

📌 이 글은 권철민님의 딥러닝 컴퓨터 비전 완벽 가이드 강의를 바탕으로 정리한 내용입니다.
목차
- SSD 개요
- SSD(Single Shot Detector) 란?
- Multi-Scale Feature Layer
- Default Box(=Anchor Box)
- SSD Architecture
- Anchor Box를 활용한 Convolution Predictors for detection
- SSD의 마지막은 NMS
- SSD의 Loss function
SSD 개요

그동안 우리가 배웠던 RCNN, SPP, Fast RCNN, Faster RCNN 모델은 Two-Stage Detector 모델이었다.
여기서 Two란, Region Proposal과 Object Detection 단계를 분리해 전개되는 모델들이다.
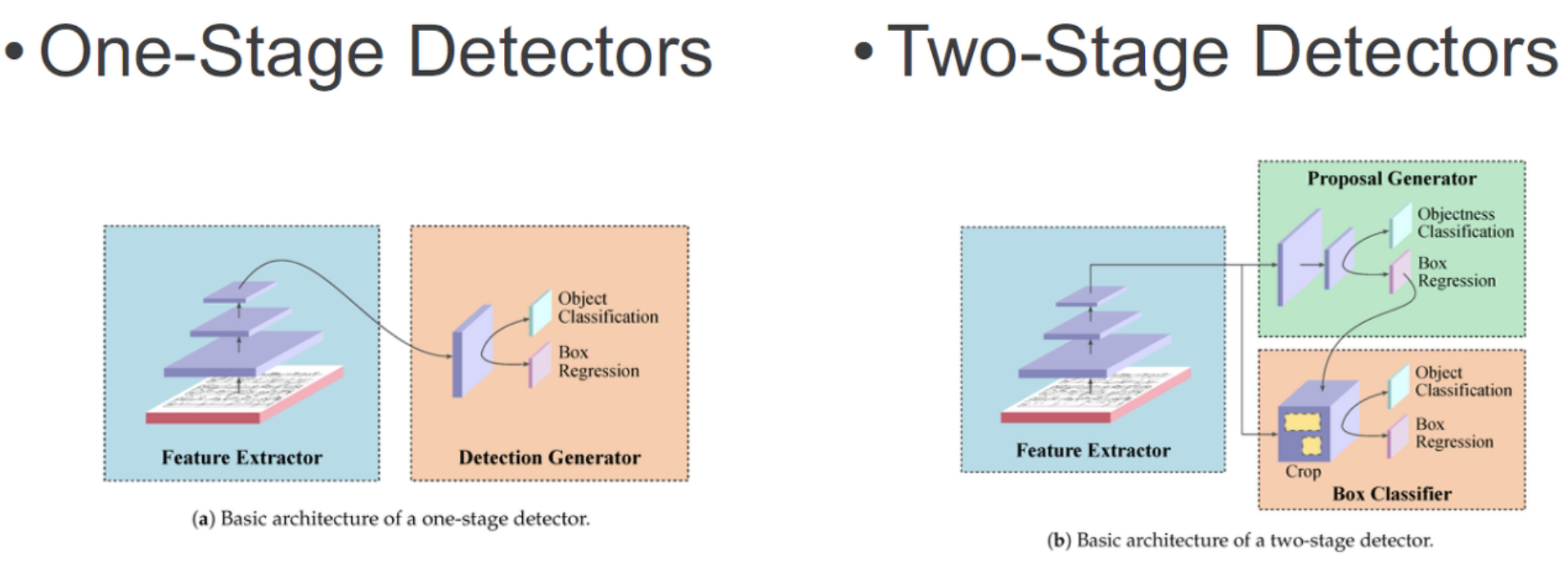
이번에 설명할 SDD와 같은 One-Stage 종류의 모델들은 Region Proposal 과 Object Detection을 따로 분리하지 않고 한 번에 수행하는 모델이다.
그렇다면 이러한 One-Stage 모델들이 등장한 배경은 무엇일까?
Two-Stage 모델들의 학습 속도가 느리기 때문이다. Object Detection 분야에서 객체를 얼마나 탐지를 잘 하느냐도 중요하지만 탐지를 얼마나 '빨리' 하느냐도 마찬가지로 중요하다.
단적으로 예를 들어 본다면, 최근 자동차 산업에서 자율주행 산업이 정말 핫하다. 그런데 만약 자율주행할 때 객체를 탐지하는 모델의 탐지 속도가 느리다면 어떻게 될까? 만약 지나가는 보행자가 시야안에 들어와 탐지되야 하는데 이 속도가 느리다면 끔찍한 교통사고가 발생할 수 있다.따라서 Object Detection 분야에서 탐지 속도도 매우 중요한 요소가 되었다.
그런데 Two-Stage 모델들은 탐지 성능은 뛰어나지만 상대적으로 탐지 속도는 매우 느린 편이다. 따라서 연구자들은 이러한 느린 탐지 속도문제를 해결하고자 One-Stage 모델을 개발해왔다.
SSD(Single Shot Detector) 란?
SSD는 Single Shot Detecter의 줄임말로 RCNN 계열에서 Object 위치를 찾는 과정과 Object를 분류하는 과정을 하나로 합친 모델이다. 사실 SSD 모델이 나오기 이전에 One-Stage 모델로서 YOLO(You Only Look Once) 버전 1이 개발되었다. 물론 YOLO 버전1의 탐지 속도 즉, 초당 프레임수 인 FPS(Frame Per Second) 값이 매우 높았지만 탐지 성능인 mAP값이 현저히 낮은 문제가 발생했다. 이 때 YOLO 버전1을 개선시키고자 SSD 모델이 등장했다. YOLO v1 다음에 나온 모델이지만 최초로 정확성과 속도를 모두 잡은 모델로 평가 받는다.(YOLO v2, v3도 정확성과 속도 모두 좋다.)

그렇다면 SSD 모델은 어떤 원리로 동작할까? SSD 모델은 Multi-Scale Feature Layer(이미지 피라미드 기법)과 Default Box라는 2개의 요소로 구성되어 있다.(참고로 Default Box란, Anchor Box랑 동일하다고 보면 된다고 한다. 논문 상에서는 Default Box로 나와있으나 역할은 Anchor Box와 동일하다)
Multi-Scale Feature Layer
Multi-Scale Feature Layer은 여러번의 Convolution을 적용해 나온 여러 개의 Feature Map을 Object Detection을 수행시키고 그 결과를 통합해 최종 Detection하는 과정이다.
아래 그림에서 Feature Map 사이즈가 32, 16, 8, 4 일 때 각각에 대해 Object Detection을 수행하게 된다. 그렇다면 각 Feature Map이 Object Detection을 어떻게 수행할까?

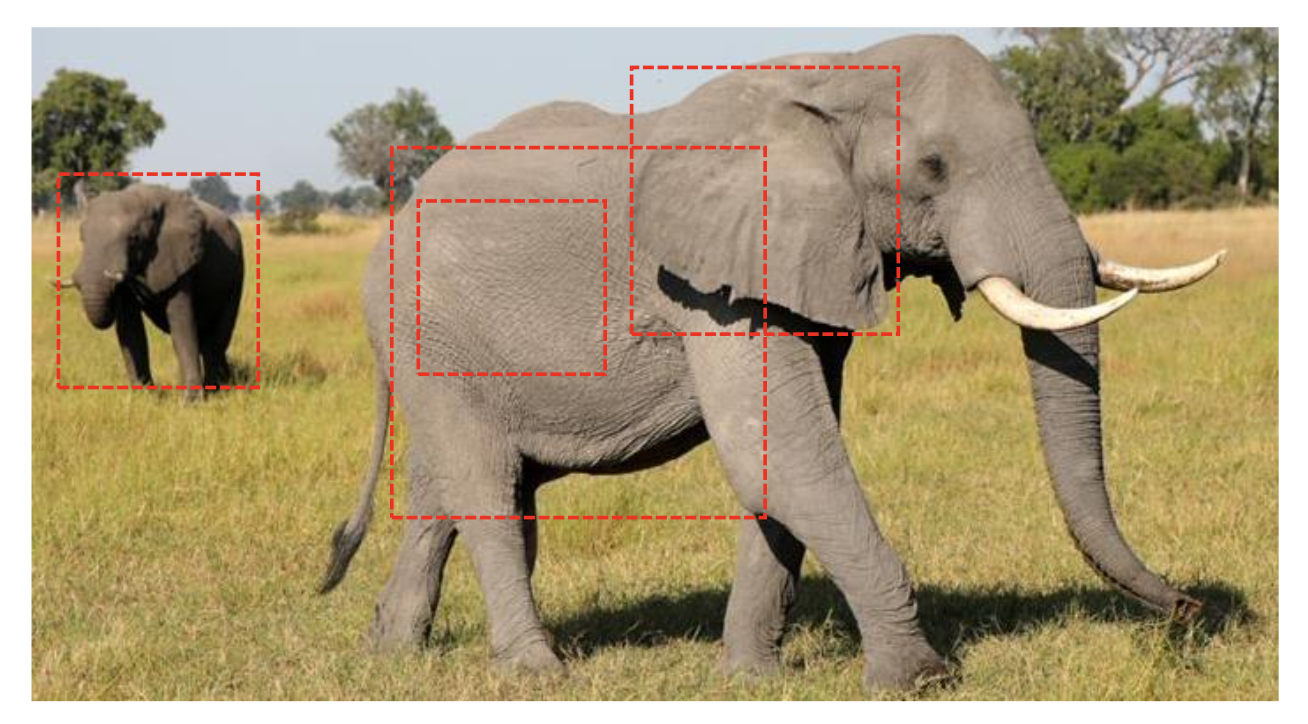
Feature map이 너무 크면 코끼리를 인식을 못 할 수도 있다.

따라서 Feature map 을 줄여가면서 Object를 Detection 한다.
이것이 바로 Multi-Scale Feature Layer이다.
Default Box(=Anchor Box)
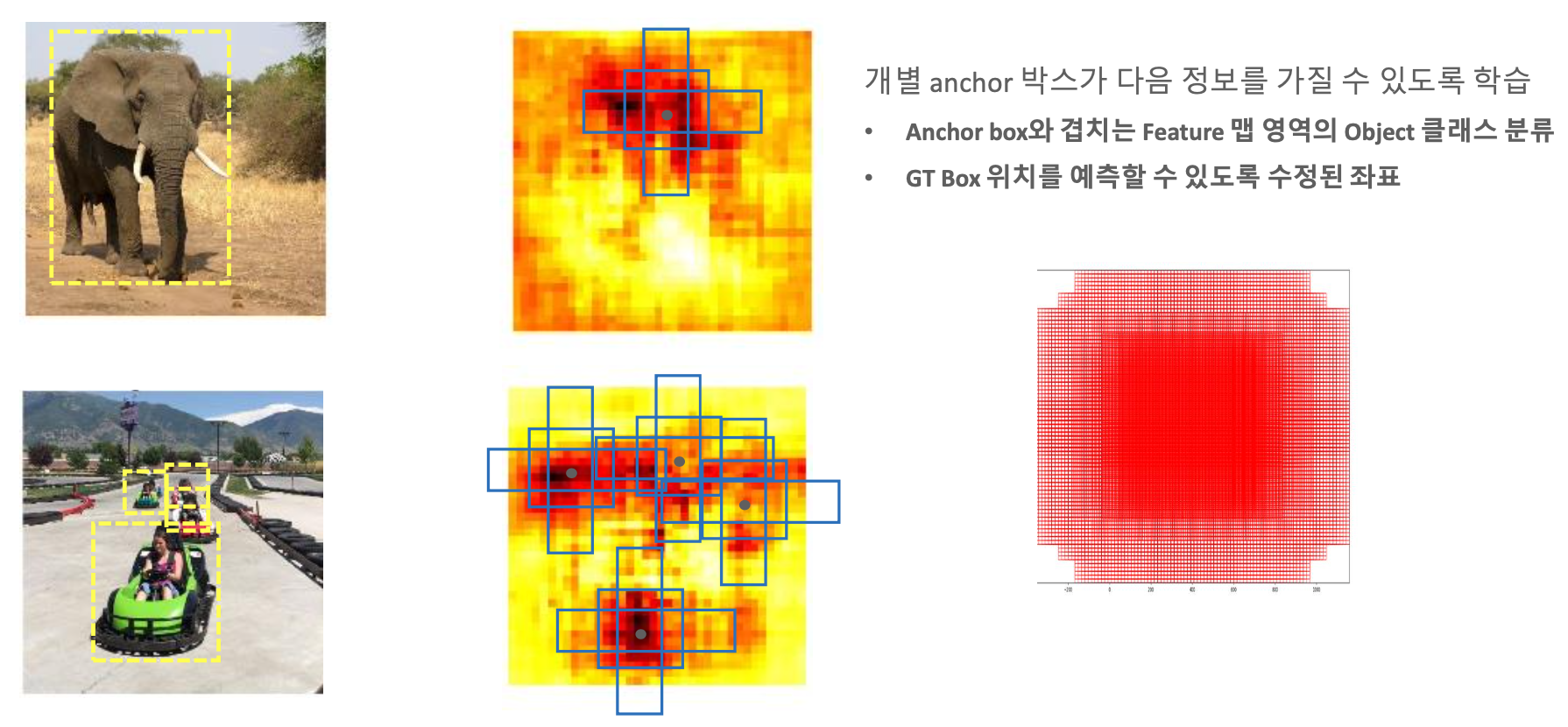
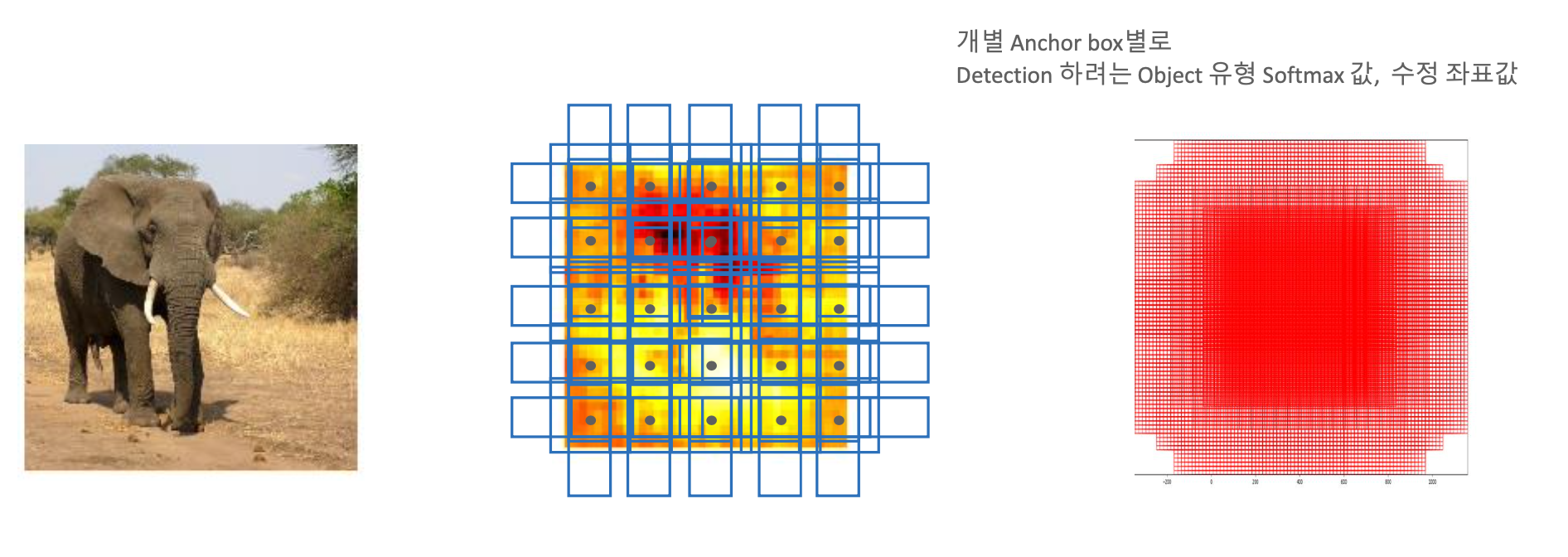
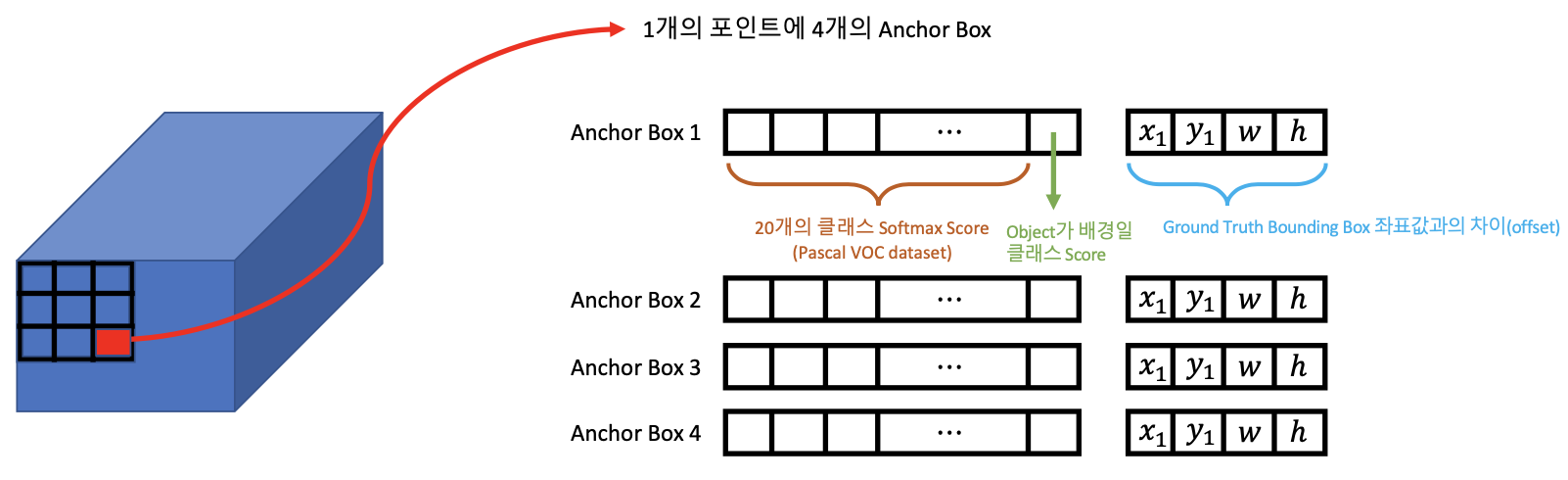
개별 Anchor Box 별로 Detection 하려는 객체의 Softmax 값과 수정 좌표 값이 SSD 네트워크를 통해서 학습을 하게 된다.
그리고 이러한 각각의, 여러개의 Feature map(32×32, 16×16, 8×8, 4×4)에 맞는 Anchor Box 들에 대해서 학습을 수행을 하면서, Anchor Box를 기반으로 Object를 찾는 것이다.
Default Box는 Faster RCNN의 Anchor Box와 비슷한 개념이다.(논문에서 다른 단어를 사용했을 뿐, 거의 똑같다고 보면 된다.)
이미지에서 찾기위한 Object의 크기가 다양하다. 정해진 크기의 Default Box를 이용하여 다양한 크기의 Object를 찾기 위해 이미지의 크기를 줄여가며 Detection을 수행한다.

위 그림에서 노란 박스는 Default Box이다. 1번 그림에서 오드리 햅번과 그레고리 펙 모두 Detection 되지 못하고 있다.
1번 이미지의 크기를 줄인 2번에서 똑같은 Default Box에 의해 오드리 햅번은 Detection이 되었다. 그레고리 펙은 아직도 안되었다.
3번 이미지는 2번의 이미지를 또 한번 크기를 줄였다. 이번에는 오드리 햅번과 그레고리펙 모두 Detection 되었다.
위 과정을 feature map을 이용하여 표현한다면 다음 그림과 같다.
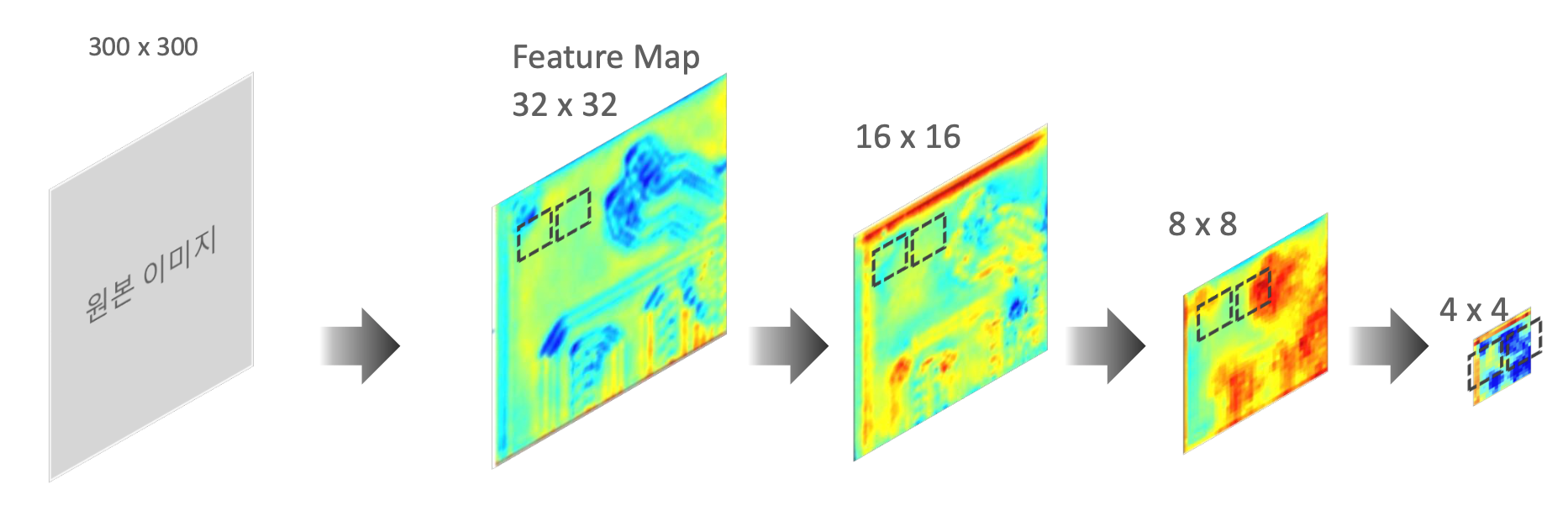
32 × 32에서 Default Box를 이용하여 Object Detection를 수행하고 Convoltion layer를 이용하여 16 × 16으로 만든 뒤,
Object Detection를 수행하고 이 과정을 반복하여 작은 Object 부터 큰 Object 모두 찾을 수 있다.
위의 그림에서 Convolution을 통해 나온 각각의 Feature Map의 포인트(그림 속에서는 32 × 32안의 노란색 포인트들)마다 여러개의 Anchor Box를 씌우고 Ground Truth와 비교를 하면서 학습을 진행한다.
위와 같은 구조의 SSD 모델의 특징은 무엇일까? 바로 서로 크기가 다른 Feature Map이 input image 내의 크기가 서로 다른 객체들을 각각 전담마크(?)해서 탐지를 잘 하게 된다.
우선 Feature Map 1에서 Feature Map4로 갈수록 input image를 더 상징적으로 잘 나타내는 Feature Map이 된다.
즉, 위 그림의 중심 Object들은 강아지들이다. 따라서 Feature Map 1번 일 때 보다 Feature Map 2번~4번에서 강아지들을 상징하는 Feature Map이 존재할 것이다.
이제 'SSD Architecture' 자료의 하단을 살펴보면 파선으로 된 박스들을 살펴보자. 먼저 32 x 32 Feature Map에 해당하는 파선 박스들을 보면 강아지들 보다 작은 '사람의 손'을 탐지하고 있다. 다음의 16 x 16 Feature Map에서는 좀 더 큰 Object인 강아지를 탐지하고 있다. 따라서 Convolution 과정을 더 거친 Feature Map일수록 이미지의 중심이 되는 Object를 잘 탐지하고 Convolution 과정의 초반 Feature Map일수록 이미지의 사이드(?) Object를 잘 탐지하게 된다. 이러한 과정으로 인해 SSD는 이미지 속에 존재하는 여러가지 Object들을 잘 탐지할 수 있게 된다.
SSD Architecture
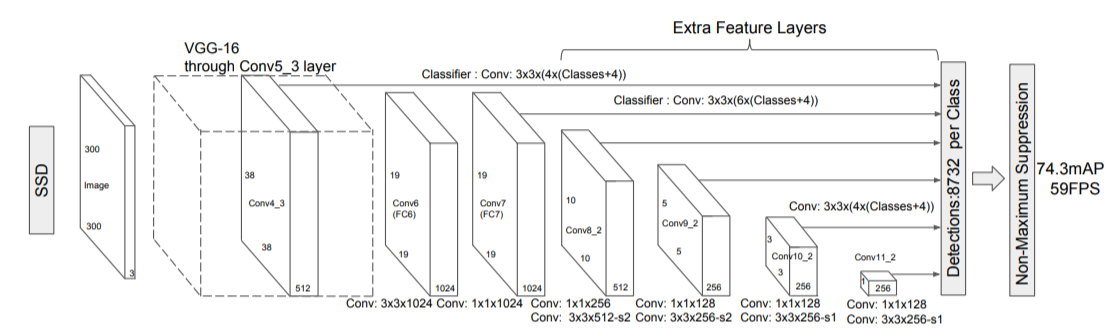
Classifier : Conv : 3×3×(4×(Classes+4) 에서 4는 Default Box의 갯수이다.
Default Box의 갯수에 대해서 Conv4 layer(38×38)의 그리드 마다 4개의 Anchor Box 정보들이 채워진다.
Classifier : Conv : 3×3×(4×(Classes+4) 에서 Classes+4는 개별 Anchor Box들이 채워야 하는 정보이다. 예를 들어, PASCAL VOC는 Class가 20개이니 여기서 Classes는 20+1(Background)이고 4는 좌표 값이다.
이렇게 Default Box의 정보들이 모이게 되면 맨 마지막에 Detection 단위로 8732개가 모인다.
그런데 너무 많기 때문에 NMS(Non Max Suppression)을 통해서 Detect 된 것들을 각 개별 Object별로 하나씩만 추려주게 된다.
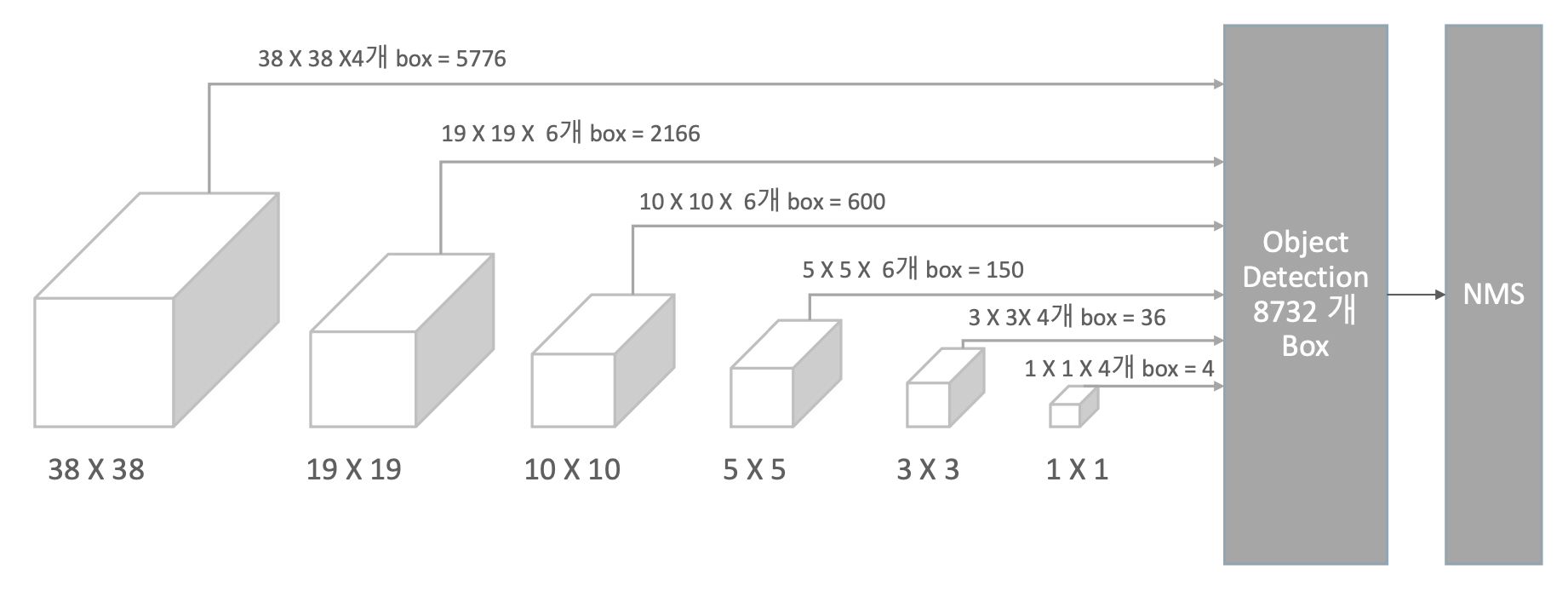
Anchor Box를 활용한 Convolution Predictors for detection
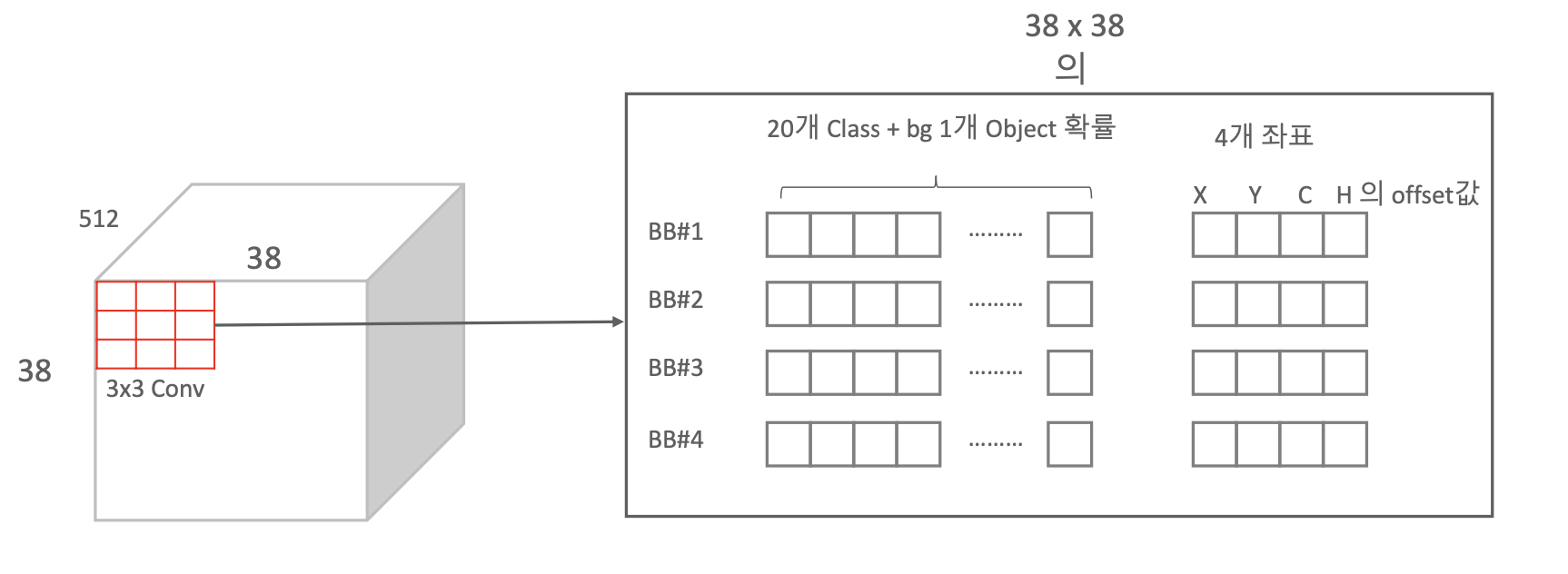
38×38 번 3×3 Conv 연산을 개별 셀 별로 한다. 여기서 BB에 대한 정보를 채워준다.
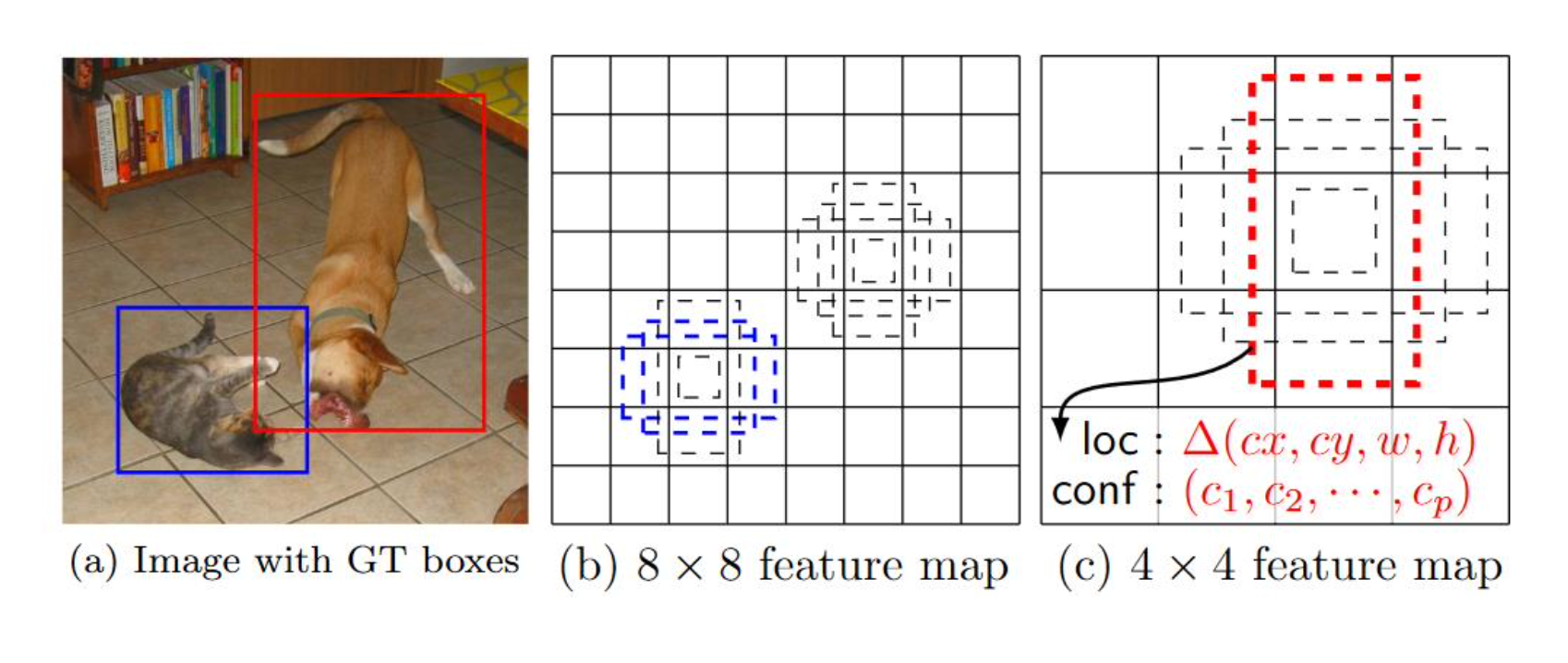
두개의 서로 작은 크기를 가진 Object가 있을 때 Multi-Scale Feature map을 이용한다.
고양이의 BB가 4개가 있는데 2개만 파란색으로 표시가 되었다. 이것을 Anchor Box와 Ground Truth가 매칭되었다고 한다.
매칭의 기준은 Ground Truth와 Anchor Box가 IOU가 얼마인가, 즉, IOU가 몇퍼센트 이상이다라고 하면 매칭이 된다고 한다.
매칭되는 Anchor Box와 Ground Truth와의 간격인 Offset을 학습을 통해서 최적값을 찾아내는 Weight 값을 업데이트 한다.
8×8 Feature map보다 작은 4×4 Feature map으로 잡아보면 큰 개의 Anchor Box도 매칭될 수 있다.
이렇게 SSD는 ImageNet 모델을 이용하여 Feature map을 얻고 그 과정에서 생기는 다양한 크기의 Feature map에서 Default Box를 이용한 Object Detection를 수행한다.
결과적으로 SSD 모델을 간단하게 정리하자면, 만약 input image 내에 여러가지의 객체들이 있을 때, 서로 사이즈가 다른 여러개의 Feature Map이 input image 내의 크기가 다른 객체들을 전담해서 탐지하도록 하는 모델이다.
SSD의 마지막은 NMS
2번 목차까지의 과정을 거쳐 객체를 탐지하기 위한 많은 후보 Bounding Box들이 생겨났을 것이다. 이제 Ground Truth와 가장 IoU가 높은 Bounding Box들만 남기기 위해 NMS(Non-Max Suppression) 기법을 사용한다. NMS에 대한 부분은 설명을 참고하자.
SSD의 Loss function
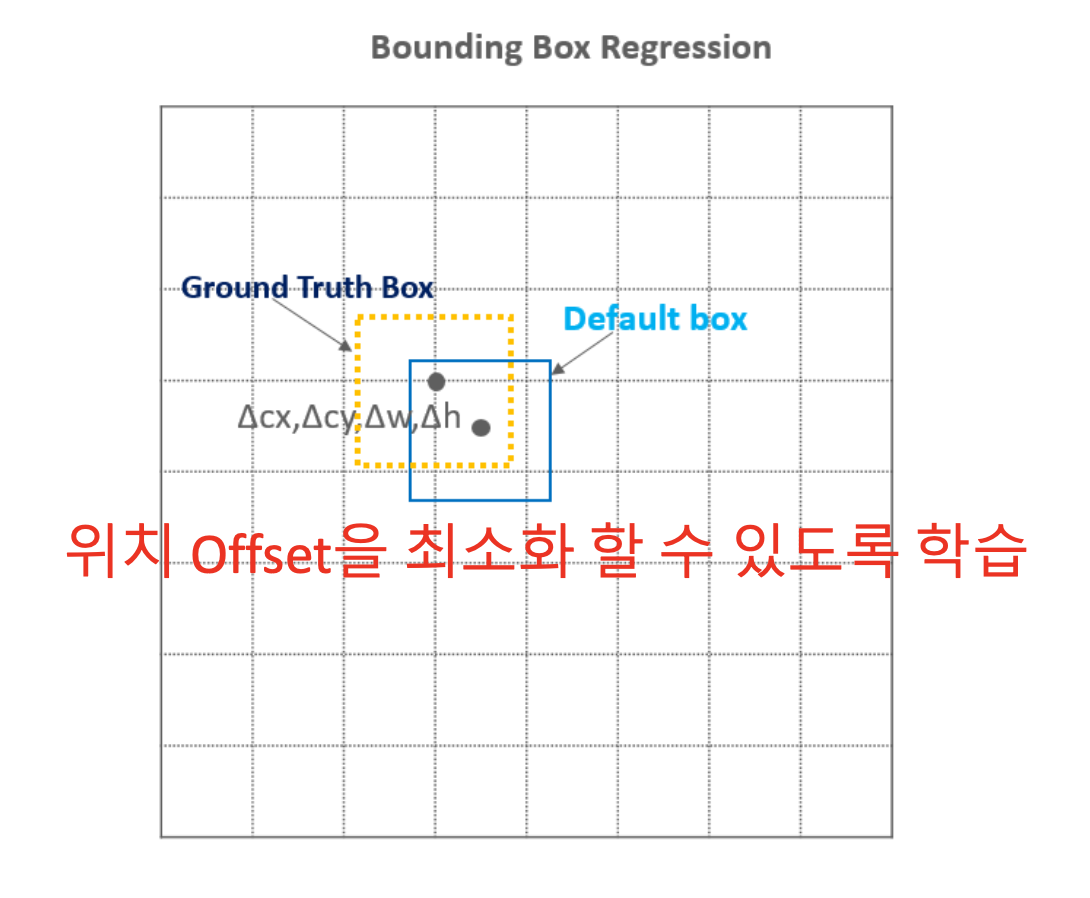

Classification과 Regression을 동시에 진행하기 때문에 Loss 함수도 두 가지 모두 포함 되어야 한다.
N은 matched된 Default Box의 개수이며 가 classification, 이 bounding box regression의 loss이다.
Ref : 딥러닝 컴퓨터비전 완벽가이드, 앎의 공간
'🖼 Computer Vision > Object Detection' 카테고리의 다른 글
| CV - Ultralytics YOLO v3 (coco128 Dataset) (0) | 2022.05.26 |
|---|---|
| CV - YOLO V1, V2, V3 (You Only Look Once) (0) | 2022.05.19 |
| CV - 60분 컷 Image Classifier 파이토치 튜토리얼 (0) | 2022.05.13 |
| CV - MMDetection (0) | 2022.05.04 |
| CV - Faster RCNN (2) | 2022.04.29 |