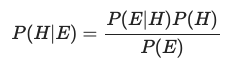
베이즈 정리의 의미
2021. 5. 29. 15:38
✏️ Mathemathics/Statistics and Probability
기본적으로 활용되는 베이즈 정리에 대해 알아보자. 우선 베이즈 정리의 공식부터 확인해보도록 하자. 총 네 개의 확률값이 적혀져 있으며, 생김새도 거의 비슷비슷해 그냥 보기에는 의미를 파악하기가 어렵다. P(H) : 사전 확률 P(H|E) : 사후 확률 네 개의 확률 값 중 P(H)와 P(H|E)는 각각 사전 확률, 사후 확률이라고 부른다. 베이즈 정리는 근본적으로 사전확률과 사후확률 사이의 관계를 나타내는 정리이다. 그렇다면, 우리는 사전확률과 사후확률의 의미를 파악함으로써 베이즈 정리가 말하는 바와 그 의의를 이해할 수 있을 것이다. 베이즈 정리를 이해하기 어려웠던 이유 베이즈 정리를 이해함에 있어서 가장 먼저 정리해야 할 개념은 ‘확률’에 관한 관점이다. 베이즈 정리의 의미를 이해하기 어려운 이유 중..
최대우도법
2021. 5. 29. 13:45
✏️ Mathemathics/Statistics and Probability
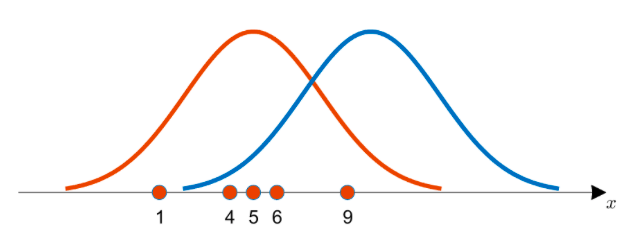
최대우도법 최대우도법(Maximum Likelihood Estimation, 이하 MLE)은 모수적인 데이터 밀도 추정 방법이다. 다양한 파라미터 θ=(θ1,⋯,θm)으로 구성된 어떤 확률밀도함수 P(x|θ)에 대해서 관찰하고 표본 데이터 집합을 x=(x1,x2,⋯,xn)이라 할 때, 이 표본들에서 파라미터 θ=(θ1,⋯,θm)를 추정하는 방법이다. 당연히, 이 말만 보면 MLE가 뭔지 이해하기는 불가능하기 때문에 예시를 들어 MLE에 대해 알아보도록 하자. 위와 같이 5개의 데이터 {1, 4, 5, 6, 9} 를 얻었다고 하자. 이 데이터를 어떤 분포로 부터 얻었을까? 를 알고 싶다. 주황색 분포, 파란색 분포 중 어떤 데이터에서 얻었을까? 아마 주황색 분포가 좀더 가능성이 있을 것이다. 그럼 이것을 ..
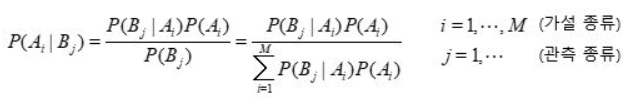
사전 확률과 사후 확률
2021. 5. 29. 13:21
✏️ Mathemathics/Statistics and Probability
사전 확률 ( Prior Probability ) 현재 가지고 있는 정보를 기초로하여 정한 초기 확률 확률 시행 전에 이미 가지고 있는 지식을 통해 부여한 확률 ex) 동전을 던져 앞면이 나올 확률 : 1/2 사후 확률 ( Posteriori Probability) 사건 발생 후에 어떤 원인으로부터 일어난 것이라고 생각되어지는 확률 추가된 정보로부터 사전정보를 새롭게 수정한 확률 ( 수정 확률 ) 조건부 확률을 통해 사후 확률을 표현할 수 있음 사후확률은 베이즈 정리로 부터 구할 수 있다. 사후 확률의 계산 => 베이즈 정리 사후확률 P(A|B)을 사전확률 P(A),P(B) 및 조건부확률 P(B|A)로 표현할 수 있음 - 여기서 P(Ai|Bj)는 사후확률 B는 관측, A는 원인, 즉, 관측 B를 보고 원..
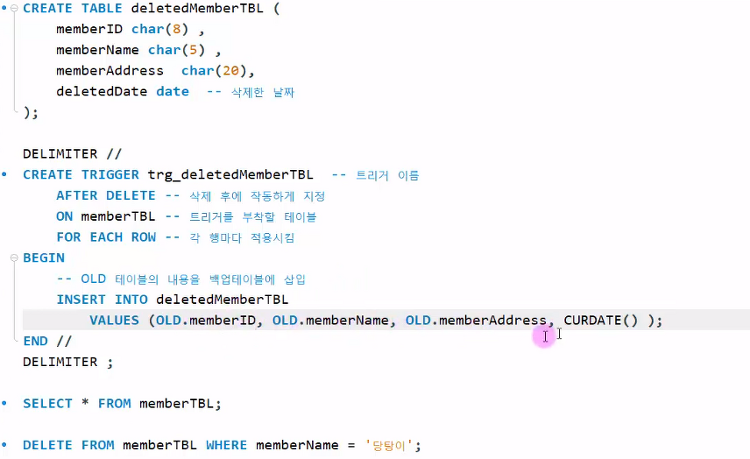
데이터베이스 - View, Trigger
2021. 5. 24. 14:57
🚛 Database/Database
https://www.youtube.com/watch?v=V5GN2FMBl4w

ML W11-2 - Visualizing Model Performance
2021. 5. 15. 14:45
💡 AI/ML
Profit Curve 모든 컨디션은 불확실하고 안정되어 있지 않다. 따라서 다양한 모델을 만들어봐야 조합해 봐야한다. Tree 썼을 때 가장 큰 profit ROC ROC(Receiver Operating Characteristic) curve는 다양한 threshold에 대한 이진분류기의 성능을 한번에 표시한 것이다. 이진 분류의 성능은 True Positive Rate와 False Positive Rate 두 가지를 이용해서 표현하게 된다. ROC curve를 한 마디로 이야기하자면 ROC 커브는 좌상단에 붙어있는 커브가 더 좋은 분류기를 의미한다고 생각할 수 있다. x축 False Positive, y축 True Positive “Positive”의 의미는 판단자가 “그렇다”라고 판별했다는 의미이..
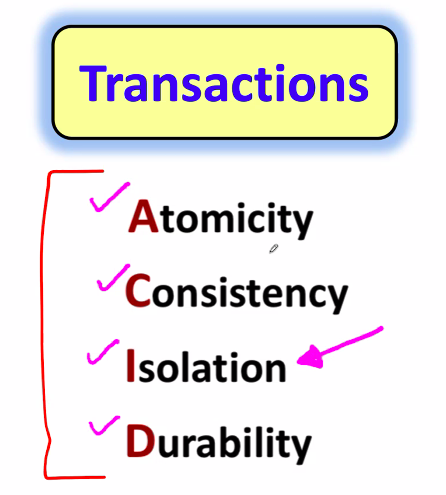
데이터베이스 - Transaction
2021. 5. 12. 14:58
🚛 Database/Database
트랜잭션의 특성 Atomicity = all or nothing : 한 트랜잭션 내의 모든 연산들이 완전히 수행되거나 전혀 수행되지 않음 Consistency : 트랜잭션이 수행된 후에도 데이터베이스가 그 전과 같은 일관된 상태를 가진다. "동시에 여러 사용자가 같은 데이터에 접근하려고 할 때" 발생하는 상황 Isolation : 한 트랜잭션이 데이터를 갱신하는 동안 이 트랜잭션이 완료되기 전까지 다른 트랜잭션이 접근하지 못하도록 한다. Durability : 갱신한 후에 시스템이 고장나더라도 갱신된 데이터들은 쭉 지속되어야 한다. Commit : 트랜잭션의 완료 Abort : 트랜잭션의 철회 = Rollback : 초기상태로 복귀 동시성 제어 serial schedule (직렬 스케줄) : 여러 트랜잭..

데이터베이스 - Relation design (1NF, 2NF, 3NF, BCNF)
2021. 5. 10. 14:54
🚛 Database/Database
Database anomaly(=데이터베이스 이상현상) 1. update anomaly(=갱신 이상) - 하나 바꾸려면 다 바꿔야함 - 데이터 갱신시 일관성 유지가 안되는 현상, 데이터 불일치(=inconsistency)발생 - 최유정 학생이 연락처를 변경하는 경우 B01, C01 튜플의 정보를 수정해야 하는데 1개의 튜플만 수정할 경우 발생 2. insert anomaly(=삽입 이상) - 어떤 속성 값을 넣지 않는 이상 삽입이 불가능 - 튜플 삽입시 지정하지 않은 속성값이 NULL을 갖는 현상 - 1604 홍길동 010-7777-3333 학생이 있으나 아직 수강하는 과목이 존재하지 않는 경우에는 과목코드에 NULL값이 저장되는 현상 3. delete anomaly(=삭제 이상) - 연쇄 삭제에 의한 ..

무자비한 알고리즘 - 카타리나 츠바이크
2021. 5. 10. 14:22
📌 Book
2002년 대니얼 카너먼(Daniel Kahneman)이 인간의 비합리성에 대한 연구로, 2017년 리처드 탈러가 '넛지 Nudge'에 대한 연구로 노벨상을 수상한 이래 우리는 인간을 굉장히 비합리적이고 조작당하기 쉬운 존재로, 주관적이고 편파적인 존재로 여기게 되었다. 물론 우리 각자는 자신보다 타인을 더 비합리적이라고 여긴다. 타인이 자신의 개성이나 복합성을 잘못 판단하는 경우를 곧잘 겪기 때문이다. 자연과학 전공 커리큘럼에 통계학이나 과학 이론이 누락되어 있는 것이 자못 위험한 학문적 공백을 초래하고 있다고 본다. 이 책은 독자들에게 컴퓨터가 인간에 대해 판단할수 있는지, 현재로서 그 일을 그리 잘 할 수 없는 이유가 무엇인지, 그것을 어떻게 개선시킬 수 있는지를 보여줄 것이다. 인공지능의 목표 :..

데이터 모델링
2021. 5. 4. 21:43
🚛 Database/SQL
Entity Entity 유형이 될 수 있는 조건 Entity example 관계, 관계 유형 관계 유형 방향성 관계 연결, 관계 군 속성, 속성 유형 (Attribute type) 여러개의 속성 유형으로 강사를 표현한다. 각 속성 유형은 속성 값을 갖는다. 속성 유형 종류 속성 유형 중복을 조심해야 한다. 식별자 결합해서 하나의 식별자를 만든다. 속성 유형값 정의 Cardinality Optionality (선택성) 고객은 때때로 주문을 발행한다. 주문은 항상 고객이 발행할 때만 발행 된다. 엔티티 관계도 작성 정규화

데이터베이스 - Primary key, Alternate key
2021. 4. 30. 11:11
🚛 Database/Database
식별자(Identifier)란? 한 실체(Entity)내에서 각각의 인스턴스를 유일하게 구분할 수 있는 단일 속성 또는 그룹 속성을 말한다. 실체 내에서 식별자에 동일한 값이 중복될 수 없으며, 이를 실체 무결성이라고 한다. 모든 Entity는 반드시 하나 이상의 식별자를 보유해야 하며 여러 개의 식별자를 보유하는 경우도 있다. 주로 이 식별자를 통해 해당 인스턴스의 구분이 가능해지며 검색이나 조인시 매우 중요하게 작용한다. 후보키(Candidate Key) 실체(Entity) 내에서 각각의 인스턴스를 유일하게 구분할 수 있는 속성으로, 하나 또는 여러 개의 속성으로 구성된다. 즉, 기본키(PK)가 될 수 있는 후보 속성이다. 아래의 예에서는 '사번'과 '주민번호'가 후보키에 해당한다. 기본키(Prima..
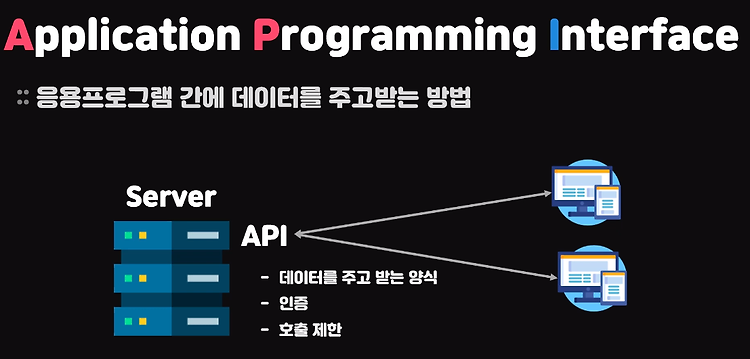
데이터베이스 - API
2021. 4. 14. 12:25
🚛 Database/Database

데이터베이스 - 내장 SQL (Embedded SQL), 커서 (Cursor)
2021. 4. 14. 10:45
🚛 Database/Database
응용프로그램(C, java, C# 등) 안에는 DB와 같은 명령어가 들어와야 한다. 따라서 Embedded SQL, 즉 내장 SQL이 된다. EXEC SQL 로 감싸서 사용 커서 : 데이터베이스 튜플을 쭉 가지고 왔는데 잘 가지고 왔니? 하면서 접근 하는 것 한번에 하나씩 이동하면서 처리할 수 있다. 1. 선언 2. 개방 3. 검색 4. 닫는다 1. declare 로 커서 선언 2. 여러개의 튜플들을 가져온다. 호스트 변수와 DB의 변수와 같은 것을 가져온다. open : 커서가 생성이 되었으니 개방을 한 다음에 이용한다. fetch : 커서에서 호스트 변수로 검색한다. close : 커서를 닫는다.

cs231n 4강 - Backpropagation
2021. 4. 12. 21:49
🖼 Computer Vision/CNN
Optimization은 Loss를 최소화 하는 과정이다. Loss가 최소가 되어야지만 좋은 prediction이 가능하다. 일반적으로 Gradient를 구하는 방법은 Numerical한 방법이다. 그러나 속도가 느리고 정확하지 않다. 따라서 해석적 방법인 Analytic 한 방법을 사용한다. 보통 gradient check를 할 때에는 Numerical gradient를 사용한다. x에 가중치(W)를 곱하여 score값을 function에 넣으면 loss를 얻는다. 그리고 그것을 regularization loss와 더해주는 것을 total loss라고 한다. 이런 과정을 Computational graph라고 한다. 예를 들어서 하나하나의 모듈 별로 계산을 해나가는 방식을 학습해보자. 간단한 함수인 ..

ML W6-1 Overfitting and Its Avoidance
2021. 4. 5. 13:10
💡 AI/ML
Why Is Overfitting Bad? (p.125) Need for holdout evaluation 어떻게 두개를 나눌 수 있을까? 어떻게 Classifiy 할 수 있을까? 단순하게 나눌려고 하기 때문에, memorizing 하려고 하기 때문에 오버피팅이 생기는 것이다. Over-fitting 점점 노드가 많아질수록 변수가 많아지고 specific한 값들이 나타나면서 오버피팅이 된다. 새로운 데이터들을 기억하게 되면서 오버피팅이 된다. 그러면 어떻게 퍼포먼스를 올릴 수 있을까? -> Holdout Holdout validation 주어진 데이터가 전부이다. 아무 데이터나 합치면 안된다. 데이터의 소스가 다르기 때문이다. Ref: m.blog.naver.com/ckdgus1433/2215995178..