
📌 이 글은 권철민님의 딥러닝 컴퓨터 비전 완벽 가이드 강의를 바탕으로 정리한 내용입니다.
목차
- SPPNet의 한계
- Fast RCNN과 SPPNet의 차이
- Fast RCNN
- ROI Pooling
- Softmax
- Fast RCNN의 구조
- Fast RCNN의 Loss function
- Contribution
SPPNet의 한계
SPPNet에 대해 요약해 보면, SPP-Net은 인풋 이미지를 바로 CNN에 넣고 특징을 추출해서 피쳐맵을 만든다. 그리고 그것을 Spatial Pyramid Pooling layer에 집어넣어서 Region단위 연산으로 RoI를 만들어낸다. 이 SPP layer는 CNN에서 올라온 Feature map을 분면으로 나누면서 Max pooling하고 그 결과를 하나의 벡터로 결합하므로써 위치에 대한 정보를 만든다. 그 결과물을 FC layer에 넣고 순차적으로 SVM과 Boudning box regressor에 넣게 된다. RCNN에 비해서 속도가 빨라졌다는 장점이 있지만 아직 3단계 파이프라인의 한계(Region Proposal → Softmax, SVM → Bounding Box Regression)를 벗어나지는 못했다. 따라서 Back Propagation을 하지 못한다.
한 이미지의 Object들에 대해서 2000번 CNN 돌리지 말고 SPP layer에 맵핑을 시켜버린 다음에 CNN 돌리자
Fast RCNN과 SPPNet 과의 차이

- 모두 동일한 사이즈의 Region Proposal을 만들기 위해 SPP를 사용하지 않고 ROI(Regions Of Interest) Pooling를 사용한다.
- Object가 무엇인지 클래스를 분류할 때 SVM Classifier을 사용하지 않고 Softmax Layer만을 사용한다.
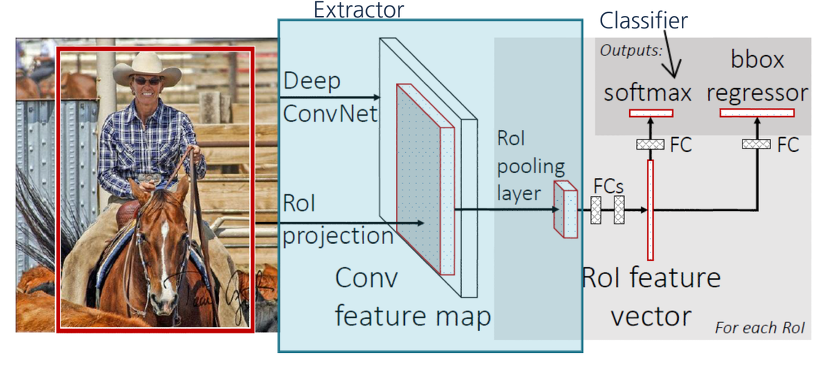
Fast RCNN

Fast RCNN도 RCNN과 똑같이 처음에 Selective Search를 통해 Region Proposal을 뽑아내긴 한다.
하지만 R-CNN과 다르게 뽑아낸 영역을 Crop하지 않고 그대로 가지고 있고,
전체 이미지를 CNN 모델에 집어 넣은 후,
CNN으로부터 나온 Feature Map에 RoI Projection을 하는 방식이다.
즉 input image 1장으로부터 CNN Model에 들어가는 이미지는 2000장 → 1장이 된다.
ROI (Region of Interest) Pooling

이 Projection 한 Bounding Box들을 RoI Pooling 하는 것이 Fast R-CNN의 핵심이다.
위 그림처럼 Projection시킨 RoI를 FCs(Fully Connected Layer)에 넣기 위해서는 같은 Resolution의 Feature map이 필요하다.
하지만 Selective Search를 통해 구해졌던 RoI 영역은 각각 다른 크기를 가지고 있다. 따라서 이 Resolution의 크기를 맞춰주기 위해 RoI Pooling을 수행한다.
사실 SPP 과정도 ROI Pooling 과정이라고 할 수 있다. ROI Pooling 의 구체적인 정의는 서로 크기가 다른 Region Proposal을 고정된 벡터 사이즈로 만드는 것을 의미한다. 여기서는 SPP Net과의 차이점을 강조하기 위해 Fast RCNN에서만 ROI Pooling이라고 정의하겠다.
즉, 크기가 다른 Feature Map의 Region마다 Stride를 다르게 Max Pooling을 진행하여 결과값을 맞추는 방법이다.

위 그림의 박스 1개가 1개의 픽셀을 뜻한다.
위와 같이 8x8 input feature map에서 Selective Search로 뽑아냈던 7x5 짜리 Region Proposal 부분이 있고,
이를 2x2로 만들어주기 위해 Stride (7/2 = 3, 5/2 = 2) 로 Pooling Sections를 정하고,
Max pooling 하여 2x2 output을 얻어 낸다.

ROI Pooling은 SPP Pooling 과정과 동작과정은 동일하다. 단, 분면을 여러 번 수행하지 않고 단 7×7 분면으로 나눈 것 하나로만 SPP를 수행한다는 것이 차이점이다.
Softmax

마지막으로 Fixed Length Feature Vector를 FCs(Fully Connected Layer)에 집어 넣은 후, 두 자식 layer인 output layer로 뻗어 나가 Classification과 Bounding box Regression을 진행 한다.
이는 R-CNN과 비슷하게 진행 하였지만 Fast R-CNN은 Softmax를 사용하여 Classification을 진행 하였다.
Softmax만 사용하는 이유
이전의 SPP Net 모델까지는 먼저 Softmax Layer로 Object가 어떤 클래스인지 확률값으로 도출시키면서 파라미터를 학습하고 다시 최종 클래스 분류를 위해 SVM Classifier를 사용했다. 하지만 이렇게 하게 되면 보다시피 2번 수행하는 번거로움이 있게 되고 결국 End-to-End 모델이 되지 못한다.
그래서 SVM Classifier 를 없애버리고 Softmax Layer 하나만을 두고 Object의 최종 클래스를 분류시킨다. 이렇게 함으로써 Object의 클래스를 최종 분류하는 문제와 Object를 탐지해 감싸는 Bounding Box의 좌표를 회귀하는 문제 2개를 동시에 학습시키게 된다. 즉, 이제 End-to-End 모델이 되는 것이다.
Fast RCNN 구조

Classification, Bb Regression Loss를 함께 반영해서 Loss를 만들 수 있다.
이 얘기는 Back Propagation을 할 수 있다는 뜻이다.
Fast RCNN의 Loss Function

Classification과 Bb Regression을 동시에 해결해서 Multi-task loss 라고도 불린다.
Classification에서는 Cross Entropy를 사용하고 Bb Regression에서는 Smooth L1 함수를 이용한다.


Smooth L1 함수에서 x값에 따라 함수식이 달라진다. 여기서 x는 오차(Error)이다.
|x| < 1 일 때는 L2 Loss 유형의 식을, 그 이외의 경우에는 유형의 식을 따른다.
어떤 식을 따르냐에 따라 오차 함수의 의미가 달라진다.
- L2 Loss : 제곱을 사용하기 때문에 지나치게 오차가 큰 데이터에 매우 민감하게 작용한다. 따라서 오차가 큰 데이터가 많이 존재할 경우 L2를 사용하면 오차가 큰 데이터에 큰 패널티를 부여함으로써 학습 시 오차가 큰 데이터를 잘 학습하도록 해준다.
- L1 Loss : 절댓값을 사용하기 때문에 지나치게 오차가 큰 데이터에 민감하지 않다. 따라서 오차가 큰 데이터가 별로 존재하지 않을 때 사용하기에 적합하다.
- Smooth L1 Loss : 오차)가 −1 보다 크거나 보다 작을 때는 거의 맞췄다고 인정한다.

Contribution

- 뛰어난 성능
- End-to-end로 Single Stage Training을 진행 : Single Stage Detector는 아님 (Region Proposal로 Selective Search를 수행하기 때문)
- Back Propagation 기능 (모든 Computation을 Share하여 End-to-End Training을 진행)
- 저장공간이 필요가 없음 (R-CNN의 경우에 CNN에서 나온 Feature Map을 Disk에 집어 넣고 SVM을 진행할 때 불러오는 방식으로 진행)
Ref. 딥러닝 컴퓨터비전 완벽가이드, 앎의 공간
'🖼 Computer Vision > Object Detection' 카테고리의 다른 글
| CV - MMDetection (0) | 2022.05.04 |
|---|---|
| CV - Faster RCNN (2) | 2022.04.29 |
| CV - SPPNet (Spatial Pyramid Pooling) (0) | 2022.04.28 |
| CV - RCNN (Region with CNN features) (0) | 2022.04.28 |
| CV - Object Detection Architecture (0) | 2022.04.28 |