

📌 이 글은 권철민님의 딥러닝 컴퓨터 비전 완벽 가이드 강의를 바탕으로 정리한 내용입니다.
목차
- EfficientNet
- EfficientNet Architecture 개요
- EfficientNet 개별 Scaling 요소에 따른 성능 향상 테스트
- EfficientNet Compound Scaling
- EfficientDet
- EfficientDet 성능
- EfficientDet = BiFPN + Compound Scaling
- BiFPN (Bi directional FPN)
- Cross-Scale Connection
- Weighted Feature Fusion
- Compound Scaling
- Backbone network
- BiFPN network
- Box/class prediction network
- Input image resolution
EfficientNet

네트워크의 깊이(Depth), 필터 수(Width), 이미지 Resolution 크기를 최적으로 조합하여 모델의 성능을 극대화했다.
따로 국밥처럼 따로 최적으로 하는게 아니라 부산에 있는 수변최고국밥 마냥 국물, 고기, 야채 조합이 지리게 들어가 있다.
EfficientNet Architecture 개요
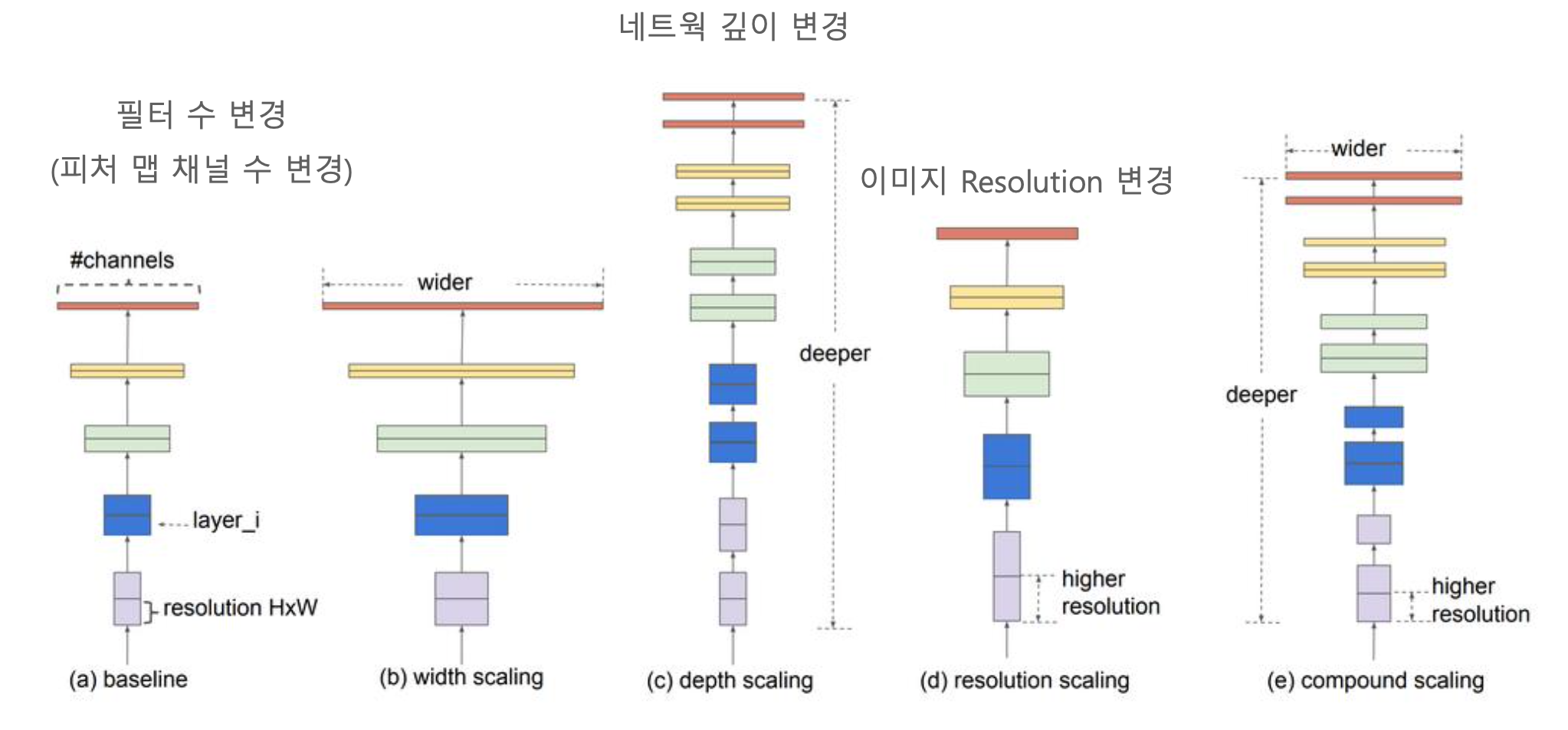
네트워크의 깊이(Depth), 필터 수(Width), 이미지 Resolution 크기를 최적으로 조합하여 모델의 성능을 극대화했다.
EfficientNet 개별 Scaling 요소에 따른 성능 향상 테스트

- 필터 수(Width) : 너비라고 표현하기도 한다. Conv2D()의 맨 처음 파라미터로 적는다. 기본 필터는 보통 3by3 크기의 커널에 256개 이다. 필터 수가 많으면 너비가 넓어질 수 밖에 없다.
- 깊이(Depth) : weight 층이 있는 레이어가 몇개인가? 깊이는 곧 레이어의 개수이다.
- 이미지 Resolution : 말그대로 이미지의 해상도이다.
필터 수, 네트워크 깊이를 일정 수준 이상 늘려도 성능 향상 미비했다.
단, Resolution이 경우 어느 정도 약간씩 성능 향상이 지속되었다.
ImageNet 데이터세트 기준 80% 정확도에서 개별 Scaling 요소를 증가 시키더라도 성능 향상이 어려웠다.
EfficientNet Compound Scaling

- 이미지 해상도가 높을 경우, 더 큰 Receptive field가 더 많은 픽셀을 포함하는 비슷한 피처들을 잘 Capture 할 수 있다.
- 더 많은 필터 수를 가지면 높은 이미지 해상도의 많은 픽셀들에 대해서 세밀한 패턴을 잘 Capture 할 수 있다.
- depth(레이어 개수)와 resolution을 각각 1.0으로 고정하고 width(필터 수)만 증가시켰을 때 정확도 성능은 80%에서 수렴한다.
- depth(레이어 개수)를 2.0, resolution은 2.0으로 했을 경우 width(필터 수)만 변화시키면 비슷한 FLOPS상에서 더 나은 성능을 보인다.

depth, width, resolution에 따른 FLOPs 변화를 기반으로 최적의 식을 도출해낸다.
width, resolution은 2배가 되면 FLOPs는 4배가 된다.
이 세개를 적절히 결합하면 최적의 모델을 만들 수 있다고 생각해서 나온게 바로 EfficientNet 이다.
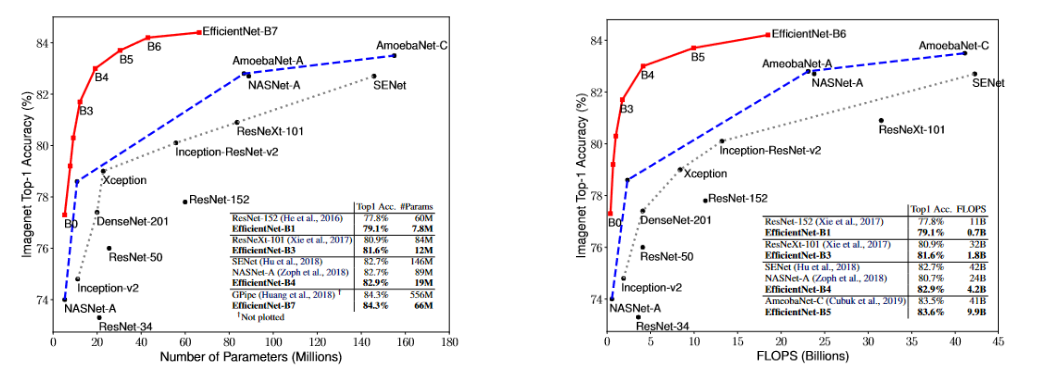
적은 파라미터 수, 적은 연산 수 대비 상대적으로 타 모델 대비 높은 예측 정확도를 나타낸다.(2019년 기준)
허나 실제 연산해보면 그렇게까지 빨리 나오진 않는다고 한다.
EfficientDet
EfficientDet 성능

YOLO v3보단 연산 횟수가 적고, AP는 살짝 높다.
FLOPs(FLoating point OPerationS)는 딥러닝 모델이 얼마나 빠르게 동작하는지에 관한 연산량 계산법이다.
FLOPs는 단위 시간(1초)에 얼마나 많은 floating point 연산을 하는지에 관한 지표이다. 보통 컴퓨터의 성능을 나타내는데 주로 사용되나, 딥러닝에서 FLOPs는 단위 시간이 아닌 절대적인 연산량(곱셈, 덧셈 등)의 횟수를 지칭한다. 따라서 약자도 FLoating point OPerationS이다.
단, FLOPs와 inference 속도가 반드시 비례하는 것은 아니다.
EfficientDet = BiFPN + Compound Scaling


BiFPN (Bi directional FPN)

Cross-Scale Connection
FPN이란, 서로 다른 크기의 객체들을 효과적으로 탐지하기 위해 Bottom-Up & Top-Down 방식으로 추출된 Feature Map들을 Lateral Connection 하는 방식이다.

기존의 FPN은 한 방향으로만 정보가 흐른다는 단점이 존재한다. 이를 해결하기 위해 PANet은 bottom-up path를 추가했다. NAS-FPN은 architecture search로 찾은 FPN의 구조를 사용하지만 시간이 매우 오래걸리고 일정한 규칙성이 없어 해석하기가 어렵다. PANet은 하나의 top-down과 하나의 bottom-up이 존재하지만, BiFPN은 양방향(top-down, bottom-up)을 지닌 레이어를 여러개 쌓는다. bidirectional한 레이어를 여러개 쌓으므로써 high-level feature fusion이 가능해진다. (Feature Fusion = 위에서 내려오면서 원본 피쳐맵과 합쳐진다) 그 후에 뒤에서 또 Compound Scaling을 한다.
BiFPN + Compound Scaling을 Cross-Scale Connection 이라고 한다.
Weighted Feature Fusion
FPN 내의 모든 input feature는 output feature에 서로 다른 영향력을 갖는다. 그렇기 때문에 각 input feature 에 가중치를 더해야 한다. 즉, 각 input feature의 중요도에 따라 가중치를 더하는 것이다.
더하기는 더하는데 input feature map에 생각을 하면서 가중치를 더하는 것이다. 어떻게 가중치를 주는게 Feature Fusion에 더 효과적인지 생각을 하면서 더하는 것이다.
서로 다른 resolution(feature map size)을 가지는 input feature map들은 Output feature map을 생성하는 기여도가 다르기 때문에 서로 다른 가중치를 부여하여 합쳐질 수 있어야 한다.

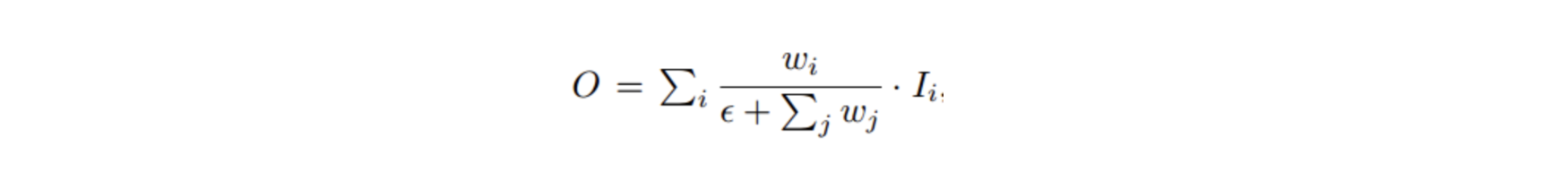
위 가중치 방법을 Fast normalized fusion이라고 표현한다. 각 가중치는 ReLU가 적용된 이후이므로 항상 0 이상의 값을 갖는다.
bidirectional cross-scale connections와 Fast normalized fusion을 결합한 BiFPN은 아래과 같은 formulation을 갖는다.

아래는 bidirectional과 weighted feature fusion의 유무에 따른 성능 차이이다.

훨씬 더 복잡한데 파라미터가 감소하고, 연산량 감소하였다?
BiFPN은 연산량 감소를 위해 Seperable Convolution을 적용하기 때문이다.
Compound Scaling
너무 거대한 Backbone, 여러 겹의 FPN, 큰 입력 이미지의 크기 등의 개별적인 부분들에 집중하는 것은 비효율적이다.
위에서 봤듯 EfficientNet은 resolution, width, depth 3가지 요소를 주어진 자원에 맞게 동시에 scale up 했다. 개별 요소들을 함께 Scaling 하면서 최적 결합을 통한 성능 향상을 보여주었다.
EfficientDet은 object detection classification 보다 고려해야 할 요소가 더 많다.
그래서 EfficientDet에서도 Backbone, BiFPN, Prediction layer(class/box network), resolution(입력 이미지 크기), 이 4가지 요소를 동시에 scale up 했다. 그리고 입력 이미지 크기를 Scaling 기반으로 최적 결합하여 D0~D7 모델로 구성하였다.

Backbone network
Compound coefficient는 0~7을 사용하여 그에 해당하는 모델은 EfficientNet-B0 ~ B7을 사용한다.
BiFPN network
Compound coefficient에 따라 BiFPN의 width와 depth를 증가시킨다.
Depth는 BiFPN 기본 반복 block을 3개로 설정하고 Scaling을 적용한다.
Width(채널 수)는 {1.2, 1.25, 1.3, 1.35, 1.4, 1.45} 중 Grid Search를 통해서 1.35로 Scaling 계수를 선택하고 이를 기반으로 Scaling을 적용한다.

Box/class prediction network
Width(채널 수)는 BiFPN 채널 수와 동일하다.
Depth는 아래 식을 적용한다.

Input image resolution

아래 그림은 각 요소를 독립적으로 scale up 했을 때와 함께 scale up 했을 때의 비교이다.

'🖼 Computer Vision > Object Detection' 카테고리의 다른 글
| CV - Mask RCNN (0) | 2022.06.11 |
|---|---|
| CV - Focal loss (1) | 2022.06.02 |
| CV - Ultralytics YOLO v3 (Oxford Pet Dataset) (0) | 2022.05.27 |
| CV - Ultralytics YOLO v3 (coco128 Dataset) (0) | 2022.05.26 |
| CV - YOLO V1, V2, V3 (You Only Look Once) (0) | 2022.05.19 |