

📌 이 글은 권철민님의 딥러닝 컴퓨터 비전 완벽 가이드 강의를 바탕으로 정리한 내용입니다.


목차
- YOLO - V1
- YOLO V1 개요
- YOLO V1 Prediction
- YOLO V1 Loss
- Bounding Box (x, y) 좌표 loss
- Bounding Box 너비(w), 높이(h) loss
- Object Confidence loss
- Classification loss
- NMS로 최종 Bounding Box 예측
- YOLO V1의 한계
- YOLO - V2
- YOLO V2 개요
- YOLO V2 Architecture
- 1개의 그리드 Cell이 가지고 있는 정보
- 크기가 서로 다른 Anchor Box 5개 - Direct Location Prediction
- YOLO V2 Loss
- Passthrough module을 통한 fine grained feature
- DarkNet-19
- YOLO - V3
- YOLO V3 개요
- SSD의 Multi-Scale Feature Layer + FPN
- 독립적인 여러개의 Sigmoid로 Multi-label Classification 해결
YOLO - V1
YOLO V1 개요
YOLO 버전 1 모델은 컨볼루션을 거친 Feature Map이 아닌 입력 이미지 자체를 특정 그리드 S x S로 나눈다. 그리고 나눈 그리드의 각 Cell 마다 Anchor Box를 2개씩 씌우고 이를 기반으로 Ground Truth와 비교를 하면서 Object Detection을 수행한다. 하나의 셀은 두개의 바운딩 박스를 기반으로 Object 하나를 예측한다. 하나의 그리드 Cell에 하나의 Object만 Detect 하므로 예측을 잘 못할 수 있다.
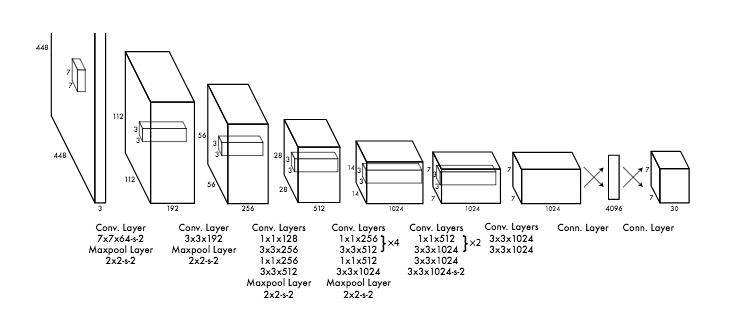
마지막에 7x7 Feature map을 뽑고 나서 3차원 Feature map을 Dense 하게 만든다. Classification, Regression 하기 위해서.
그리고 나서 다시 7x7x30 shape로 만든다.
YOLO V1 Prediction
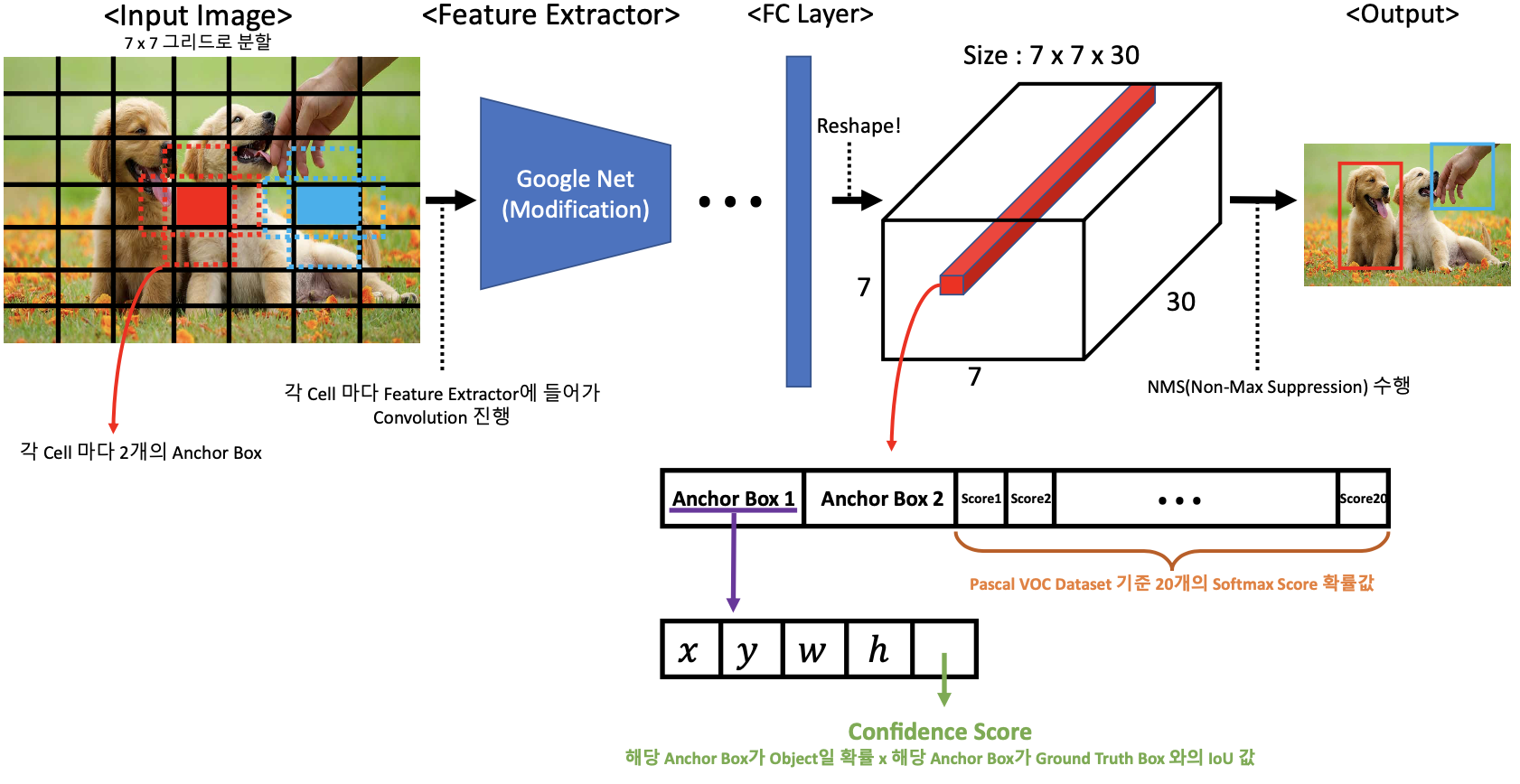
결과적으로 YOLO 버전 1 모델은 입력 이미지를 7 x 7 그리드로 나누고 나눈 각 Cell 당 하나의 Object Detection을 수행하고 그 결과를 통합해서 최종적인 Object Detection을 수행해주는 것이다.
위 자료의 빨간색 1 x 1 x 30 벡터를 설명해 놓은 부분을 보자.
하나의 Cell이 담당하는 Anchor Box가 2개가 있는데, 그 Anchor Box에서 예측을 한 것이다.
개별 Anchor Box 에 대한 정보는 5개가 있다. 4개는 중심 좌표(x, y), 너비(w), 높이(h) 이다. 마지막 1개는 Confidence score 이다.
이 Box가 2개가 있으므로 총 10개, 그리고 Pascal VOC Dataset 기준으로 클래스 종류가 20개이기 때문에 20개의 벡터, 이들을 합하면 총 30개의 벡터가 되는 것을 볼 수 있다.
이렇게 하나의 Cell 마다 Object Detection을 수행해주고 나면 수많은 Bounding Box들이 도출될 것이다.
그런데 2개의 Bounding Box면 Class 확률 값도 2개 있어야 하지 않나?
두개의 Bounding Box 중에서 Ground Truth와의 IOU가 가장 큰 Bounding Box에 대한 Class 확률 값이다.
이 때 Ground Truth와 최대한 유사한 최적의 Bounding Box들 만을 남기기 위해 NMS 과정을 수행해준다.
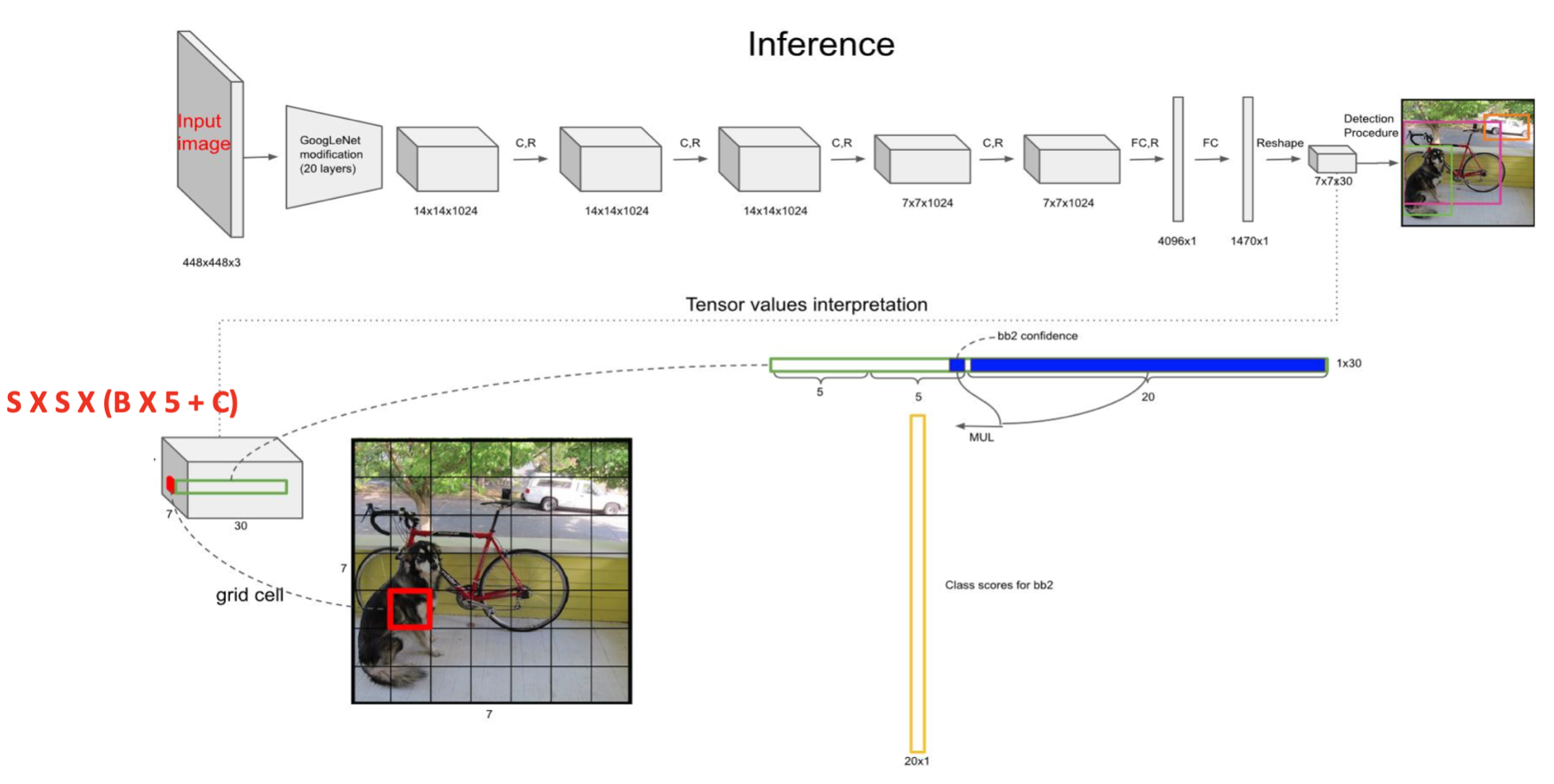
각 그리드 Cell 별로 아래를 계산한다.
- 2개의 Bounding Box 후보 좌표와 해당 Box별 Confidence Score
- x, y, w, h : 정규화 된 BBox의 중심 좌표와 너비 / 높이
- Confidence Score = 예측한 대상이 Object일 확률 x IOU 값
- 클래스 확률. Pascal VOC 기준 20개 클래스의 확률
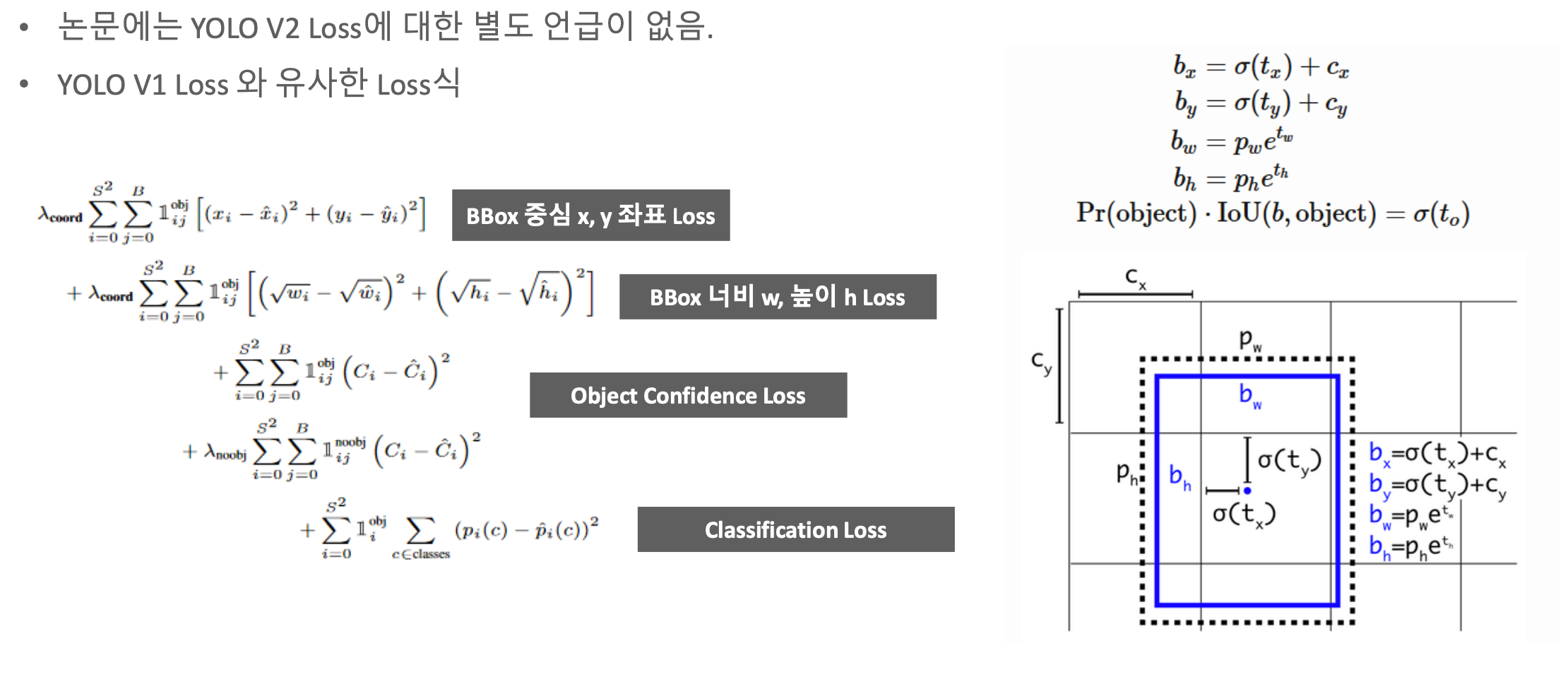
YOLO V1 Loss

Bounding Box (x, y) 좌표 loss

- 람다 = 5
- S = 그리드 Cell (모든 그리드를 계산하라)
- B = Bounding Box
- Xi (예측 좌표 x, y 값)와 Xi^ (Ground Truth 좌표 x, y값)의 오차 제곱을 기반으로 모든 Cell의 2개의 Bbox(98개 Bbox) 중에 예측 Bbox를 책임지는 Bbox 만 Loss 계산
- 1obj ij = 98개의 Bbox 중 오브젝트 예측을 책임지는 Bbox만 1 나머지는 0
Bounding Box 너비(w), 높이(h) loss
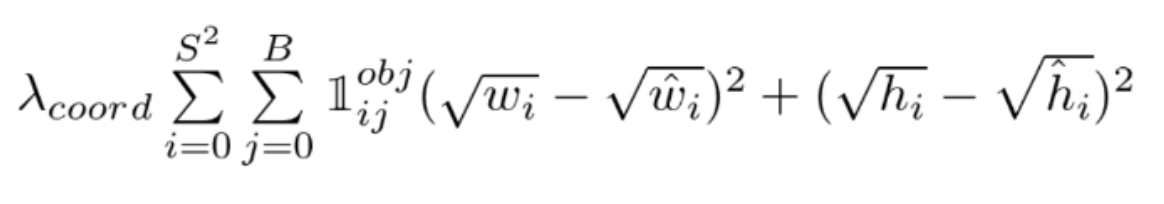
- 람다 = 5
- 예측 너비, 높이 값과 Ground Truth 너비, 높이 값의 오차 제곱을 기반으로 한다.
- 크기가 큰 오브젝트의 경우 오류가 상대적으로 커짐을 제약하기 위해서 제곱근을 취한다.
Object Confidence loss

- 람다 = 0.5
- Ci = Object일 확률 x IOU
- Ci^ = Ground Truth = 1
- 예측된 Object Confidence Score와 Ground Truth의 IOU의 예측 오차를 기반으로 한다.
- Object를 책임지는 Bbox confidence loss + Object가 없어야 하는 Bbox의 confidence loss
여기서 noobj는 선택되지 않은 2번째 Anchor Box가 아니라 선택된 Anchor Box를 제외한 모든 나머지 경우의 수라고 이해했다.
Classification loss
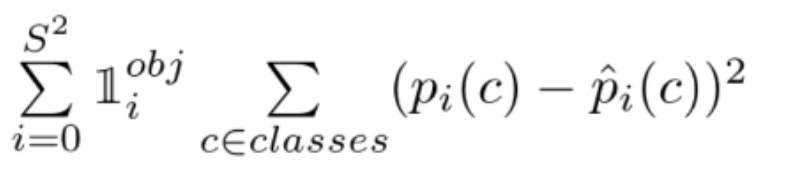
- 예측 classification 확률 오차의 제곱. Object를 책임지는 Bbox만 대상
NMS로 최종 Bounding Box 예측

- 특정 Confidence 값 이하는 모두 제거
- 가장 높은 Confidence값을 가진 순으로 Bbox 정렬
- 가장 높은 Confidence를 가진 Bbox와 IOU와 겹치는 부분이 IOU Threshold 보다 큰 Bbox는 모두 제거
- 남아 있는 Bbox에 대해 3번 Step을 반복
YOLO V1의 한계
하지만 YOLO 버전 1 모델은 치명적인 단점이 있다. 바로 그리드를 나눈 각 Cell 마다 Anchor Box가 2개밖에 없다는 것이다. 결국 Anchor Box가 2개라면 그만큼 ROI(Regions Of Interest, 객체가 있을만한 후보 영역)들이 적을 것이고 이는 결국 Object를 잘 탐지하지 못하게 되는 문제가 발생한다. 또한 입력 이미지를 그리드 셀로 나누고 각 Cell 마다 Object Detection을 수행하기 때문에 만약 하나의 그리드 Cell에 여러개 Object가 겹쳐있으면 단순히 하나의 Object로만 탐지하고 넘어간다는 것이다. 바로 하단의 사진처럼 말이다.

이렇게 객체들이 겹쳐있으면 여러마리의 물고기 중 하나의 물고기만 탐지하게 된다.
YOLO - V2
YOLO V2 개요
이제 YOLO 버전 2 모델을 살펴보자. 버전 1의 문제점을 해결하기 위해서 버전 2에서는 다음과 같은 특징들을 모델에 추가했다.
- 입력 이미지가 아닌 Feature Map에서 13 x 13 그리드로 나누고 각 Cell 마다 Object Detection을 수행
- 각 Cell 당 씌우는 Anchor Box 개수를 5개로 늘리기
- 예측 Bounding Box의 x, y 좌표가 중심 Cell에서 벗어나지 않도록 Direct Location Prediction 사용
- 동일한 이미지이지만 크기만 다르게 해서 모델을 학습(Multi-Scaling) : 학습 시 10개의 Batch 마다 입력 이미지 크기를 320x320 에서 608x608 까지 동적으로 변경(32배수로 커짐)
- 모델에 Batch Normalization(활성함수를 적용하기 이전의 출력 노드값에 Normalization을 적용해 학습 속도를 빠르게 해주는 방법) 적용
- High Resolution Classifier : 분류 모델을 Fine Tuning (416x416 → 448x448)
- Darknet-19 라는 개별의 Feature Extractor 사용
- Classification layer에서 FC layer를 삭제하고 Fully Convolution 으로 변경
버전 2 모델에서 주목해야 할 특징은 1번, 2번이 되겠다. 나머지 특징들은 읽기만 해도 이해가 될 것이다. 우선 기본적인 YOLO 버전 2의 아키텍처를 살펴보자.
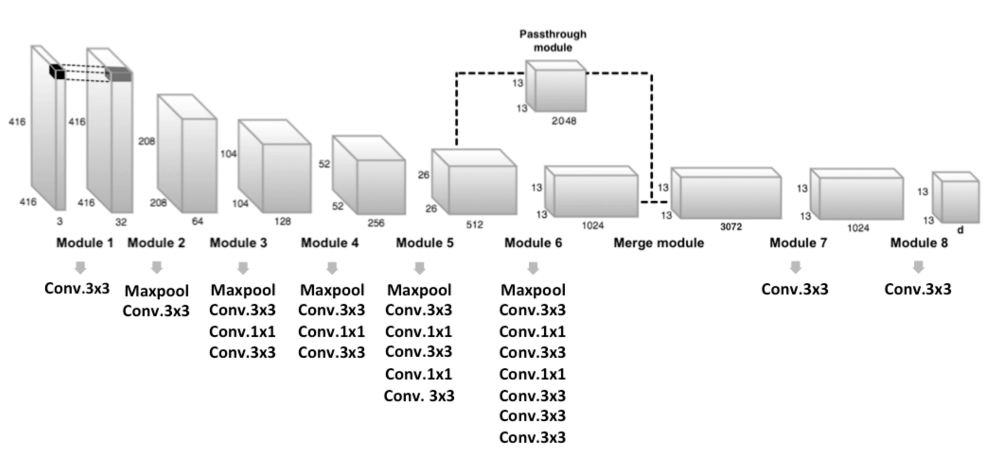
버전 1 모델과 두드러진 차이점은 FC Layer가 없어졌다는 점이다. 그리고 입력 데이터가 아닌 Feature Map에서 13 x 13 그리드로 나누고 각 Cell 마다 Object Detection을 수행한다는 점이다. 자, 이제 디테일하게 설명하는 자료를 살펴보자
YOLO V2 Architecture
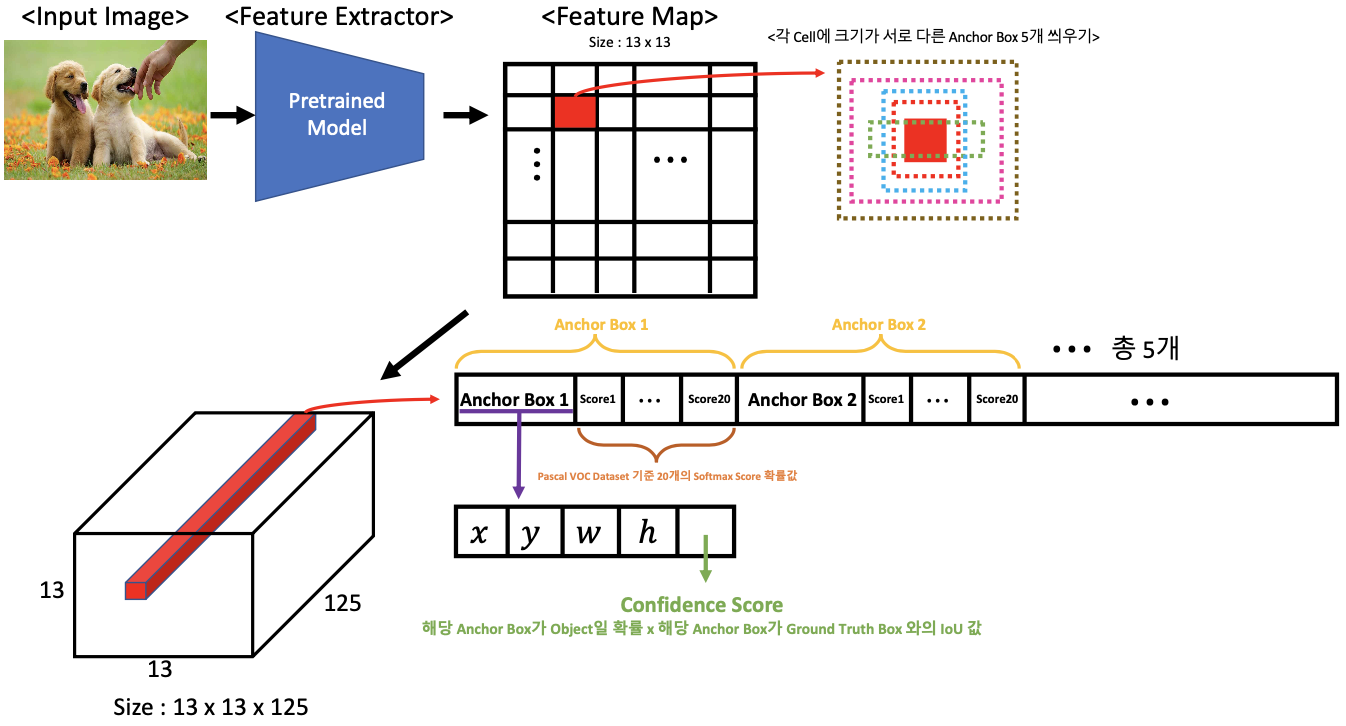
위 그림을 보다시피 전개되는 과정은 버전 1 모델과 유사하다. Feature Map에 그리드를 나눈다는 점과 각 그리드 Cell 마다 Anchor Box를 2개가 아닌 5개를 씌워준다는 점이 다르다. 그런데 여기서 Anchor Box를 5개 씌워줄 때 서로 다른 크기의 박스들을 씌워준다고 했다. 그러면 서로 다른 적절한 크기를 어떻게 설정해줄까?
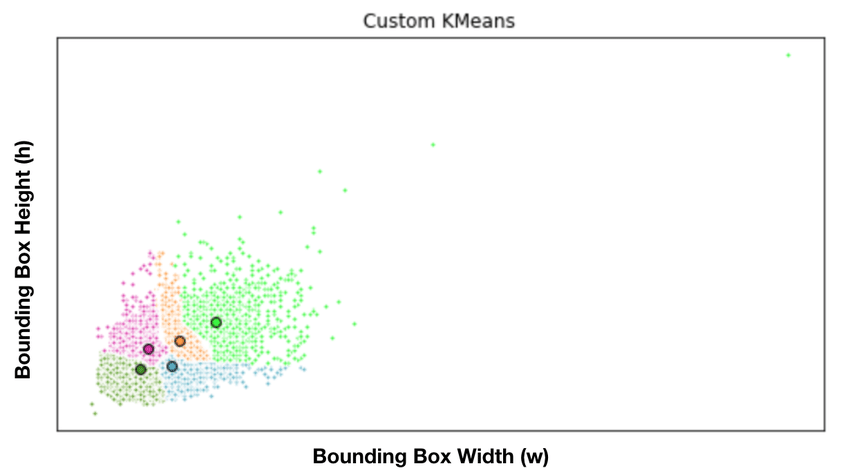
5개의 서로 다른 Anchor Box의 사이즈 기준은 입력되는 이미지 데이터의 Ground Truth의 Bouding Box를 분석해 비슷한 부분끼리 그룹핑되도록 K-means Clustering을 사용하게 된다.
1개의 그리드 Cell이 가지고 있는 정보
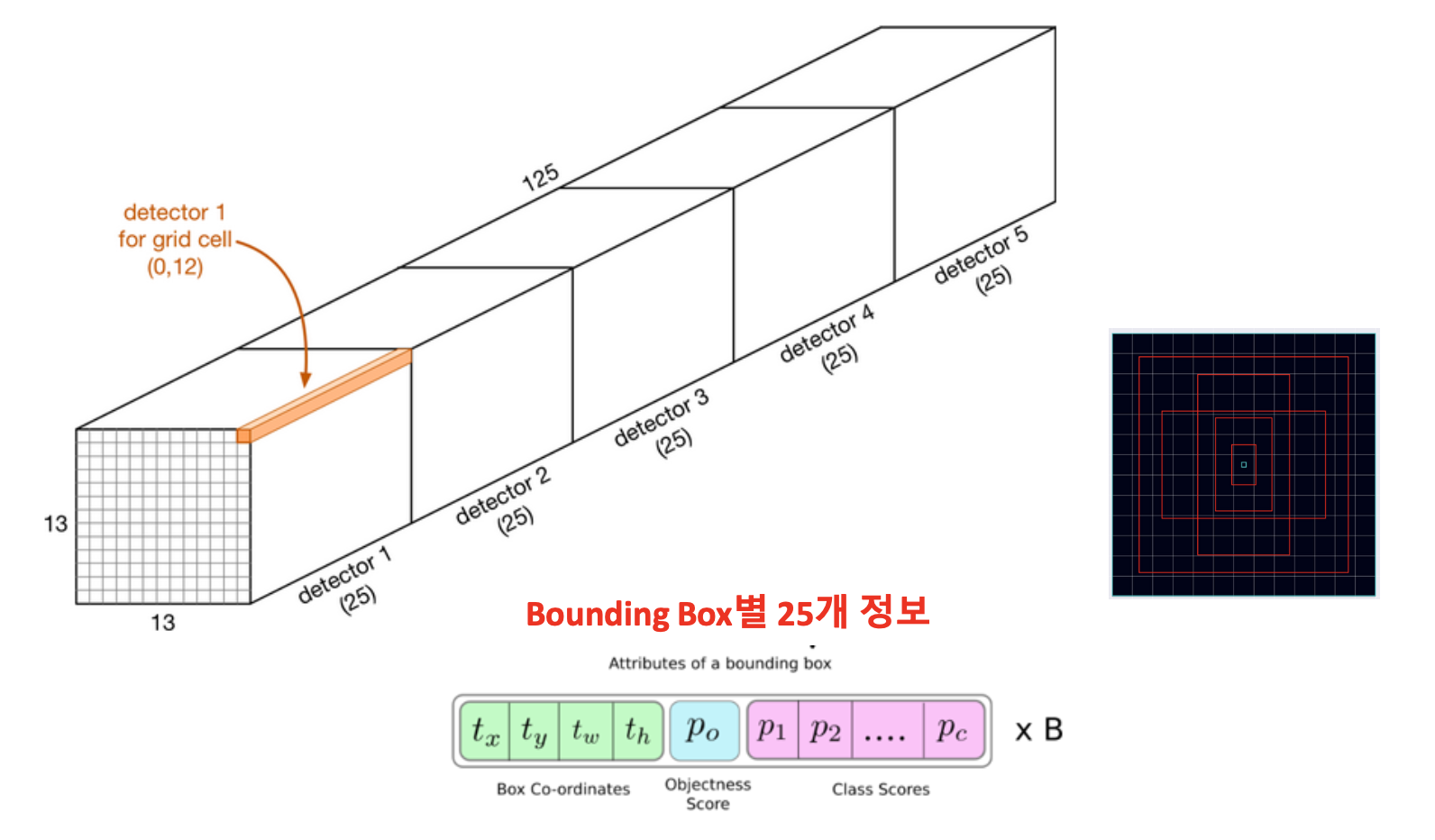
1개의 그리드 Cell이 가지고 있는 벡터
= 125개의 정보
= [5개의 정보 (x, y, w, h + Confidence score) + 20개의 정보 (20 Class)] x 5개의 Anchor Box
결과적으로 하나의 그리드 Cell에 대해 125개의 벡터가 존재하게 된다.
하나의 Anchor Box당 25개의 벡터가 존재하고 Anchor Box가 5개가 있으니까 인 125가 된다.
크기가 서로 다른 Anchor Box 5개 - Direct Location Prediction
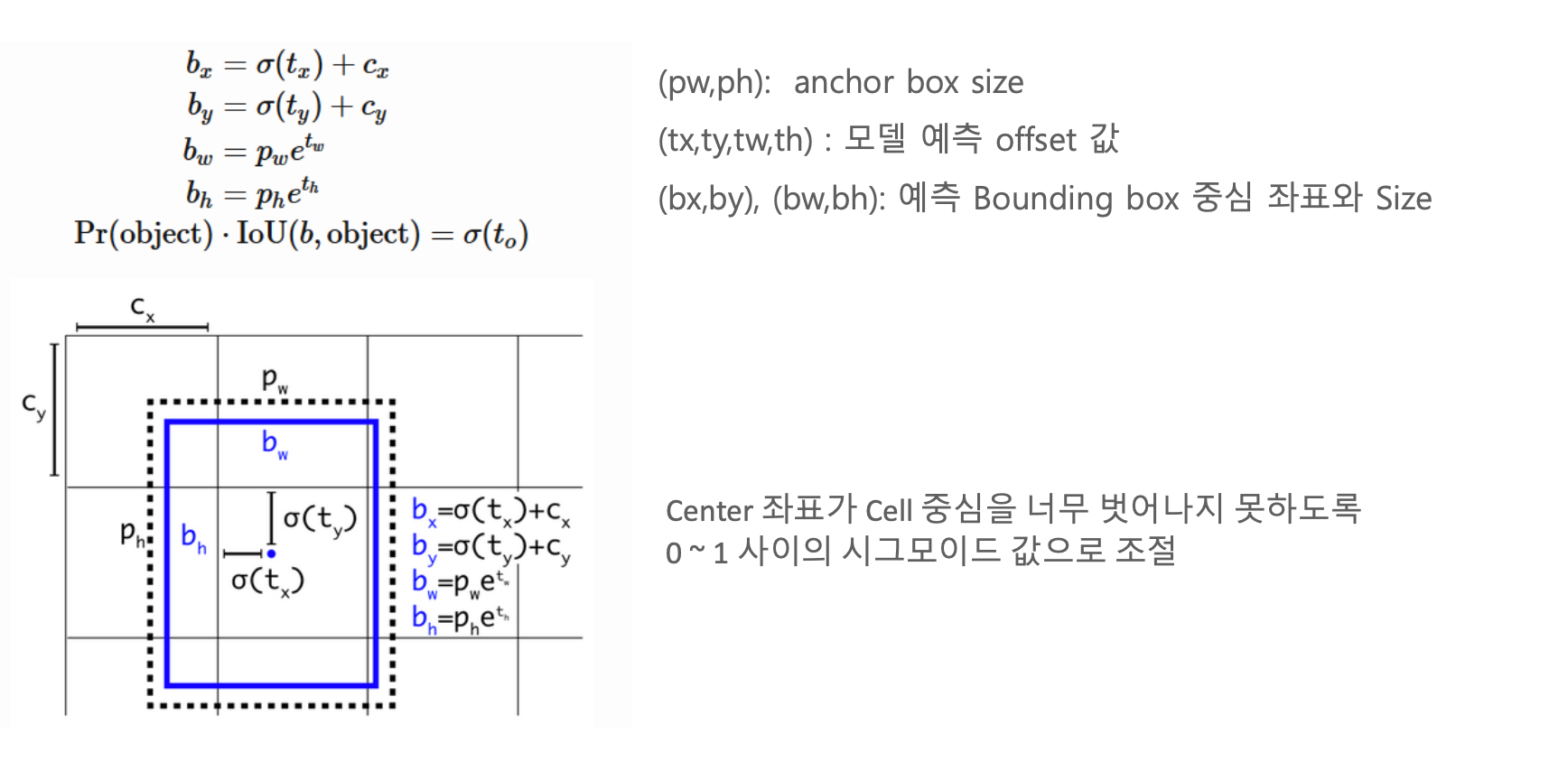
tx가 아무리 커도 cell의 중심에서 벗어나지 않도록 시그모이드를 씌운다.
YOLO V2 Loss
Passthrough module을 통한 fine grained feature
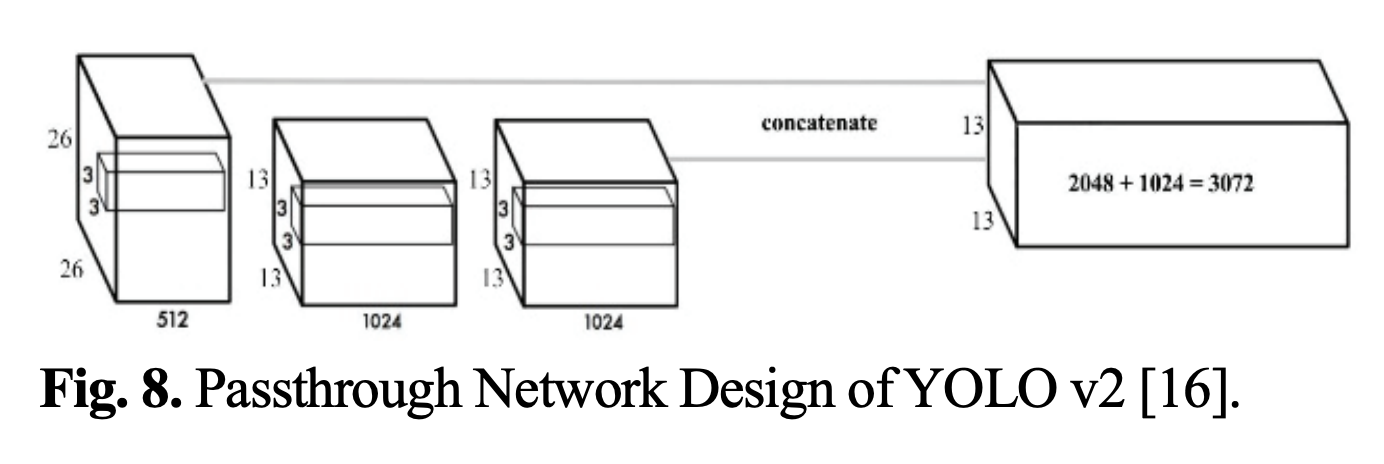
CNN을 거칠수록 Feature map이 작아지는데, 마지막에는 추상화된 영역만 뽑아진다. 추상화되면 작은 Object를 추출하기에는 조금 불리하다.
그래서 꼼수를 쓴다.
좀 더 작은 Object를 Detect 하기 위해서 26x26x512 Feature map의 특징을 유지한 채, 다른 연산을 적용하지 않고 13x13x2048 로 reshape를 한다.
여기에 Conv 연산을 거친 13x13x1024 Feature map에 추가하여 13x13x3072 Feature map을 생성한다.
DarkNet-19

Classification layer에 Fully Connected layer를 제거하고 Conv layer를 적용
YOLO - V3
YOLO V3 개요
YOLO 버전 2 모델로 버전 1에 비해 탐지 속도와 탐지 성능을 대폭 개선했다. 그런데 YOLO 연구자분들은 여기서 멈추지(?) 않았다. 버전 2 모델에 비해 탐지 속도는 약간 느려졌지만 탐지 성능을 또 대폭 개선한 버전 3 모델이 개발된다. 버전 3 모델의 특징은 다음과 같다.
- SSD의 Multi-Scale Feature Layer와 유사한 기법과 FPN을 적용
- Multi-label Classification을 해결하기 위해 클래스 분류 시 Softmax가 아닌 독립적인 여러개의 Sigmoid Layer를 사용
- 하나의 그리드 Cell 당 3개의 Anchor Box를 씌움
- FPN과 유사한 기법을 적용하여 3개의 Feature map Output에서 3개의 서로 다른 크기의 Anchor Box로 Detection 한다.
(13x13, 26x26, 52x52) 3개의 Feature map 사용 - 클래스 종류가 80개인 COCO Dataset을 사용
- Darknet-53 이라는 개별 Feature Extractor를 사용
- 동일하지만 사이즈만 다른 이미지들을 학습(Multi-Scaling), Data Augmentation 사용
- Layer 중간에 Feature Map 사이즈 축소를 막기 위한 Up Sampling 사용
- Resnet과 같이 Gradient Vanishing을 방지하기 위해 Skip Connection을 사용

Backbone의 C5에서 하나의 피쳐맵이 만들어지면 Umsampling을 한 다음에, C4의 피쳐맵과 합친다.
SSD의 Multi-Scale Feature Layer + FPN
버전 2 모델과 가장 큰 차이점 중 하나는 SSD 모델에서 Multi-Scale Feature Layer와 Retinanet의 FPN(Feature Pyramid Network)과 유사한 기법을 적용했다는 것이다. SSD의 Multi-Scale Feature Layer는 서로 다른 크기의 Feature Map에 각 포인트마다 Object Detection을 수행해주는 기법이었다.
YOLO V3 모델은 이 Multi-Scale Feature Layer를 그리드에 적용해주는 셈이다. 우선 큰 아키텍처부터 살펴보자.
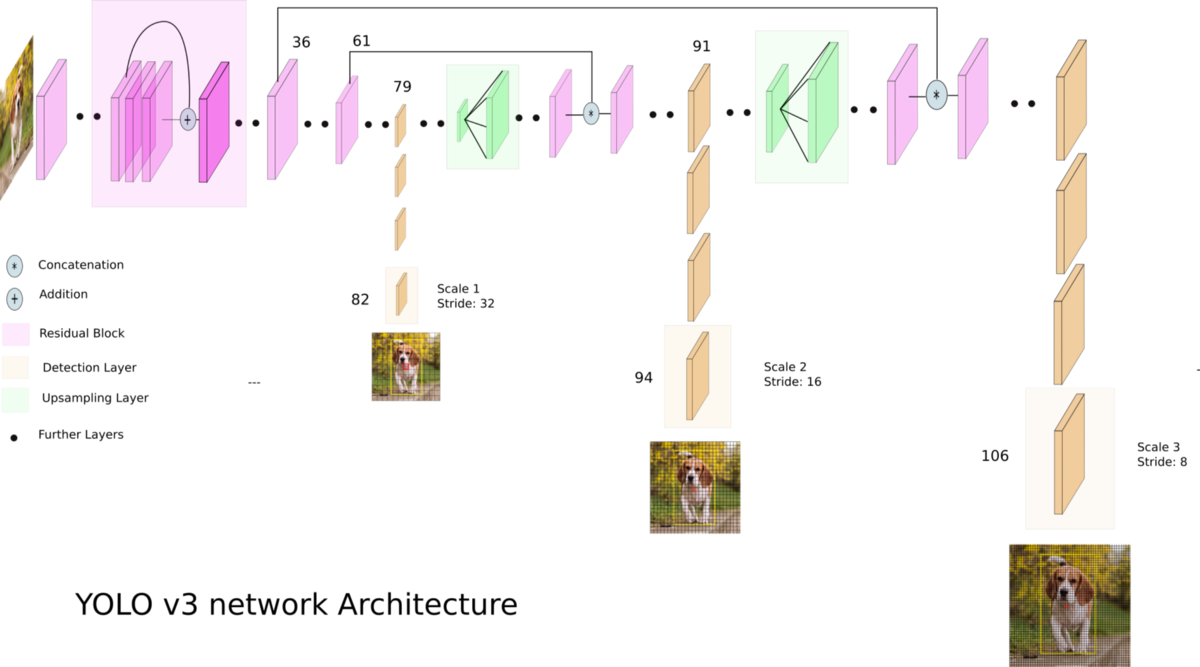
위 그림을 보다시피 버전 3 모델은 82번째(13x13), 94번째(26x26), 106번째(52x52) Layer의 Feature Map에서 각각 서로 다른 크기의 그리드로 나누고 각 Cell 마다 Object Detection을 수행한다.
전에 있는 Feature map을 계속 Umsampling을 하면서 결과를 합친다.

그리드 Cell이 가지고 있는 정보의 개수(COCO Dataset의 경우)
13x13 Feature map = 13x13x(4 + 1 + 80)x3
26x26 Feature map = 26x26x(4 + 1 + 80)x3
52x52 Feature map = 52x52x(4 + 1 + 80)x3
FPN을 적용함으로써 뽑아내는 Output 정보가 굉장히 많아 진다!
YOLO V3 모델은 위의 Multi-Scale Feature Layer와 FPN을 사용해 그리드 사이즈가 작을 때는 Anchor Box 크기가 커지므로 상대적으로 큰 객체를, 그리드 사이즈가 클 때는 Anchor Box 크기가 작아지므로 상대적으로 작은 객체를 잘 탐지하도록 하기 위해 구현되었다.
독립적인 여러개의 Sigmoid로 Multi-label Classification 해결
해당 내용을 이해하기 전에 Multi-label Classification과 Multi-class Classification의 차이점을 이해해야 한다.
- Multi-label Classification : 동시에 여러개의 레이블을 가질 수 있다. 예를 들어 '남자(레이블1), 사람(레이블2)' 를 동시에 가질 수 있다.
- Multi-class Classification : 무조건적으로 하나의 레이블만 가질 수 있다. 예를 들어 '남자(레이블1)' 또는 '사람(레이블2)' 둘 중 하나만 가질 수 있다.

그동안의 Object Detection 모델은 객체의 최종 클래스 분류를 위해 모든 클래스의 확률 값을 더하면 무조건 1이 되는 Softmax Layer를 사용했다. 즉, Multi-class Classification 문제만을 해결했다. 하지만 YOLO 버전 3 모델은 최종 클래스를 분류할 때 Softmax Layer가 아닌 각 클래스 마다 Sigmoid(=Logisitc 함수) Layer를 사용해 Multi-label Classification을 해결할 수 있다.
예를 하나만 들어보자. 'person'이라는 객체가 들어있는 이미지가 YOLO 버전 3 모델로 입력되었다. 그리고 주어진 클래스 종류는 [woman, person, cat]라고 해보자. 이 때 Softmax Layer를 사용하게 되면 각 클래스에 대한 확률 Score가 대략 [0.24, 0.75, 0.01]가 될 것이다. 즉, 세 값의 총 합은 1이 된다. 그렇기 때문에 예측 모델은 가장 Score가 높은 0.75인 'person'으로만 예측할 것이다.
하지만 여기서 각 클래스 마다 독립적인 Sigmoid Layer를 사용하게 되면 Score는 [0.7, 0.75, 0.01] 정도가 될 것이다. 결국 Score의 값 하나씩 Classification threshold(여기서 0.5라고 하자)과 비교해서 크면 1, 작으면 0으로 분류하게 됨에 따라 Multi-label로 예측하게 된다. 다시 말해 입력된 이미지는 'person' 이면서 'woman' 인 2개의 레이블을 갖도록 예측하게 된다.
Ref.
딥러닝 컴퓨터비전 완벽가이드
'🖼 Computer Vision > Object Detection' 카테고리의 다른 글
| CV - Ultralytics YOLO v3 (Oxford Pet Dataset) (0) | 2022.05.27 |
|---|---|
| CV - Ultralytics YOLO v3 (coco128 Dataset) (0) | 2022.05.26 |
| CV - SSD (Single Shot Detector) (0) | 2022.05.17 |
| CV - 60분 컷 Image Classifier 파이토치 튜토리얼 (0) | 2022.05.13 |
| CV - MMDetection (0) | 2022.05.04 |