ML - Ensemble Learning
2021. 11. 22. 15:33
💡 AI/ML
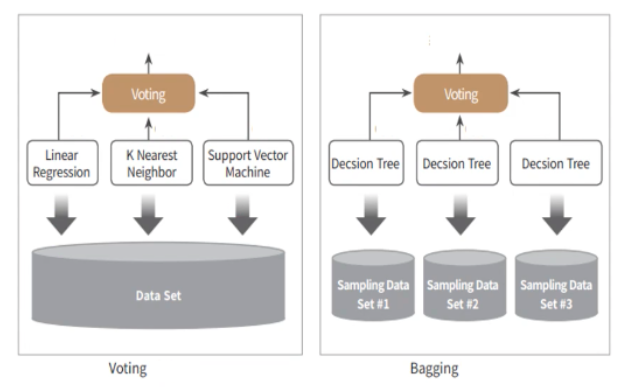
Ensemble Learning Ensemble Learning : 여러 개의 Classifier를 생성하고, 예측을 결합해서, 단일 Classifier보다 정확한 예측 결과를 도출하는 기법 Voting, Bagging, Boosting 으로 구분할 수 있다. + Stacking Bagging : Random forest Boosting : 에이다 부스팅, 그래디언트 부스팅, XGBoost, LightGBM 특징 단일 Classifier의 약점을 다수의 모델들을 결합하여 보완 뛰어난 성능의 모델로만 구성하는 것보단 성능이 떨어지더라도, 서로 다른 유형의 모델을 섞는 것이 나을 수 있다. Voting & Bagging Voting과 Bagging은 여러개의 Classifier가 투표를 통해 최종 예측 결과..
ML - Decision Tree
2021. 11. 21. 15:12
💡 AI/ML
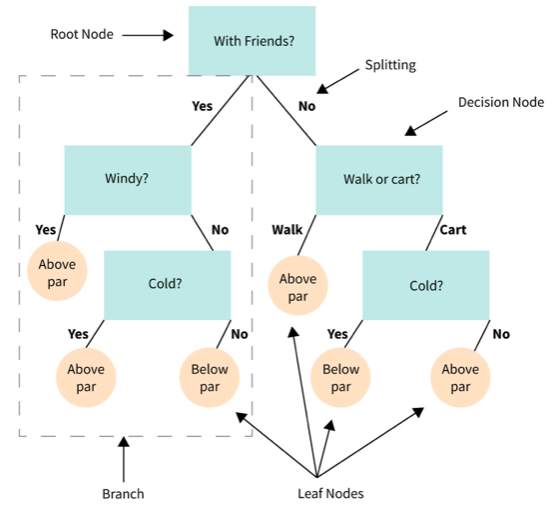
목차 Decision Tree 구조 Decision Tree의 규칙 - 균일도 기반 Information Gain Gini Coefficient (지니 계수) Decision Node 생성 프로세스 Decision Tree의 특징 Decision Tree 주요 하이퍼 파라미터 Graphviz를 통한 시각화 Decision Tree의 Feature 선택 중요도 Classification 나이브 베이즈(Naive Bayes) : 베이즈 통게와 생성 모델에 기반한 나이브 베이즈 로지스틱 회귀(Logistic Regression) : 독립변수와 종속변수의 선형 관계성에 기반한 로지스틱 회귀 결정 트리(Decision Tree) : 데이터 균일도에 따른 규칙 기반의 결정 트리 서포트 벡터 머신(Support Ve..
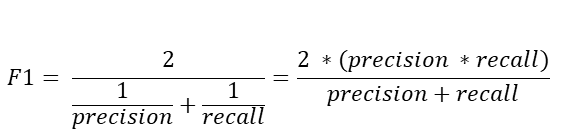
ML - F1 score, ROC-AUC
2021. 11. 19. 19:35
💡 AI/ML
F1 score F1 score는 정밀도와 재현율을 결합한 지표이다. F1 score는 정밀도와 재현율 중 한쪽으로 치우치지 않았을 때 높은 값을 가진다. 사이킷 런은 f1_score() 함수를 제공한다. ROC 곡선, AUC 머신러닝 이진 분류 모델의 예측 성능을 판단하는 지표가 된다. ROC (Receiver Operating Charateristic curve) : FPR을 x축, TPR(재현율)을 y축으로 놓고 그린 그래프 AUC (Area Under Curve) : ROC 곡선의 아래쪽 영역의 면접 = 분류 성능의 지표로 사용된다. p = prediction(predictions, labels) roc = performance(p, measure='tpr', 'x,measure='fpr') au..
ML - Confusion Matrix, Precision, Recall
2021. 11. 18. 15:45
💡 AI/ML
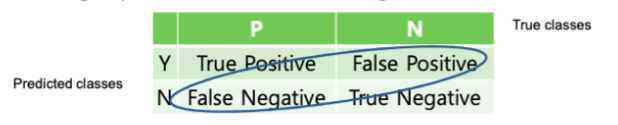
1. Confusion Matrix (오차 행렬) 오차행렬은 이진 분류의 예측 오류가 얼마인지, 어떤 유형의 예측 오류가 발생하고 있는지를 나타내는 지표이다. 예측결과, 예측 True Positive : 참으로 예측했는데, 실제로도 참일 때 = 맞음 False Positive : 참으로 예측했는데, 실제로는 거짓일 때 = 틀림 False Negative : 거짓으로 예측했는데, 실제로는 참일 때 = 틀림 True Negative : 거짓으로 예측했는데, 실제로도 거짓일 때 = 맞음 오차행렬로 예측 결과를 살펴보자. from sklearn.metrics import confusion_matrix # 앞절의 예측 결과인 fakepred와 실제 결과인 y_test의 Confusion Matrix출력 confu..

ML - 평가(evaluation)
2021. 11. 12. 15:25
💡 AI/ML
머신러닝 모델 성능 평가 지표 Accuracy(정확도) 직관적으로 모델 예측 성능을 나타낼 수 있지만, 이진분류의 경우 숫자 놀음이 될 수 있다. (예측 결과랑 동일한 데이터 수) / (전체 예측 데이터 수) Confusion Matrix(오차 행렬) Precision(정밀도) Recall(재현율) F1 score : 정밀도와 재현율이 얼마나 균형 잡혀 있는 지 확인한다. ROC AUC : 이진분류에서 굉장히 많이 사용된다. import numpy as np from sklearn.base import BaseEstimator class MyDummyClassifier(BaseEstimator): # BaseEstimator를 상속받는다. # fit( ) 메소드는 아무것도 학습하지 않음. 원래라면 학습하..
Surprise
2021. 11. 10. 16:39
💡 AI/RecSys
데이터로딩 Reader : 데이터 컬럼 format, rating, scaling Dataset : Built-in, OS, DataFrame에서 데이터 로딩 모델 선정 및 학습 추천 알고리즘 설정 : SVD, KNNBasic 등 Train 데이터로 학습 : train() 예측 및 평가 예측 : test(), predict() 평가 : accuracy, rmse 등 교차검증 : cross_validate 하이퍼 파라미터 GridSearchCV 이런 데이터 포멧으로 고정이 되어 있다. userid, itemid, rating(평점) 1. 필요한 라이브러리 로딩 from surprise import SVD, Dataset, accuracy from surprise.model_selection import t..
Item-Item Collaborative Filtering (Movie Dataset)
2021. 10. 29. 14:48
💡 AI/RecSys
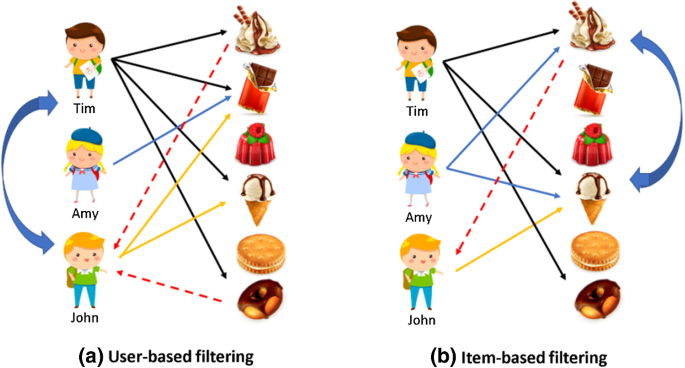
협업필터링 유형 최근접 이웃 기반 (Nearlist Neighbor) 사용자 기반 (User-user CF) 아이템 기반 (Item-item CF) 잠재요인 기반 (Latent Factor) 행렬 분해 기반 (Matrix Factorization) 특징 User behavior(item 구매 이력, 영화 평점 이력)에만 기반하여 추천 알고리즘들을 전반적으로 지칭한다. 상품, 영화 등 사용자가 아직 평가하지 않은 item에 대한 평가(rating)을 예측하는 것이 주요 역할이다. row 레벨 형태의 User-Item 평점 데이터 User ID Item ID Rating user1 item1 3 user1 item3 3 user2 item1 4 user2 item2 1 user3 item4 5 ↓ 위의 데이..