

📌 이 글은 권철민님의 딥러닝 컴퓨터 비전 완벽 가이드 강의를 바탕으로 정리한 내용입니다.

목차
- Ultalytics YOLO Custom Dataset 만들기
- Oxford Pet Dataset Download
- Ultralytics YOLO 포멧 디렉토리 구조 만들기
- Oxford Pet Train / Valid 메타데이터 만들기
- Oxford Pet annotation을 Ultralytics YOLO 포멧으로 만들기
- 전체 xml 파일들을 YOLO 포멧으로 변환 후 Ultralytics 디렉토리 구조로 입력하기
- Oxford Pet Dataset yaml 파일 만들기
- Oxford Pet Dataset 학습 수행
- 학습된 모델 파일을 이용하여 Inference 수행
- test.py를 이용하여 Test 데이터를 Evalutation
1. Ultalytics YOLO Custom Dataset 만들기
1.1. Oxford Pet Dataset Download
구글 Colab 환경에서 진행하였다.
$ wget https://www.robots.ox.ac.uk/~vgg/data/pets/data/images.tar.gz
$ wget https://www.robots.ox.ac.uk/~vgg/data/pets/data/annotations.tar.gz
다운로드가 완료되면 압축을 풀어 준다.
# /content/data 디렉토리를 만들고 해당 디렉토리에 다운로드 받은 압축 파일 풀기.
$ mkdir /content/data
$ tar -xvf images.tar.gz -C /content/data
$ tar -xvf annotations.tar.gz -C /content/data
3680개의 jpg 이미지와 annotation 파일이 존재한다.
1.2. Ultralytics YOLO 포멧 디렉토리 구조 만들기
Ultralytics YOLO annotation의 공통 포맷은 공백으로 구분 된 0~1 값 사이의 5개의 컬럼(class id, x, y, w, h)이었다.
하지만 그 전에 디렉토리 구조를 나눠줘야 한다.
그래서 coco128 Dataset 학습에서 확인했던 것처럼 images 디렉토리와 labels 디렉토리 구조를 만들어 주어야 한다.
# Ultralytics Yolo images와 labels 디렉토리를 train, val 용으로 생성
!mkdir /content/ox_pet;
!cd /content/ox_pet; mkdir images; mkdir labels;
!cd /content/ox_pet/images; mkdir train; mkdir val
!cd /content/ox_pet/labels; mkdir train; mkdir val
이렇게 images 디렉토리 안에 train, val 디렉토리 구조, labels 디렉토리 안에 train, val 디렉토리 구조로 만들어 준다.
1.3. Oxford Pet Train / Valid 메타데이터 만들기
import pandas as pd
pd.read_csv('/content/data/annotations/trainval.txt', sep=' ', header=None, names=['img_name', 'class_id', 'etc1', 'etc2'])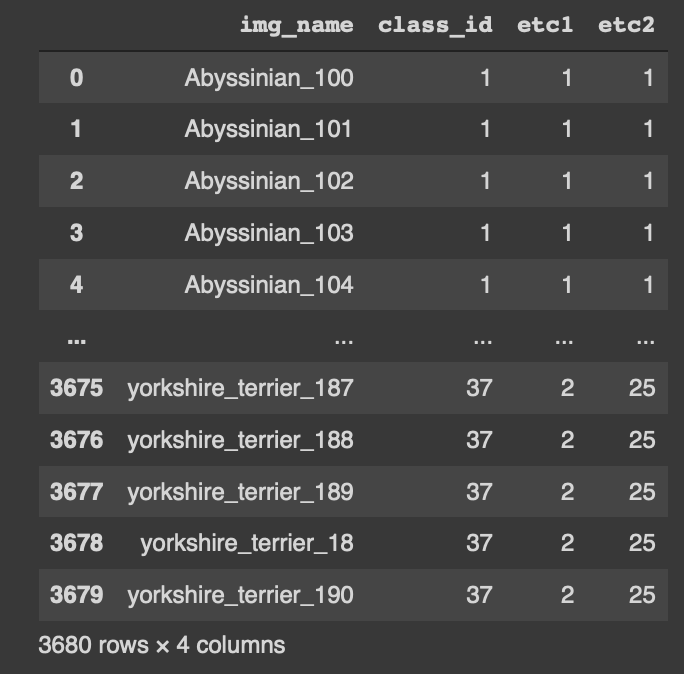
trainval.txt annotation을 보면 3680개의 데이터프레임을 확인할 수 있다.
import os
import pandas as pd
from sklearn.model_selection import train_test_split
# 전체 image/annotation 파일명을 가지는 리스트 파일명을 입력 받아 메타 파일용 DataFrame 및 학습/검증용 DataFrame 생성.
def make_train_valid_df(list_filepath, img_dir, anno_dir, test_size=0.1):
pet_df = pd.read_csv(list_filepath, sep=' ', header=None, names=['img_name', 'class_id', 'etc1', 'etc2'])
#class_name은 image 파일명에서 맨 마지막 '_' 문자열 앞까지에 해당.
pet_df['class_name'] = pet_df['img_name'].apply(lambda x:x[:x.rfind('_')])
# image 파일명과 annotation 파일명의 절대경로 컬럼 추가
pet_df['img_filepath'] = img_dir + pet_df['img_name']+'.jpg'
pet_df['anno_filepath'] = anno_dir + pet_df['img_name']+'.xml'
# annotation xml 파일이 없는데, trainval.txt에는 리스트가 있는 경우가 있음. 이들의 경우 pet_df에서 해당 rows를 삭제함.
pet_df = remove_no_annos(pet_df)
# 전체 데이터의 10%를 검증 데이터로, 나머지는 학습 데이터로 분리.
train_df, val_df = train_test_split(pet_df, test_size=test_size, stratify=pet_df['class_id'], random_state=2021)
return pet_df, train_df, val_df
# annotation xml 파일이 없는데, trainval.txt에는 리스트가 있는 경우에 이들을 dataframe에서 삭제하기 위한 함수.
def remove_no_annos(df):
remove_rows = []
for index, row in df.iterrows(): # 해당 row의 index 번호와 나머지전체를 가져온다.
anno_filepath = row['anno_filepath']
if not os.path.exists(anno_filepath):
print('##### index:', index, anno_filepath, '가 존재하지 않아서 Dataframe에서 삭제함')
#해당 DataFrame index를 remove_rows list에 담음.
remove_rows.append(index)
# DataFrame의 index가 담긴 list를 drop()인자로 입력하여 해당 rows를 삭제
df = df.drop(remove_rows, axis=0, inplace=False)
return df
pet_df, train_df, val_df = make_train_valid_df('/content/data/annotations/trainval.txt',
'/content/data/images/', '/content/data/annotations/xmls/', test_size=0.1)
위 코드를 실행해주면 파일에 대한 리스트를 가지고 있는 것들을 인자로 받아서, train test 데이터를 분리하고, train test 데이터 경로를 저장한 메타 데이터를 만든다.
iterrows() : 해당 데이터 프레임의 모든 row의 index와 index를 제외한 나머지 전체를 가져온다.
for index, row in pet_df.iterrows():
print(index, row['anno_filepath'])
import os
for index, row in pet_df.iterrows():
anno_filepath = row['anno_filepath']
if not os.path.exists(anno_filepath):
print(anno_filepath)따라서 위 코드를 실행 시켰을 때는 아무것도 나오지 않아야 한다.
1.4. Oxford Pet 데이터 세트의 annotation을 Ultralytics YOLO 포멧으로 만들기
- annotation용 .xml 파일을 .txt 파일로 변환
- 하나의 이미지는 하나의 .txt 파일로 변환
- 확장자를 제외한 이미지의 파일명과 annotation 파일명이 서로 동일해야 함.
- 하나의 .xml annotation 파일을 Yolo 포맷용 .txt 파일로 변환하는 함수 생성
- voc annotation의 좌상단(Top left: x1, y1), 우하단(Bottom right: x2, y2) 좌표를 Bounding Box 중심 좌표(Center_x, Center_y)와 너비(width), 높이(height)로 변경
- 중심 좌표와 너비, 높이는 원본 이미지 레벨로 scale 되어야 함. 모든 값은 0~1 사이 값으로 변환됨.
- class_id는 여러개의 label들을 0 부터 순차적으로 1씩 증가시켜 id 부여
# Class 명을 부여. Class id는 자동적으로 CLASS_NAMES 개별 원소들을 순차적으로 0부터 36까지 부여
CLASS_NAMES = pet_df['class_name'].unique().tolist()
Oxford Pet Dataset의 annotation 파일(.xml)을 Ultralytics YOLO annotation 포맷(.txt)으로 변환하는 코드
import glob
import xml.etree.ElementTree as ET
# 1개의 voc xml 파일을 Yolo 포맷용 txt 파일로 변경하는 함수
def xml_to_txt(input_xml_file, output_txt_file, object_name):
# ElementTree로 입력 XML파일 파싱.
tree = ET.parse(input_xml_file)
root = tree.getroot()
img_node = root.find('size')
# img_node를 찾지 못하면 종료
if img_node is None:
return None
# 원본 이미지의 너비와 높이 추출.
img_width = int(img_node.find('width').text)
img_height = int(img_node.find('height').text)
# xml 파일내에 있는 모든 object Element를 찾음.
value_str = None
with open(output_txt_file, 'w') as output_fpointer:
for obj in root.findall('object'):
# bndbox를 찾아서 좌상단(xmin, ymin), 우하단(xmax, ymax) 좌표 추출.
xmlbox = obj.find('bndbox')
x1 = int(xmlbox.find('xmin').text)
y1 = int(xmlbox.find('ymin').text)
x2 = int(xmlbox.find('xmax').text)
y2 = int(xmlbox.find('ymax').text)
# 만약 좌표중에 하나라도 0보다 작은 값이 있으면 종료.
if (x1 < 0) or (x2 < 0) or (y1 < 0) or (y2 < 0):
break
# object_name과 원본 좌표를 입력하여 Yolo 포맷으로 변환하는 convert_yolo_coord()함수 호출.
class_id, cx_norm, cy_norm, w_norm, h_norm = convert_yolo_coord(object_name, img_width, img_height, x1, y1, x2, y2)
# 변환된 yolo 좌표를 object 별로 출력 text 파일에 write
value_str = ('{0} {1} {2} {3} {4}').format(class_id, cx_norm, cy_norm, w_norm, h_norm)
output_fpointer.write(value_str+'\n')
# debugging용으로 아래 출력
#print(object_name, value_str)
# object_name과 원본 좌표를 입력하여 Yolo 포맷으로 변환
def convert_yolo_coord(object_name, img_width, img_height, x1, y1, x2, y2):
# class_id는 CLASS_NAMES 리스트에서 index 번호로 추출.
class_id = CLASS_NAMES.index(object_name)
# 중심 좌표와 너비, 높이 계산.
center_x = (x1 + x2)/2
center_y = (y1 + y2)/2
width = x2 - x1
height = y2 - y1
# 원본 이미지 기준으로 중심 좌표와 너비 높이를 0-1 사이 값으로 scaling
center_x_norm = center_x / img_width
center_y_norm = center_y / img_height
width_norm = width / img_width
height_norm = height / img_height
return class_id, round(center_x_norm, 7), round(center_y_norm, 7), round(width_norm, 7), round(height_norm, 7)
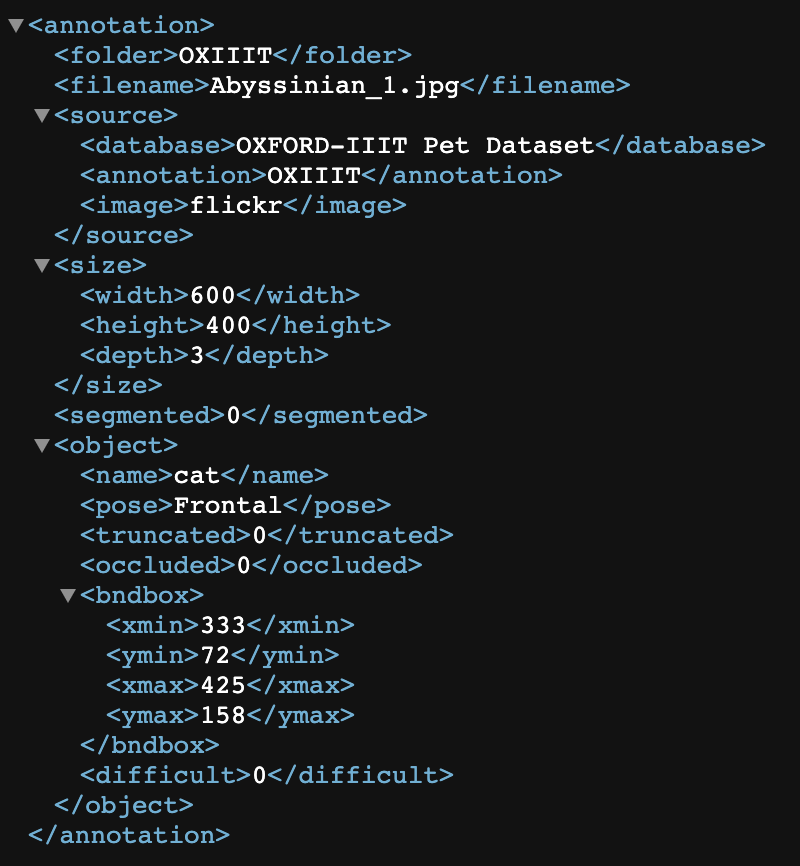
xml 파일에서 parsing을 한 다음에 root를 찾는다.
그 중에서 'size' 를 찾고, 거기서 width와 height를 찾는다.
그리고 이것들을 하나의 파일로 만들어주어야 한다.
object를 찾고 그 안에서 bounding box를 찾는다. 좌표값 오류를 제외한 좌상단, 우하단 좌표를 받고 만들어준 convert_yolo_coord() 함수를 써서, YOLO 포멧대로 공백으로 구분된 normalize 된 (class id, x, y, w, h)를 받는다.
xml_to_txt('/content/data/annotations/xmls/Abyssinian_1.xml', '/content/ox_pet/labels/train/Abyssinian_1.txt', 'Abyssinian')
하나의 데이터를 위의 함수를 적용해서 .txt 파일로 만들고 확인해보면

이렇게 만들어진 것을 확인할 수 있다.
이제 전체 데이터에 적용해보자.
1.5. 전체 xml 파일들을 YOLO 포멧으로 변환 후 Ultralytics 디렉토리 구조로 입력하기
- VOC XML 파일들이 있는 디렉토리와 변환하여 출력될 Yolo format .txt 파일들이 있을 디렉토리를 입력하여 파일들을 생성.
import shutil
def make_yolo_anno_file(df, tgt_images_dir, tgt_labels_dir):
for index, row in df.iterrows():
src_image_path = row['img_filepath']
src_label_path = row['anno_filepath']
# 이미지 1개당 단 1개의 오브젝트만 존재하므로 class_name을 object_name으로 설정.
object_name = row['class_name']
# yolo format으로 annotation할 txt 파일의 절대 경로명을 지정.
target_label_path = tgt_labels_dir + row['img_name']+'.txt'
# images 파일 만들기
# image의 경우 target images 디렉토리로 단순 copy
shutil.copy(src_image_path, tgt_images_dir)
# annotation 파일 만들기
# annotation의 경우 xml 파일을 target labels 디렉토리에 Ultralytics Yolo format으로 변환하여 만듬
xml_to_txt(src_label_path, target_label_path, object_name)
# train용 images와 labels annotation 생성.
make_yolo_anno_file(train_df, '/content/ox_pet/images/train/', '/content/ox_pet/labels/train/')
# val용 images와 labels annotation 생성.
make_yolo_anno_file(val_df, '/content/ox_pet/images/val/', '/content/ox_pet/labels/val/')
위에서 작업한 것을 보면 train_df 에는 개별 파일에 대한 image 절대경로와 label 절대경로가 들어 있다.
이것들을 iteration 돌려서 개별 image 절대경로와 label 절대경로를 가져와서
data/annotation/images 에 있는 파일들을,
ox_pet/images/train, ox_pet/images/label, ox_pet/labels/train, ox_pet/labels/val에 copy를 해주는 것이다.
그래서 위 코드를 실행하면
이렇게 데이터가 만들어진다.
1.6. Oxford Pet Dataset yaml 파일 만들기
- 생성된 Directory 구조에 맞춰서 dataset용 yaml 파일 생성.
이제 지금까지 만든 데이터를 Data config yaml 파일로 만든다.
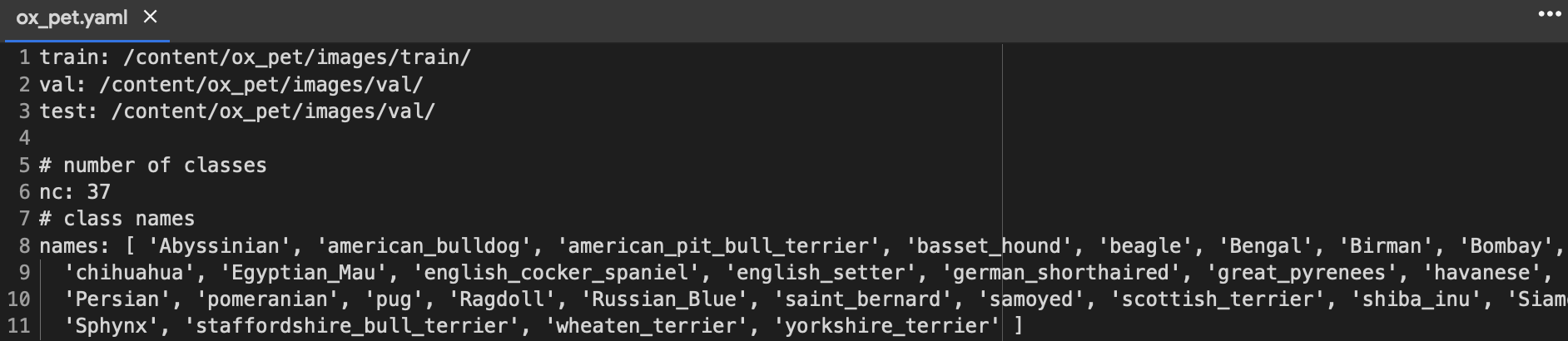
여기서 test는 validation 할 때 쓰인다.
2. Oxford Pet Dataset 학습 수행
# Google Drive 접근을 위한 Mount 적용.
import os, sys
from google.colab import drive
drive.mount('/content/gdrive')
# soft link로 Google Drive Directory 연결.
!ln -s /content/gdrive/My\ Drive/ /mydrive
!ls /mydrive
# Google Drive 밑에 Directory 생성. 이미 생성 되어 있을 시 오류 발생.
!mkdir "/mydrive/ultra_workdir"1시간 동안 colab 안꺼지게 하는 코드
### 10번 미만 epoch는 좋은 성능이 안나옴. 최소 30번 이상 epoch 적용.
python train.py --img 640 \
--batch 16 \
--epochs 20 \
--data /content/ox_pet/ox_pet.yaml \
--weights yolov3.pt \
--project=/mydrive/ultra_workdir \
--name pet \
--exist-ok--img : image size
--batch : batch size
--epochs : epoch
--data : dataset에 대한 yaml 파일
--weight : pretrained weight를 사용한다. 없으면 다운 받는다.
--project : 저장되는 장소
--name
--nosave : 옵션 안주면 last, best 두가지가 저장된다(맨 마지막 것과, loss가 낮은 것). 옵션을 주면 마지막 것만 저장
3. 학습된 모델 파일을 이용하여 Inference 수행
- 이미지 파일과 영상 파일로 inference 수행.
# image 파일 inference
!cd yolov3;python detect.py --source /content/data/images/pug_100.jpg --weights /mydrive/ultra_workdir/pet/weights/best.pt --conf 0.2 \
--project=/content/data/output --name=run_image --exist-ok --line-thickness 24. test.py를 이용하여 Test 데이터를 Evalutation하기
# Run YOLOv3 on COCO val2017
!cd yolov3; python test.py --weights /mydrive/ultra_workdir/pet/weights/best.pt --data /content/ox_pet/ox_pet.yaml \
--project /content/data/output --name=test_result --exist-ok --img 640 --iou 0.65
'🖼 Computer Vision > Object Detection' 카테고리의 다른 글
| CV - EfficientDet (0) | 2022.06.02 |
|---|---|
| CV - Focal loss (0) | 2022.06.02 |
| CV - Ultralytics YOLO v3 (coco128 Dataset) (0) | 2022.05.26 |
| CV - YOLO V1, V2, V3 (You Only Look Once) (0) | 2022.05.19 |
| CV - SSD (Single Shot Detector) (0) | 2022.05.17 |