
📌 이 글은 권철민 님의 딥러닝 CNN 완벽가이드를 바탕으로 작성한 포스팅입니다.
목차
- EfficientNet
- EfficientNetB0 구조
- Keras의 EfficientNet Pretrained 모델
EfficientNet
네트워크의 깊이(Depth), 필터 수(Width), 이미지 Resolution 크기를 최적으로 조합하여 모델의 성능을 극대화했다.

- 필터 수(Width) : 너비라고 표현하기도 한다. Conv2D()의 맨 처음 파라미터로 적는다. 기본 필터는 보통 3by3 크기의 커널에 256개 이다. 필터 수가 많으면 너비가 넓어질 수 밖에 없다.
- 깊이(Depth) : weight 층이 있는 레이어가 몇개인가? 깊이는 곧 레이어의 개수이다.
- 이미지 Resolution : 말그대로 이미지의 해상도이다.
이 세개를 적절히 결합하면 최적의 모델을 만들 수 있다고 생각해서 나온게 바로 EfficientNet 이다.

적은 파라미터 수, 적은 연산 수 대비 상대적으로 타 모델 대비 높은 예측 정확도를 나타낸다.(2019년 기준)
허나 실제 연산해보면 그렇게까지 빨리 나오진 않는다고 한다.
Compound Scaling 적용
- 이미지 해상도가 높을 경우, 더 큰 Receptive field가 더 많은 픽셀을 포함하는 비슷한 피처들을 잘 Capture 할 수 있다.
- 더 많은 필터 수를 가지면 높은 이미지 해상도의 많은 픽셀들에 대해서 세밀한 패턴을 잘 Capture 할 수 있음.
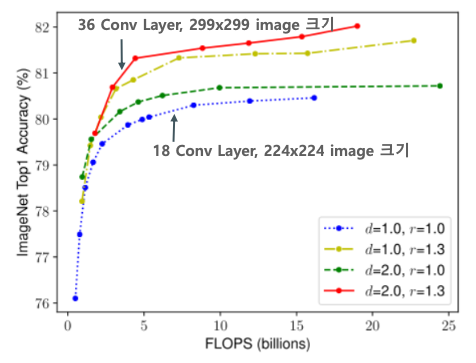
- depth(레이어 개수)와 resolution을 각각 1.0으로 고정하고 width(필터 수)만 증가시켰을 때 정확도 성능은 80%에서 수렴한다.
- depth(레이어 개수)를 2.0, resolution은 2.0으로 했을 경우 width(필터 수)만 변화시키면 비슷한 FLOPS상에서 더 나은 성능을 보인다.
최적의 Scaling 도출 식
depth, width, resolution에 따른 FLOPS 변화를 기반으로 최적의 식을 도출한다.
width, resolution은 2배가 되면 FLOPS는 4배가 된다.(그래서 제곱을 곱한다)

- 3가지 Scaling Factor를 동시 고려하는 Compound Scaling을 적용한다.
- 최초에는 𝝋를 1로 고정하고 grid search 기반으로 𝛼, 𝛽, 𝛾의 최적 값을 찾아낸다. EfficientNetB0의 경우 𝛼 = 1.2, 𝛽 = 1.1, 𝛾 = 1.15
- 다음으로 𝜶, 𝜷, 𝜸을 고정하고 𝜑을 증가 시켜가면서 EfficientB1~ B7까지 Scale up 구성
EfficientNetB0 구조

224x224 로 들어간다.
stride=2를 먹고 절반으로 줄어든다.
MBConv Block은 MobileNetV2랑 비슷하다
Block이 연속적으로 이어져 있다.
ResNet과도 비슷하다.
B1~B7은 B0에서 Depth, Width를 증가시켜서 만든 모델이다.
Depth는 기존 Block의 개수를 증가시켰다.
Width는 기존 Filter 수를 증가시켰다.


Keras의 EfficientNet Pretrained 모델
model = EfficientNetB0(include_top=False, weights='imagenet')
B7로 갈수록 성능이 좋아지긴 한다. 하지만 해상도도 준비가 되어야 한다. 그에 맞는 하드웨어도 맞아야 한다.
그리고 학습속도도 느려진다.
준비해야 될 사항이 많다.
각 버전에 따라서 가급적 해상도를 맞춰주어야 한다.
'🖼 Computer Vision > CNN' 카테고리의 다른 글
| CNN - Keras LearningRageScheduler (0) | 2022.04.06 |
|---|---|
| CNN - Fine Tuning (0) | 2022.04.05 |
| CNN - ResNet (0) | 2022.04.02 |
| CNN - GoogLeNet (0) | 2022.04.01 |
| CNN - VGGNet (0) | 2022.04.01 |