협업필터링 유형
- 최근접 이웃 기반 (Nearlist Neighbor)
- 사용자 기반 (User-user CF)
- 아이템 기반 (Item-item CF)
- 잠재요인 기반 (Latent Factor)
- 행렬 분해 기반 (Matrix Factorization)
특징
User behavior(item 구매 이력, 영화 평점 이력)에만 기반하여 추천 알고리즘들을 전반적으로 지칭한다.
상품, 영화 등 사용자가 아직 평가하지 않은 item에 대한 평가(rating)을 예측하는 것이 주요 역할이다.
row 레벨 형태의 User-Item 평점 데이터
| User ID | Item ID | Rating |
| user1 | item1 | 3 |
| user1 | item3 | 3 |
| user2 | item1 | 4 |
| user2 | item2 | 1 |
| user3 | item4 | 5 |
↓
위의 데이터를 아래와 같이 변환해주어야 한다.
↓
사용자 row, 아이템 column으로 구성된 User-Item 평점 데이터
| item1 | item2 | item3 | item4 | |
| user1 | 3 | 3 | ||
| user2 | 4 | 1 | ||
| user3 | 5 |
판다스의 pivot_table()로 쉽게 변환이 가능하다.
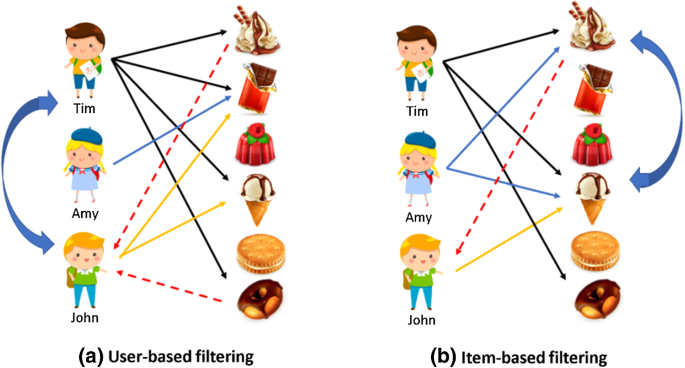
사용자 기반 (User-User)
- 특정 사용자와 비슷한 고객들을 기반으로 이 비슷한 고객들이 선호하는 다른 상품을 추천한다.
- 특정 사용자와 비슷한 상품을 구매해온 고객들은 비슷한 고객으로 간주한다.
- 당신과 비슷한 고객들이 다음 상품도 구매했습니다.
- 아이템에 대한 사용자가 준 평점 데이터들로 사용자의 유사도를 구한다. (row가 사용자)
| 다크나이트 | 인터스텔라 | 엣지오브투모로우 | 어벤저스 | 그레이50가지그림자 | |
| 사용자A | 5 | 4 | 4 | ||
| 사용자B | 5 | 3 | 4 | 5 | 3 |
| 사용자C | 4 | 3 | 3 | 2 | 5 |
사용자A는 사용자C 보다 사용자B와 영화 평점 측면에서 유사도가 높다.
따라서 사용자 A에게는 그레이50가지그림자 보단 어벤저스가 추천된다.
아이템 기반 (Item-Item)
- 특정 상품과 유사한 좋은 평가를 받은 다른 비슷한 상품을 추천한다.
- 사용자들로부터 특정 상품과 비슷한 평가를 받은 상품들은 비슷한 상품으로 간주한다.
- 이 상품을 선택한 다른 고객들은 다음 상품도 구매했습니다.
- 사용자가 준 평점 데이터들로 아이템의 유사도를 구한다. (row가 아이템)
| 사용자A | 사용자B | 사용자C | 사용자D | 사용자E | |
| 다크나이트 | 5 | 4 | 5 | 5 | 5 |
| 어벤저스 | 5 | 4 | 4 | 5 | |
| 그레이50가지그림자 | 3 | 2 | 3 | 4 |
여러 사용자들의 평점을 기준으로 볼 때, 다크나이트와 가장 유사한 영화는 어벤저스이다.
다크나이트의 벡터[5,4,5,5,5]가 그레이50가지그림자의 벡터 [3,2,3,,4] 보다 어벤저스의 벡터[5,4,4,,5]와 더 유사하다.
일반적으로 사용자 기반보다는 아이템 기반 방식이 더 선호된다.
단순히 동일한 상품을 구입하였다고 유사한 사람이라고 판단하기 어려운 경우가 많기 때문이다.
예측 평점 값 = (item 유사도 x 평점) / (item 유사도의 합)

아이템 기반 협업필터링 구현 순서
- user-item 행렬 데이터를 item-user 행렬 데이터로 변환
- item 간의 코사인 유사도로 item 유사도 산출
- user가 관람(구매)하지 않은 item 중에서 item간 유사도를 반영한 예측 점수 계산
- 예측 점수가 가장 높은 순으로 아이템 추천
Item-item CF with Movie Dataset
https://grouplens.org/datasets/movielens/

import pandas as pd
import numpy as np
movies = pd.read_csv('/content/movies.csv')
ratings = pd.read_csv('/content/ratings.csv')
print(movies.shape)
print(ratings.shape)(9742, 3)
(100836, 4)
movies.head()
movies.head()
1. pivot_table()을 이용한 user-item rating 데이터로 변환
ratings = ratings[['userId', 'movieId', 'rating']]
print(ratings.head(3))
print()
ratings_matrix = ratings.pivot_table('rating', index='userId', columns='movieId')
ratings_matrix.head(3)
# title 컬럼을 얻기 이해 movies 와 조인 수행
rating_movies = pd.merge(ratings, movies, on='movieId')
rating_movies.head(5)
# columns='title' 로 title 컬럼으로 pivot 수행.
ratings_matrix = rating_movies.pivot_table('rating', index='userId', columns='title')
# NaN 값을 모두 0 으로 변환
ratings_matrix = ratings_matrix.fillna(0)
ratings_matrix.head(5)
2. 영화와 영화 간의 유사도 산출
ratings_matrix_T = ratings_matrix.transpose()
ratings_matrix_T.head(5)
from sklearn.metrics.pairwise import cosine_similarity
item_sim = cosine_similarity(ratings_matrix_T, ratings_matrix_T)
# cosine_similarity() 로 반환된 넘파이 행렬을 영화명을 매핑하여 DataFrame으로 변환
item_sim_df = pd.DataFrame(data=item_sim, index=ratings_matrix.columns,
columns=ratings_matrix.columns)
print(item_sim_df.shape)
item_sim_df.head(5)
item_sim_df["Inception (2010)"].sort_values(ascending=False)[1:6]
인셉션과 비슷한 유사도를 가진 영화를 내림차순 정렬해보면 위와 같은 목록을 얻는다.
예측 평점 값 = (item 유사도 x 평점) / (item 유사도의 합)
def predict_rating(ratings_arr, item_sim_arr ): # 평점데이터, item유사도 데이터
# (평점 x item 유사도) / (item 유사도의 합)
ratings_pred = ratings_arr.dot(item_sim_arr)/ np.array([np.abs(item_sim_arr).sum(axis=1)])
return ratings_pred
ratings_pred = predict_rating(ratings_matrix.values , item_sim_df.values)
ratings_pred_matrix = pd.DataFrame(data=ratings_pred, index= ratings_matrix.index,
columns = ratings_matrix.columns)
print(ratings_pred_matrix.shape)
ratings_pred_matrix.head(5)
가중치 평점 부여 뒤 예측 성능 평가 MSE 구하기
from sklearn.metrics import mean_squared_error
# 사용자가 평점을 부여한 영화에 대해서만 예측 성능 평가 MSE 를 구함.
def get_mse(pred, actual):
# Ignore nonzero terms.
pred = pred[actual.nonzero()].flatten()
actual = actual[actual.nonzero()].flatten()
return mean_squared_error(pred, actual)
print('아이템 기반 모든 인접 이웃 MSE: ', get_mse(ratings_pred, ratings_matrix.values ))아이템 기반 모든 인접 이웃 MSE: 9.895354759094706
top-N 유사도를 가진 데이터들에 대해서만 예측 평점 계산
def predict_rating_topsim(ratings_arr, item_sim_arr, n=20):
# 사용자-아이템 평점 행렬 크기만큼 0으로 채운 예측 행렬 초기화
pred = np.zeros(ratings_arr.shape)
# 사용자-아이템 평점 행렬의 열 크기만큼 Loop 수행.
for col in range(ratings_arr.shape[1]):
# 유사도 행렬에서 유사도가 큰 순으로 n개 데이터 행렬의 index 반환
top_n_items = [np.argsort(item_sim_arr[:, col])[:-n-1:-1]]
# 개인화된 예측 평점을 계산
for row in range(ratings_arr.shape[0]):
pred[row, col] = item_sim_arr[col, :][top_n_items].dot(ratings_arr[row, :][top_n_items].T)
pred[row, col] /= np.sum(np.abs(item_sim_arr[col, :][top_n_items]))
return predtop-N 유사도 기반의 예측 평점 및 MSE 계산
ratings_pred = predict_rating_topsim(ratings_matrix.values , item_sim_df.values, n=20)
print('아이템 기반 인접 TOP-20 이웃 MSE: ', get_mse(ratings_pred, ratings_matrix.values ))
# 계산된 예측 평점 데이터는 DataFrame으로 재생성
ratings_pred_matrix = pd.DataFrame(data=ratings_pred, index= ratings_matrix.index,
columns = ratings_matrix.columns)아이템 기반 인접 TOP-20 이웃 MSE: 3.6949827608772314
3. 사용자가 관람하지 않은 영화 추천
def get_unseen_movies(ratings_matrix, userId):
# userId로 입력받은 사용자의 모든 영화정보 추출하여 Series로 반환함.
# 반환된 user_rating 은 영화명(title)을 index로 가지는 Series 객체임.
user_rating = ratings_matrix.loc[userId,:]
# user_rating이 0보다 크면 기존에 관람한 영화임. 대상 index를 추출하여 list 객체로 만듬
already_seen = user_rating[ user_rating > 0].index.tolist()
# 모든 영화명을 list 객체로 만듬.
movies_list = ratings_matrix.columns.tolist()
# list comprehension으로 already_seen에 해당하는 movie는 movies_list에서 제외함.
unseen_list = [ movie for movie in movies_list if movie not in already_seen]
return unseen_list
def recomm_movie_by_userid(pred_df, userId, unseen_list, top_n=10):
# 예측 평점 DataFrame에서 사용자id index와 unseen_list로 들어온 영화명 컬럼을 추출하여
# 가장 예측 평점이 높은 순으로 정렬함.
recomm_movies = pred_df.loc[userId, unseen_list].sort_values(ascending=False)[:top_n]
return recomm_movies
# 사용자가 관람하지 않는 영화명 추출
unseen_list = get_unseen_movies(ratings_matrix, 9)
# 아이템 기반의 인접 이웃 협업 필터링으로 영화 추천
recomm_movies = recomm_movie_by_userid(ratings_pred_matrix, 9, unseen_list, top_n=10)
# 평점 데이타를 DataFrame으로 생성.
recomm_movies = pd.DataFrame(data=recomm_movies.values,index=recomm_movies.index,columns=['pred_score'])
recomm_movies
'💡 AI > RecSys' 카테고리의 다른 글
| Surprise (0) | 2021.11.10 |
|---|---|
| Contents Based Filtering (Movie Dataset) (0) | 2021.10.05 |
| SKT AI - 추천시스템 (0) | 2021.09.29 |
| 연관분석 (0) | 2021.06.16 |