

📌 이 글은 권철민님의 딥러닝 컴퓨터 비전 완벽 가이드 강의를 바탕으로 정리한 내용입니다.
목차
- Object Detection - Deep learning 기반으로 발전
- Localization, Detection, Segmentation
- Object Detection
- Object Detection history
- Object Detection의 주요 구성 요소
- Region Proposal (영역 추정)
- Detection을 위한 딥러닝 네트워크 : Feature Extraction(Backbone) & FPN(Neck) & Network Prediction(Head)
- 기타 요소 : IOU, NMS, mAP, Anchor Box
- 일반적인 Object Detection 모델 구조
- Object Detection의 난제
- Object Localization
- Object Localization 개요
- Object Localization - Bounding box 학습
- Object Localization 예측 결과
- 이미지의 어느 위치에서 Object를 찾아야 하는가?
- Sliding Window 와 Region Proposal 비교
- Sliding Window 방식
- Region Proposal(영역 추정) 방식
- Selective search - Region proposal의 대표적인 방법
- Selective search의 수행 프로세스
Object Detection - Deep learning 기반으로 발전

Object detection competition에서의 성능 지표를 보면 2013년을 기점으로해서 70% 후반까지의 비약적인 발전(AlexNet)을 했다.
PASCAL VOC : image detection을 위한 dataset으로 classification, object detection, segmentation 평가 알고리즘을 구축하거나 평가하는데 매우 유명한 데이터 셋.
- Annotations : JPEGImages에 담겨있는 이미지 oject detection을 위한 정답 데이터.
- ImageSets : 특정 클래스가 어떤 이미지에 있는지 등에 대한 정보를 포함하는 폴더
- JPEGImages : object dectection을 위한 입력 데이터. 이미지 파일이 모여있습니다
- SegmentationClass : Semantic segmentation을 학습하기위한 label 이미지들
- SegmentationObject : Instance segmentation을 학습하기위한 label 이미지들
Localization, Detection, Segmentation

- Classification : 이미지를 Cnn Conv 연산을 통한 피쳐맵의 특성을 기반으로 해서 무엇인가에 대한 분류를 하는 것.
- Localization : 단 하나의 Object 위치를 Bounding box로 지정하여 찾음
- Object Detection : 여러 개의 Object들에 대한 위치를 Bonding box로 지정하여 찾음.
- Segmentation : Detection보다 더 발전된 형태로 Pixel 레벨 Detection 수행
먼저 Localization이라는게 있다. 하나의 Object가 하나의 이미지에 있는 형태를 localization이라고 한다. 하나가 있다고 가정하기 때문에 Object detection보다 detection하는데 덜 어렵다. 그러나 Object detection은 하나의 이미지 안에 여러 object가 있다. 여러개의 Object를 하나의 이미지에서 바운딩박스로 detect 하는 것이 Object detection이다. 그리고 픽셀 단위로 나눠서 object를 classification 하는 것이 segmentation이다.
세가지의 공통점은 Object의 위치를 찾아내는 것이다.
차이점은
Localization / Detection 은 해당 object의 위치를 bounding box로 찾고, bounding box 내의 오브젝트를 판별하는 것이고, Bounding box regression (Bounding box가 어딨는지 좌표값을 예측을 하고 classification 하는 것)과 Classification(Bounding box안에 있는 건 무엇인가?) 두개의 문제를 같이 해결하는 것이다.
Object Detection
Object detection history
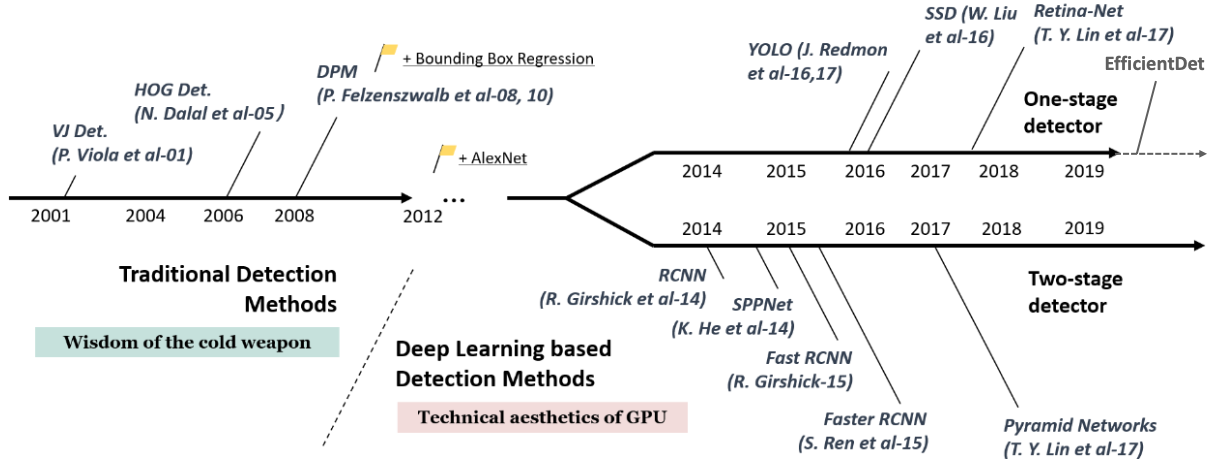
2012년 이후로 AlexNet 과 같은 딥러닝 기반 프레임웤을 쓰고, 그 첫 산물이 바로 RCNN이다.
이 중에서도 One stage detection, Two stage detection 이 있다.
Two stage detection : 오브젝트가 어딘가 특정 위치에 있을만한 곳을 찾고 나서, 그 다음 detect를 하는 방법이다.
성능이 좋지만 시간이 오래 걸려서 실시간 적용이 어려운 부분이 있다.
One stage detection : 실시간으로 오브젝트를 찾고 Detection도 진행한다.
- YOLO v1 : 수행 시간에만 집착해서 성능 별로 안좋다.
- SSD : 수행시간도 빠르고 성능도 좀 더 나아졌다.
- YOLO v2 : SSD 보다 수행 시간을 단축시키고 성능은 비슷한 정도
- RetinaNet : 당시에 나온 FasterRCNN보다 더 높은 예측성을 가졌지만 실시간으로 쓰기엔 아쉬운 부분이 있었다.
- YOLO v3 : RetinaNet에 맞먹는 예측성능과 빠른 시간
- EfficientDet : 예측 성능 향상, 시간도 욜로보다 쫌더 빨라짐
- YOLO v4 v5 등이 나오게 된다.
점점 진화하면서 성능과 시간을 잡는 방향으로 간다.
Object detection의 주요 구성 요소

- Region Proposal(영역 추정) : Object가 있을만한 위치를 미리 알려준다
- Bounding Box Regression
- Deep Learning network 구성
- Feature Extraction(Backbone)
- FPN(Neck)
- Network Prediction(Head)
- 기타 요소
- IOU
- NMS
- mAP
- Anchor Box
일반적인 Object detection 모델 구조
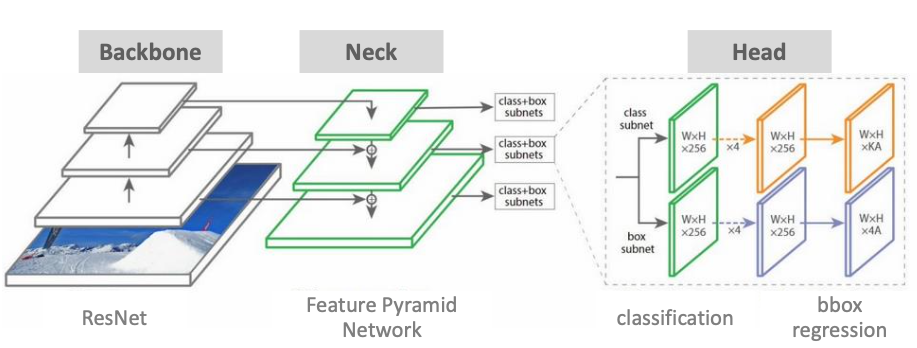
Backbone : Feature Extractor 역할
Neck : 작은 object들에 대한 정보를 체계화 → Backbone 처리를 용이하게
Head : Classification과 Bbox Regression을 한다.
Object detection의 난제
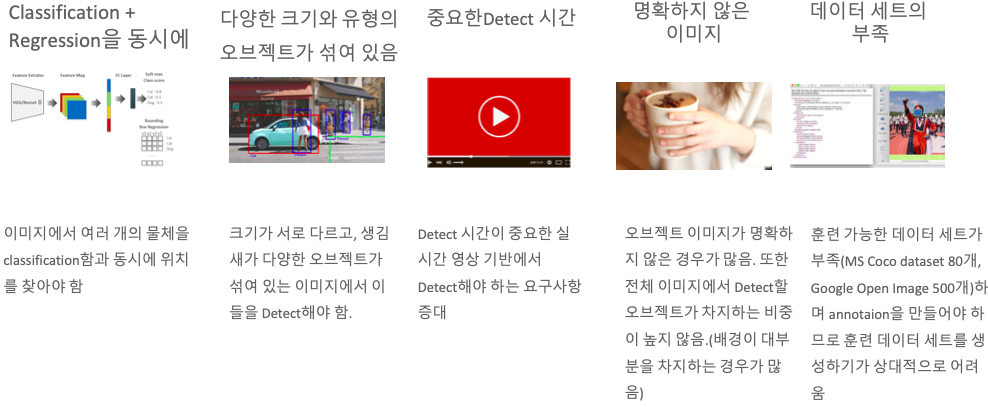
Classification, Regression을 동시에 하기 어려운 이유
- 두 layer가 각각 필요
- 두 항목 모두에 최적화된 loss 함수 필요 (loss 설정의 어려움)
- 이미지에서 여러 개의 물체를 분류함과 동시에 위치도 찾아야 한다
다양한 크기의 여러가지 유형의 Object가 섞여있다.
- 만들어지는 Feature map에 대해서 Detect를 수행하는데, Feature map은 원본 이미지 크기보다 더 작다.
- 여기서 Feature를 뽑아서 Detect를 하는게 쉽지가 않다.
Detect 시간
- 성능을 높게하면 수행시간이 떨어지고, 수행시간을 빨리하면 성능이 떨어지고, 딜레마이다.
명확하지 않은 이미지
- Object가 명확하지 않은 경우가 많다.
- 전체 이미지에서 back ground가 비중이 더 커서 Object를 찾기가 힘들다.
데이터셋의 부족
- 훈련 가능한 데이터셋 부족
- MS Coco dataset 80개
- Google Open Image 500개
- 데이터셋 생성의 어려움
- 생성 시, annotation 필요
- bounding box
Object Localization
Object localization 개요
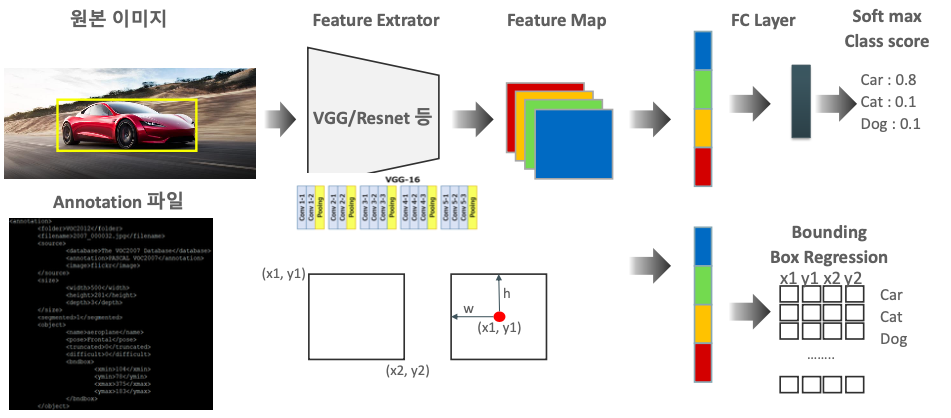
- classification과 유사한 절차
- 원본 이미지 >> Feature Extractor >> Feature Map >> FC Layer >> Soft max Class score
- Feature Extractor
- VGG(백본)에 이미지 입력
- 이미지에서 중요한 feature 뽑아냄
- Feature Map
- 사이즈 감소: 7 * 7
- 채널 수 증가: 512
- 추상화된 이미지
- 대상 학습(image-lable mapping)
- FC Layer
- dense layer
- fully connected layer
- Soft max Class score
- car vs. dog vs. cat
- 확률 계산 >> 점수(scoring)
- Annotation 파일
- bounding box에 대한 좌표값
- Object Localization
- Feature Map의 결과 (Bounding Box Regression 포함)
Backbone(Feature Extractor : 중요한 피쳐를 뽑아내서 피쳐맵을 만듦)을 통해서 피쳐맵을 만들고
Fully Connected layer를 통해 Softmax를 거쳐서 학습이 된다.
Classification 과정과 별개로,
Object Localization은 Bounding Box Regression layer가 따로 있다.
Annotation 파일에 바운딩박스에 대한 좌표 값
Classification 후의 피쳐맵에서 어떤 특성이 나온다면 Bounding Box Regression layer을 적용해라.
** Classification은 따로 하고, Annotation 파일을 가지고 Bounding Box Regression을 하는 것인가?
Object localization - Bounding box 학습

원본 이미지부터 학습을 반복하여 가중치를 업데이트 하고,
Bounding box의 예측 오류를 점점 줄여나가는 방향으로 Bounding box를 만든다.
여러 이미지와 Bounding box 좌표로 학습한다.
여러 이미지와 Bounding box 좌표로 학습

Feature가 있다면 바운딩 박스로 바로 맵핑을 할 수 있게 된다.
Object localization 예측 결과

car일 확률이 나오고 Bounding box의 좌표를 보여준다.
이미지의 어느 위치에서 Object를 찾아야 하는가?

여러개의 Object를 검출해야 한다.
- 이미지의 어느 위치에서 Object를 찾아야 하는가? 예측을 엉뚱하게 하는 경우가 있다.
- Bounding box만 무지성으로 넣으면 예측을 하기 힘들다.
- object localization을 그대로 적용하면 정확도 감소
- 여러 개의 Object로 인한 혼동
- 여러 개의 Object로 인한 혼동
- Object가 있을 법한 위치를 먼저 알려주는 것이 중요하다!
- Region Proposal 학습 필요
- 그리고 나서 Region Proposal에 해당되는 Object에 대해서 또 예측을 해주어야 한다.
Sliding Window 와 Region Proposal 비교
Object Detection의 어려움
- binding box regression 학습만으로는 inference가 어렵다
- 비슷한 object가 너무 많다.
- 유사한 feature들이 많다
Sliding Window 방식
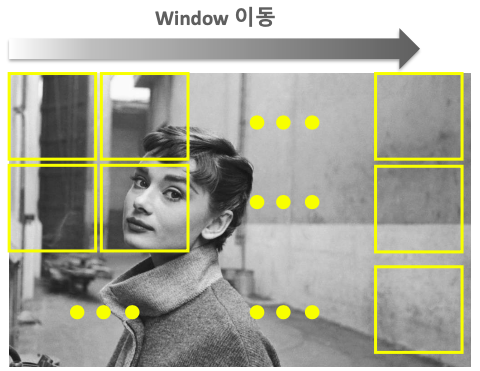
Windows를 왼쪽 상단에서 오른쪽 하단까지 이동시키면서 detect하는 방식
특정 영역에서의 특성을 학습된 feature와 매칭됨
Object Detection의 초기 기법으로 활용됨
1. 수행 시간이 오래 걸리고 검출 성능이 상대적으로 낮다
- 여러 형태의 window와 여러 scale을 가진 이미지 스캔해서 검출
- Object가 없는 영역도 무조건 슬라이딩해야 한다.
2. 영역 추정 기법의 등장으로 활용도 감소
- but Object Detection 발전을 위한 기술적 토대 제공

3. 슬라이딩 윈도우의 두 가지 방법 : Window 안에 object가 다 들어가 있지 않을 수 없다.
- 다양한 형태의 Window를 각각 sliding 시키는 방식 - 서로 다른 anchor box의 유형으로 발전
- Window Scale은 고정하고 scale을 변경한 여러 이미지를 사용하는 방식 - SSD(여러 사이즈의 feature map으로 추출) >> FPN
- 두 방법을 혼합해서 사용하기도 한다

너무 이미지를 줄이다 보면 윈도우 안에 들어오는 오브젝트들이 많아지게 되는 이슈가 있다.
Region proposal(영역 추정) 방식
목표 : "Object가 있을만한 후보 영역을 찾자"

말그대로 Object가 있을만한 후보 영역을 추정하는 방식이다.
Sliding window는 하나하나 다 찾아보기 때문에 이와 다르다.
Region proposal은 경계선에 대한 유형이 다름을 보고 판단하는 방법이다.
대표적인 Region proposal 중 하나가 Selective search 이다.
후보 바운딩 박스를 선택을 하고 최종 후보인 박스를 선정을 한다.
Selective search - Region proposal의 대표적인 방법

- 빠른 detection과 높은 recall 예측 성능을 동시에 만족하는 알고리즘
- 딥러닝 알고리즘과 통합되는 과정에서 시간 소요
- 딥러닝 알고리즘과 통합되는 과정에서 시간 소요
- 색상, 무늬(Texture), 크기, 형태에 따라 유사한 Region
- 계층적 그룹핑 방법으로 계산
- + edge(경계) detect
- 최초에는 Pixel Intensity에 기반한 graph-based segment 기법을 따름
- Segmentation: 픽셀 단위, 매우 촘촘함
- Over Segmentation 수행
- 각각의 Object들이 1개의 개별 영역에 담길 수 있도록 많은 수의 초기 영역 생성
- 원본 이미지 >> 최초 Segmentation(Over Segmentation) >> 후보 Objects
Selective search는 별도의 알고리즘이다.
Edge detect (경계선을 기준으로 차이를 보는 것)
초기에는 촘촘하게 찾아낸다.
픽셀 레벨로 촘촘하게 작업을 하고(Segmentation이라고 함) Boolean Masking을 씌운다. 같은 영역인지 아닌지를 판단한다.
그런데 Masking만 봐서는 너무 많다. 빠져나가는 Object가 없게 하기 위해서 조금 Over 하게 한다.
거기에 맞는 후보 Object를 선택 한다.
Selective search의 수행 프로세스

- 개별 Segment된 모든 부분들을 Bounding box로 만들어서 Region Proposal 리스트로 추가
- 색상, 무늬, 크기, 형태에 따라 유사도가 비슷한 Segment들을 그룹핑
- 두 과정을 계속 반복 하면서 Region Proposal을 수행
'🖼 Computer Vision > Object Detection' 카테고리의 다른 글
| CV - Object Detection 주요 데이터셋 (0) | 2022.04.23 |
|---|---|
| CV - OD 성능 평가 Metric - mAP (0) | 2022.04.23 |
| CV - NMS(Non Max Suppression) (0) | 2022.04.23 |
| CV - OD 성능평가 Metric - IoU (Intersection over Union) (0) | 2022.04.23 |
| CV - Selective Search로 Region Proposal 해보기 (0) | 2022.04.22 |