.
각 stage내의 첫번째 identity block에서 입력 feature map의 크기를 절반으로 줄이는 block을 생성하는 함수 conv_block() 만들기
- conv_block() 함수는 앞에서 구현한 identity_block()함수과 거의 유사하나 입력 feature map의 크기를 절반으로 줄이고 shortcut 전달시 1x1 conv stride 2 적용
- 단 첫번째 Stage의 첫번째 block에서는 이미 입력 feature map이 max pool로 절반이 줄어있는 상태이므로 다시 줄이지 않음.

Stride=2 를 통해서 줄인다.
####
주석 처리된 부분만 고치면 된다. 나머진 같다.
####
def conv_block(input_tensor, middle_kernel_size, filters, stage, block, strides=(2, 2)):
'''
함수 입력 인자 설명
input_tensor: 입력 tensor
middle_kernel_size: 중간에 위치하는 kernel 크기. identity block내에 있는 두개의 conv layer중 1x1 kernel이 아니고, 3x3 kernel임.
3x3 커널 이외에도 5x5 kernel도 지정할 수 있게 구성.
filters: 3개 conv layer들의 filter개수를 list 형태로 입력 받음. 첫번째 원소는 첫번째 1x1 filter 개수, 두번째는 3x3 filter 개수,
세번째는 마지막 1x1 filter 개수
stage: identity block들이 여러개가 결합되므로 이를 구분하기 위해서 설정. 동일한 filter수를 가지는 identity block들을 동일한 stage로 설정.
block: 동일 stage내에서 identity block을 구별하기 위한 구분자
strides: 입력 feature map의 크기를 절반으로 줄이기 위해서 사용. Default는 2이지만,
첫번째 Stage의 첫번째 block에서는 이미 입력 feature map이 max pool로 절반이 줄어있는 상태이므로 다시 줄이지 않기 위해 1을 호출해야함
'''
# filters로 list 형태로 입력된 filter 개수를 각각 filter1, filter2, filter3로 할당.
# filter은 첫번째 1x1 filter 개수, filter2는 3x3 filter개수, filter3는 마지막 1x1 filter개수
filter1, filter2, filter3 = filters
# conv layer와 Batch normalization layer각각에 고유한 이름을 부여하기 위해 설정. 입력받은 stage와 block에 기반하여 이름 부여
conv_name_base = 'res' + str(stage) + block + '_branch'
bn_name_base = 'bn' + str(stage) + block + '_branch'
# 이전 layer에 입력 받은 input_tensor(함수인자로 입력받음)를 기반으로 첫번째 1x1 Conv->Batch Norm->Relu 수행.
# 입력 feature map 사이즈를 1/2로 줄이기 위해 strides인자를 입력
########################################################################
x = Conv2D(filters=filter1, kernel_size=(1, 1), strides=strides, kernel_initializer='he_normal', name=conv_name_base+'2a')(input_tensor)
########################################################################
# Batch Norm적용. 입력 데이터는 batch 사이즈까지 포함하여 4차원임(batch_size, height, width, channel depth)임
# Batch Norm의 axis는 channel depth에 해당하는 axis index인 3을 입력.(무조건 channel이 마지막 차원의 값으로 입력된다고 가정. )
x = BatchNormalization(axis=3, name=bn_name_base+'2a')(x)
# ReLU Activation 적용.
x = Activation('relu')(x)
# 두번째 3x3 Conv->Batch Norm->ReLU 수행
# 3x3이 아닌 다른 kernel size도 구성 가능할 수 있도록 identity_block() 인자로 입력받은 middle_kernel_size를 이용.
# Conv 수행 출력 사이즈가 변하지 않도록 padding='same'으로 설정. filter 개수는 이전의 1x1 filter개수와 동일.
x = Conv2D(filters=filter2, kernel_size=middle_kernel_size, padding='same', kernel_initializer='he_normal', name=conv_name_base+'2b')(x)
x = BatchNormalization(axis=3, name=bn_name_base+'2b')(x)
x = Activation('relu')(x)
# 마지막 1x1 Conv->Batch Norm 수행. ReLU를 수행하지 않음에 유의.
# filter 크기는 input_tensor channel 차원 개수로 원복
x = Conv2D(filters=filter3, kernel_size=(1, 1), kernel_initializer='he_normal', name=conv_name_base+'2c')(x)
x = BatchNormalization(axis=3, name=bn_name_base+'2c')(x)
# shortcut을 1x1 conv 수행, filter3가 입력 feature map의 filter 개수
shortcut = Conv2D(filter3, (1, 1), strides=strides, kernel_initializer='he_normal', name=conv_name_base+'1')(input_tensor)
shortcut = BatchNormalization(axis=3, name=bn_name_base+'1')(shortcut)
# Residual Block 수행 결과와 1x1 conv가 적용된 shortcut을 합한다.
x = add([x, shortcut])
# 마지막으로 identity block 내에서 최종 ReLU를 적용
x = Activation('relu')(x)
return xconv_block()과 identity_block()을 호출하여 stage 구성.
input_tensor = Input(shape=(56, 56, 256), name='test_input')
# conv_block() 호출 시 strides를 2로 설정하여 입력 feature map의 크기를 절반으로 줄임. strides=1이면 크기를 그대로 유지
x = conv_block(input_tensor, middle_kernel_size=3, filters=[64, 64, 256], strides=2, stage=2, block='a')
x = identity_block(x, middle_kernel_size=3, filters=[64, 64, 256], stage=2, block='b')
output = identity_block(x, middle_kernel_size=3, filters=[64, 64, 256], stage=2, block='c')
identity_layers = Model(inputs=input_tensor, outputs=output)
identity_layers.summary()ResNet50 모델 생성
- 앞에서 생성한 conv_block()과 identity_block()을 호출하여 ResNet 50 모델 생성.
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense , Conv2D , Dropout , Flatten , Activation, MaxPooling2D , GlobalAveragePooling2D
from tensorflow.keras.optimizers import Adam , RMSprop
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.callbacks import ReduceLROnPlateau , EarlyStopping , ModelCheckpoint , LearningRateScheduler
def create_resnet(in_shape=(224, 224, 3), n_classes=10):
input_tensor = Input(shape=in_shape)
#첫번째 7x7 Conv와 Max Polling 적용.
x = do_first_conv(input_tensor)
# stage 2의 conv_block과 identity block 생성. stage2의 첫번째 conv_block은 strides를 1로 하여 크기를 줄이지 않음.
x = conv_block(x, 3, [64, 64, 256], stage=2, block='a', strides=(1, 1))
x = identity_block(x, 3, [64, 64, 256], stage=2, block='b')
x = identity_block(x, 3, [64, 64, 256], stage=2, block='c')
# stage 3의 conv_block과 identity block 생성. stage3의 첫번째 conv_block은 strides를 2(default)로 하여 크기를 줄임
x = conv_block(x, 3, [128, 128, 512], stage=3, block='a')
x = identity_block(x, 3, [128, 128, 512], stage=3, block='b')
x = identity_block(x, 3, [128, 128, 512], stage=3, block='c')
x = identity_block(x, 3, [128, 128, 512], stage=3, block='d')
# stage 4의 conv_block과 identity block 생성. stage4의 첫번째 conv_block은 strides를 2(default)로 하여 크기를 줄임
x = conv_block(x, 3, [256, 256, 1024], stage=4, block='a')
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='b')
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='c')
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='d')
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='e')
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='f')
# stage 5의 conv_block과 identity block 생성. stage5의 첫번째 conv_block은 strides를 2(default)로 하여 크기를 줄임
x = conv_block(x, 3, [512, 512, 2048], stage=5, block='a')
x = identity_block(x, 3, [512, 512, 2048], stage=5, block='b')
x = identity_block(x, 3, [512, 512, 2048], stage=5, block='c')
# classification dense layer와 연결 전 GlobalAveragePooling 수행
x = GlobalAveragePooling2D(name='avg_pool')(x)
x = Dropout(rate=0.5)(x)
x = Dense(200, activation='relu', name='fc_01')(x)
x = Dropout(rate=0.5)(x)
output = Dense(n_classes, activation='softmax', name='fc_final')(x)
model = Model(inputs=input_tensor, outputs=output, name='resnet50')
model.summary()
return model
model = create_resnet(in_shape=(224,224,3), n_classes=10)
ResNet50 Pretrained 모델 학습
from tensorflow.keras.applications import ResNet50
input_tensor = Input(shape=(128, 128, 3))
base_model = ResNet50(include_top=False, weights=None, input_tensor=input_tensor)
bm_output = base_model.output
# classification dense layer와 연결 전 GlobalAveragePooling 수행
x = GlobalAveragePooling2D(name='avg_pool')(bm_output)
x = Dropout(rate=0.5)(x)
x = Dense(200, activation='relu', name='fc_01')(x)
x = Dropout(rate=0.5)(x)
output = Dense(10, activation='softmax', name='fc_final')(x)
pr_model = Model(inputs=input_tensor, outputs=output, name='resnet50')
pr_model.summary()
pr_model.compile(optimizer=Adam(lr=0.0001), loss='categorical_crossentropy', metrics=['accuracy'])
history = pr_model.fit(tr_ds, epochs=30,
validation_data=val_ds,
callbacks=[rlr_cb, ely_cb]
)
test_ds = CIFAR_Dataset(test_images, test_oh_labels, batch_size=BATCH_SIZE, augmentor=None, shuffle=False, pre_func=resnet_preprocess)
pr_model.evaluate(test_ds)
'🖼 Computer Vision > CNN' 카테고리의 다른 글
| CNN - Fine Tuning (0) | 2022.04.05 |
|---|---|
| CNN - EfficientNet (0) | 2022.04.04 |
| CNN - GoogLeNet (0) | 2022.04.01 |
| CNN - VGGNet (0) | 2022.04.01 |
| CNN - AlexNet (0) | 2022.03.31 |