
Deep Learning with PyTorch: A 60 Minute Blitz — PyTorch Tutorials 1.11.0+cu102 documentation
Shortcuts
pytorch.org
목차
- Tensors
- torch.autograd
- Neural Network (with PyTorch)
- 신경망 학습은 2단계로 이루어진다.
- nn(Neural Networks)
- General Training Process
- 손실 함수 (Loss Function)
- 역전파(Backprop)
- Optimizer : Gradient Descent 최적화
- Classifier 학습하기
- CIFAR10 Data Load
- CNN 정의하기
- Loss function & Optimizer 정의하기
- Training Neural Network
- Validation
Tensors

import torch
import numpy as npdata = [[1,2], [3, 4]]
x_data = torch.tensor(data)
x_data
# 텐서의 속성
tensor = torch.rand(3,4)
print(tensor.shape)
print(tensor.dtype)
print(tensor.device)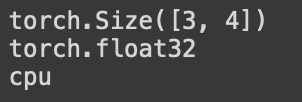
torch.autograd
신경망 학습을 지원하는 파이토치의 자동 미분 엔진이다.
신경망(Neural Network)는 입력 데이터에 대해 실행되는 중첩된 함수들의 모음이다. 여기서 함수는 tensor로 저장되는 매개변수(weight와 bias로 구성된)들로 정의된다.
역전파를 통해 파라미터를 업데이트하는 방법
Neural Network (with PyTorch)
신경망 학습은 2단계로 이루어진다.
- 1단계 : Forward Propagation
- 2단계 : Backward Propagation
Forward Propagation : 이 단계에서 신경망은 정답을 맞추기 위해서 최선의 추측을 한다.
Backward Propagation : 역전파 단계에서는 추측값에서 발생한 Error를 바탕으로 매개변수를 적절히 조절한다. 역방향으로 이동하면서 매개변수들의 gradient(미분값)을 수집하고, Gradient Descent(경사하강법)을 사용하여 매개개변수들을 최적화 한다.
import torch, torchvision
model = torchvision.models.resnet18(pretrained=True)
data = torch.rand(1, 3, 64, 64)
labels = torch.rand(1, 1000)
############################
####### Forward Pass #######
############################
prediction = model(data)
############################
### loss = error tensor ####
############################
loss = (prediction - labels).sum()
############################
### Backward Pass start ####
############################
loss.backward()
# Autograd가 parameter들을 gradient caculate and save
############################
######### Optimizer ########
############################
optim = torch.optim.SGD(model.parameters(), lr=1e-2, momentum=0.9)
# optimizer에 모델의 모든 매개변수 등록
##################################################
######## .step() : Gradient Descent start ########
##################################################
optim.step()
# optim.grad에 저장된 변화도에 따라 각 매개변수를 조정(adjust)합니다.nn(Neural Networks)
nn 은 모델을 정의하고 미분하는데 autograd 를 사용합니다.
nn.Module 은 계층(layer)과 output 을 반환하는 forward(input) 메서드를 포함하고 있습니다.
General Training Process
- 학습 가능한 매개변수(또는 가중치(weight))를 갖는 신경망을 정의
- 데이터셋(dataset) 입력을 반복
- 입력을 신경망에서 전파(process)
- 손실(loss; 출력이 정답으로부터 얼마나 떨어져있는지)을 계산
- 변화도(gradient)를 신경망의 매개변수들에 역으로 전파합니다.
- 신경망의 가중치를 갱신. 일반적으로 다음과 같은 간단한 규칙을 사용한다: 새로운 가중치(weight) = 가중치(weight) - 학습률(learning rate) * 변화도(gradient)
import torch
import torch.nn as nn
import torch.nn.functional as F
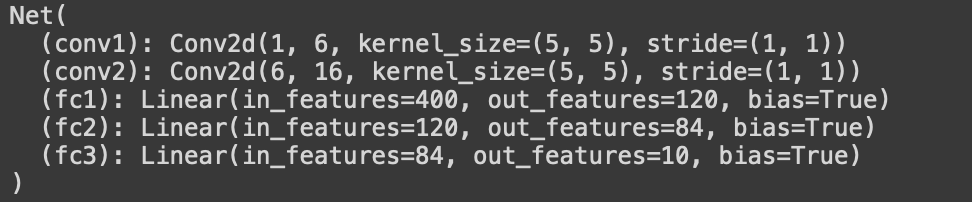
class Net(nn.Module): # nn.Module 상속 받음
def __init__(self):
super(Net, self).__init__() # nn.Module 호출
# CNN kernel
self.conv1 = nn.Conv2d(1, 6, 5) # (input channel, output channel, 5x5)
self.conv2 = nn.Conv2d(6, 16, 5) # 5x5행렬을 가지는 필터 16개를 input tensor에 적용하겠다.
# y = Wx+b
self.fc1 = nn.Linear(16 * 5 * 5, 120) # 필터 16개 x 5x5 행렬을 펼쳐서
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# (2,2) Max Pooling
x = F.max_pool2d(F.relu(self.conv1(x)),(2,2))
x = F.max_pool2d(F.relu(self.conv2(x)),(2,2))
x = torch.flatten(x, 1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
print(net)

input → conv2d → relu → maxpool2d → conv2d → relu → maxpool2d
→ flatten → linear → relu → linear → relu → linear
→ MSELoss
→ loss
거꾸로 weight를 업데이트 하는 방법이 Backpropagation
forward 함수만 정의하고 나면, (변화도를 계산하는)backward 함수는 autograd를 사용하여 자동으로 정의 된다.
모델의 학습 가능한 매개변수들은 net.parameters()에 의해 반환된다.
params = list(net.parameters())
print(len(params))
print(params[0].size()) # conv1의 weight
# torch.Size([배치사이즈, 채널수, 이미지 너비, 이미지 높이])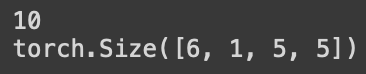
출력층부터 역순으로 Gradient를 전달하여 전체 Layer 의 가중치를 업데이트 하는 방식
임의의 32x32 입력값을 넣어보면, 이 신경망의 예상되는 입력 크기는 32x32입니다.
이 신경망에 MNIST 데이터셋을 사용하기 위해서는, 데이터셋의 이미지 크기를 32x32로 변경해야 합니다.
input = torch.randn(1, 1, 32, 32)
out = net(input)
print(out)
모든 매개변수의 변화도 버퍼(gradient buffer)를 0으로 설정하고, 무작위 값으로 역전파를 한다.
net.zero_grad()
out.backward(torch.randn(1, 10))
zero_grad()를 해주는 이유
보통 딥러닝에서는 미니배치+루프 조합을 사용해서 parameter들을 업데이트 하는데,
한 루프에서 업데이트를 위해 loss.backward()를 호출하면 각 파라미터들의 .grad 값에 변화도가 저장이 된다.
이후 다음 루프에서 zero_grad()를 하지않고 역전파를 시키면 이전 루프에서 .grad에 저장된 값이 다음 루프의 업데이트에도 간섭을 해서 원하는 방향으로 학습이 안된다고 한다.
따라서 루프가 한번 돌고나서 역전파를 하기전에 반드시 zero_grad()로 .grad 값들을 0으로 초기화시킨 후 학습을 진행해야 한다.
- torch.Tensor - backward() 같은 autograd 연산을 지원하는 다차원 배열임. 또한 tensor에 대한 변화도를 갖고 있음
- nn.Module - 신경망 모듈. 매개변수를 캡슐화(encapsulation)하는 간편한 방법, GPU로 이동, 내보내기(exporting), 불러오기(loading) 등의 작업을 위한 헬퍼(helper)를 제공합니다.
- nn.Parameter - Tensor의 한 종류로, Module 에 속성으로 할당될 때 자동으로 매개변수로 등록 됩니다.
- autograd.Function - autograd 연산의 순방향과 역방향 정의 를 구현합니다. 모든 Tensor 연산은 하나 이상의 Function 노드를 생성하며, 각 노드는 Tensor 를 생성하고 이력(history)을 인코딩 하는 함수들과 연결하고 있습니다.
여기까지 신경망을 정의하는 법, input을 처리하고, backward를 호출하는 것까지 했다.
이제 손실을 계산하고 신경망의 가중치를 갱신해보자.
손실 함수 (Loss Function)
모델이 더 좋은 모델로 가기 위해서, 모델이 얼마나 학습 데이터에 잘 맞고 있는지, 학습을 잘 하고 있는지에 대한 길잡이가 있어야 한다.
그리고 그 길잡이에 기반해서 Gradient도 적용을 해야 한다.
그 길잡이가 Loss function이다.
대표적으로 회귀는 주로 MSE(Mean Squared Error), 분류는 주로 Cross Entropy(binary, categorical)를 이용한다.
손실 함수는 (output, target)을 한 쌍(pair)의 입력으로 받아, 출력(output)이 정답(target)으로부터 얼마나 멀리 떨어져있는지 추정하는 값을 계산한다.
nn 패키지에는 여러가지의 손실 함수들이 존재한다.
간단한 손실 함수로는 출력과 대상 간의 평균제곱오차(mean-squared error)를 계산하는 nn.MSEloss 가 있다.
output = net(input)
target = torch.randn(10) # 예시를 위한 임의의 정답
target = target.view(1, -1) # 출력과 같은 shape로 만듦
criterion = nn.MSELoss()
loss = criterion(output, target)
print(loss)
따라서 loss.backward() 를 실행할 때, 전체 그래프는 신경망의 매개변수에 대해 미분되며,
그래프 내의 requires_grad=True 인 모든 Tensor는 변화도가 누적된 .grad Tensor를 갖게 된다.
역전파(Backprop)
오차(error)를 역전파 학습하기 위해서는 loss.backward() 만 해주면 된다.
기존에 계산된 변화도의 값을 누적 시키고 싶지 않다면 기존에 계산된 변화도를 0으로 만드는 작업이 필요하다.
이제 loss.backward() 를 호출하여 역전파 전과 후에 conv1의 bias 변수의 변화도를 살펴 보자.
net.zero_grad() # 모든 매개변수의 변화도 버퍼를 0으로 만듦
print('conv1.bias.grad before backward')
print(net.conv1.bias.grad)
loss.backward()
print('conv1.bias.grad after backward')
print(net.conv1.bias.grad)
Optimizer : Gradient Descent 최적화
Weight = weight - learning rate × gradient
새로운 가중치 = 가중치 - 학습률 × 변화도
간단한 파이썬 코드로 구현
learning_rate = 0.01
for f in net.parameters():
f.data.sub_(f.grad.data * learning_rate)
Optimizer 생성을 통한 가중치 갱신
import torch.optim as optim
# Optimizer 생성
optimizer = optim.SGD(net.parameters(), lr=0.01)
# 학습과정
optimizer.zero_grad() # 변화도 버퍼 0
output = net(input) # 모델에 입력값을 넣어서 예측값 산출
loss = criterion(output, target) # 손실함수 계산, error 계산
loss.backward() # 손실함수를 기준으로 역전파 설정
optimizer.step # 역전파를 진행하고 가중치를 업데이트
optimizer는 한번 돌 때마다 초기화를 시켜주어야 한다. 쌓이는 것을 방지하기 위해 zero_grad()를 넣어준다.
model(inputs)에서는 13 개의 변수가 있는 배치 32개의 데이터가 들어온다. 행렬형태로 들어가서 계산이 되고, output 이 1개가 나온다. 32개의 데이터가 들어갔으니 32개의 output이 나오게 된다.
그래서 32개의 예측값과 32개의 실제값을 비교하는 loss를 구한다.
loss가 나오면, loss가 최소가 되게하는 weight를 구해야하니 loss를 기준으로 backward를 해준다. 그 계산은 optimizer.step()이라는 것을 이용해서 모델 파라미터 model.parameter()로 정의된 weight에 대해서 자동으로 역전파 계산을 해준다.
Classifier 학습하기
일반적으로 이미지나 텍스트, 오디오나 비디오 데이터를 다룰 때는 표준 Python 패키지를 이용하여 NumPy 배열로 불러오면 된다.
그 후 그 배열을 torch.*Tensor 로 변환한다.
특별히 영상 분야를 위한 torchvision 이라는 패키지가 만들어져 있는데, 여기에는 ImageNet이나 CIFAR10, MNIST 등과 같이 일반적으로 사용하는 데이터셋을 위한 데이터 로더(data loader), 즉 torchvision.datasets 과 이미지용 데이터 변환기 (data transformer), 즉 torch.utils.data.DataLoader 가 포함되어 있다.

CIFAR10에 포함된 이미지의 크기는 3x32x32로, 이는 32x32 픽셀 크기의 이미지가 3개 채널(channel)의 색상로 이뤄져 있다는 것을 뜻한다.
아래에 나와 있는 단계로 Image Classifier를 학습한다.
- torchvision 을 사용하여 CIFAR10의 학습용 / 시험용 데이터셋을 불러오고, 정규화(nomarlizing)한다.
- 합성곱 신경망(Convolution Neural Network)을 정의한다.
- 손실 함수(Loss function)를 정의한다.
- 학습용 데이터를 사용하여 신경망을 Train 한다.
- 시험용 데이터를 사용하여 신경망을 Test 한다.
CIFAR10 Data Load
import torch
import torchvision
import torchvision.transforms as transforms
torchvision 데이터셋의 출력(output)은 [0, 1] 범위를 갖는 PILImage 이미지이다.
이를 [-1, 1]의 범위로 정규화된 Tensor로 변환 한다.
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# transform이 실행되면 transform.Compose에 적힌 순서대로 실행된다.
batch_size = 4
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size,
shuffle=True, num_workers=2)
# 배치 형태로 변환
# batch_size : 배치 크기 설정
# num_workers : 데이터를 불러올때 subprocess를 몇개 사용할 것인지 (에러가 나면 0으로 설정)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=batch_size,
shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')CNN 정의하기
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = torch.flatten(x, 1) # 배치를 제외한 모든 차원을 평탄화(flatten)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()Loss function & Optimizer 정의하기
Cross-Entropy loss와 모멘텀(momentum) 값을 갖는 SGD를 사용한다.
import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
Training Neural Network
for epoch in range(2): # 데이터셋을 수차례 반복합니다.
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# [inputs, labels]의 목록인 data로부터 입력을 받은 후;
inputs, labels = data
# 변화도(Gradient) 매개변수를 0으로 만들고
optimizer.zero_grad()
# 순전파 + 역전파 + 최적화
outputs = net(inputs) # 모델에 입력값을 넣어준다.
loss = criterion(outputs, labels) # 손실함수 계산, error 계산
loss.backward() # 손실함수를 기준으로 역전파를 설정
optimizer.step() # 역전파를 진행하고 가중치를 업데이트 한다.
# 통계를 출력합니다.
running_loss += loss.item() # epoch 마다 평균 loss를 계산하기 위해 배치 loss를 더한다.
if i % 2000 == 1999: # print every 2000 mini-batches
print(f'[{epoch + 1}, {i + 1:5d}] loss: {running_loss / 2000:.3f}')
running_loss = 0.0
print('Finished Training')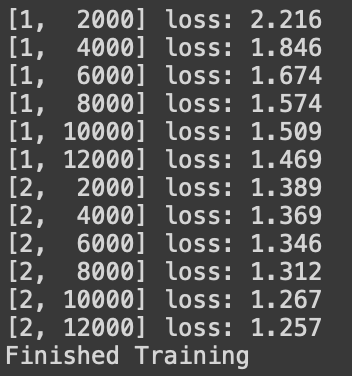
trainloader에 들어있는 데이터셋을 2회 반복하여 신경망을 학습시켰다.
두번째 for 문에서 배치가 예를 들어 15개 남았다고 하면, 알아서 15개가 들어와서 다 사용하게끔 파이토치에 구현이 되어있다.
optimizer는 한번 돌 때마다 초기화를 시켜주어야 한다. 쌓이는 것을 방지하기 위해 zero_grad()를 넣어준다.
model(inputs)에서는 배치 갯수 만큼의 데이터가 들어온다. 행렬 형태로 들어가서 계산이 되고, output 이 1개가 나온다. 32개의 데이터가 들어가면 32개의 output이 나오게 된다. 그래서 32개의 예측값과 32개의 실제값을 비교하는 loss를 구한다.
loss가 나오면, loss가 최소가 되게하는 weight를 구해야하니 loss를 기준으로 backward를 해준다. 그 계산은 optimizer.step()이라는 것을 이용해서 모델 파라미터 model.parameter()로 정의된 weight에 대해서 자동으로 역전파 계산을 해준다.
loss.item()은 텐서로 나온 하나의 loss를 running_loss에 더해서 이제 평균을 구한다.
학습한 모델을 저장!
PATH = './cifar_net.pth'
torch.save(net.state_dict(), PATH)Validation
신경망이 예측한 출력과 진짜 정답(Ground-truth)을 비교하는 방식으로 확인한다.
만약 예측이 맞다면 샘플을 ‘맞은 예측값(correct predictions)’ 목록에 넣자.
dataiter = iter(testloader) # testloader 안의 실제값 확인
images, labels = dataiter.next() # 데이터를 하나씩 불러온다.
# 이미지를 출력합니다.
imshow(torchvision.utils.make_grid(images))
print('GroundTruth: ', ' '.join(f'{classes[labels[j]]:5s}' for j in range(4)))
기본 내장 함수인 iter()를 사용하여 testloader의 이터레이터를 만들고
next() 함수를 사용하여 이터레이터의 첫번째 데이터부터 차례대로 갖고 온다.
데이터를 하나씩 확인해볼 때 iter() 함수를 사용한다.
next() 함수를 사용해서 첫번째, 두번째, ... 데이터를 뽑는다.

GroundTruth : cat ship ship plane
학습이 끝난 모델을 불러와서 예측해보자!
net = Net()
net.load_state_dict(torch.load(PATH))
outputs = net(images)
_, predicted = torch.max(outputs, 1)
print('Predicted: ', ' '.join(f'{classes[predicted[j]]:5s}' for j in range(4)))
torch.max 부분은 outputs의 각 결과에서 가장 큰 값 1개만 뽑는다는 얘기이다.
원래 반환값으로 values 와 indices가 있는데,
values는 실제 입력데이터에서 가장 큰 값들이고,
indices는 그 가장 큰 값들의 index가 나온다.
우리에게 필요한것은 index뿐이므로 values는 버리고 indices만 prediceted 변수에 받아오는 것이다.
그 결과, 네트워크의 추론 결과와 정답값이 같은 것을 확인했다.
이제 다음에는 전체 테스트 데이터셋에 대한 정확도를 구해보자.
correct = 0
total = 0
# 학습 중이 아니므로, 출력에 대한 변화도를 계산할 필요가 없습니다
with torch.no_grad():
for data in testloader:
images, labels = data
# 신경망에 이미지를 통과시켜 출력을 계산합니다
outputs = net(images)
# 가장 높은 값(energy)를 갖는 분류(class)를 정답으로 선택하겠습니다
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'Accuracy of the network on the 10000 test images: {100 * correct // total} %')
이제 어떤 것들을 더 잘 분류하고, 어떤 것들을 더 못했는지 알아보자
# 각 분류(class)에 대한 예측값 계산을 위해 준비
correct_pred = {classname: 0 for classname in classes}
total_pred = {classname: 0 for classname in classes}
# 변화도는 여전히 필요하지 않습니다
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predictions = torch.max(outputs, 1)
# 각 분류별로 올바른 예측 수를 모읍니다
for label, prediction in zip(labels, predictions):
if label == prediction:
correct_pred[classes[label]] += 1
total_pred[classes[label]] += 1
# 각 분류별 정확도(accuracy)를 출력합니다
for classname, correct_count in correct_pred.items():
accuracy = 100 * float(correct_count) / total_pred[classname]
print(f'Accuracy for class: {classname:5s} is {accuracy:.1f} %')
'🖼 Computer Vision > Object Detection' 카테고리의 다른 글
| CV - YOLO V1, V2, V3 (You Only Look Once) (0) | 2022.05.19 |
|---|---|
| CV - SSD (Single Shot Detector) (0) | 2022.05.17 |
| CV - MMDetection (0) | 2022.05.04 |
| CV - Faster RCNN (2) | 2022.04.29 |
| CV - Fast RCNN (0) | 2022.04.28 |