

📌 이 글은 권철민님의 딥러닝 컴퓨터 비전 완벽 가이드 강의를 바탕으로 정리한 내용입니다.
목차
- Object Detection 주요 데이터셋
- Annotation 이란?
- PASCAL VOC Dataset
- Annotation 파일 예시
- MS-COCO Dataset
1. Object Detection 주요 데이터셋

1. PASCAL VOC
- XML Format
- 20개의 오브젝트 카테고리
2. MS COCO
- json Format
- 80개의 오브젝트 카테고리 : 여러가지 이미지
- PASCAL의 평이한 오브젝트 문제 해결
3. Google Open Images
- csv Format
- 600개의 오브젝트 카테고리
많은 Detection과 Segmentation 딥러닝 패키지가 위 Dataset들을 기반으로 Pretrained 되어 배포된다.
2. Annotation이란?
- 이미지의 Detection 정보를 별도의 설명 파일로 제공하는 것
- Object의 Bounding Box 위치나 Object 이름 등을 특정 포맷으로 제공 (XML, json, csv 파일 형식)
3. PASCAL VOC Dataset 구조
- VOC 2012 기준

Annotations
- XML 포맷
- 개별 xml 파일은 한 개의 image에 대한 Annotation 정보를 가짐
- a.xml
- 확장자 xml을 제외한 파일명은 image 파일명(jpg 제외)과 동일하게 매핑
ImageSet
- 어떤 이미지를 train, test, trainval, val에 사용할 것인지에 대한 매핑 정보를 개별 오브젝트 별로 파일을 가짐
JPEGImages
- Detection과 Segmentation에 사용될 원본 이미지
- a.jpg
SegmentationClass
- Semantic Segmentation에 사용될 masking 이미지
SegmentationObject
- Instance Segmentation에 사용될 masking 이미지
4. Annotation 파일 예시
이미지 내의 각 객체(Object) 클래스와 Bounding-box 좌표 정보가 들어 있다.
- 파일 이름
- 개별 오브젝트 정보
- 개별 오브젝트의 Bounding box 정보

5. MS-COCO Dataset 소개
- 가장 대표적인 Dataset
- 80개의 Object Category
- 30만 개의 image들과 150만 개의 object들
- 하나의 image에 평균 5개의 object들로 구성
- Tensorflow Object Detection API 및 많은 오픈 소스 계열의 주요 패키지
- COCO Dataset으로 Pretrained된 모델 제공
5.1.1. MS-COCO Dataset 오브젝트 카테고리
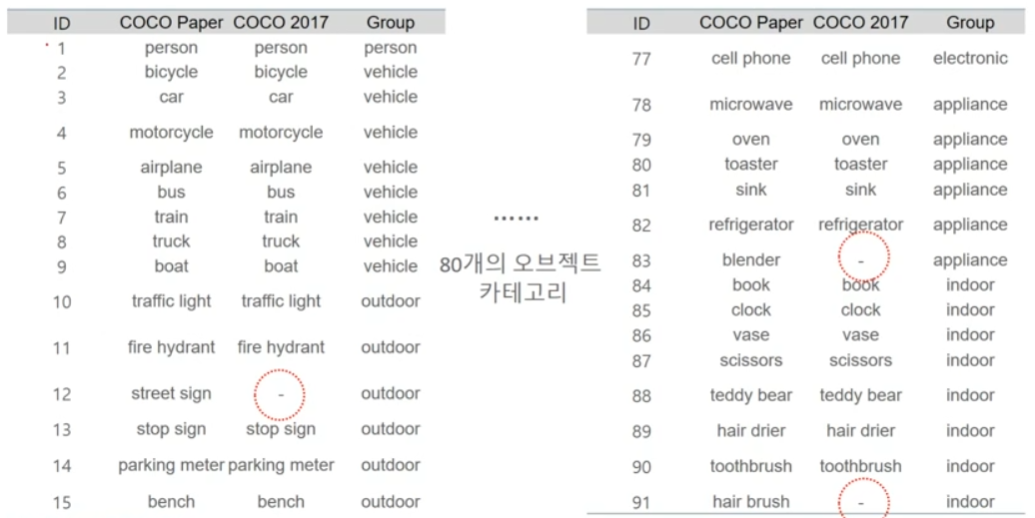
실제 카테고리 수는 수는 80개이다.
근데 ID만 있고 값이 없는 경우가 있다
'🖼 Computer Vision > Object Detection' 카테고리의 다른 글
| CV - Object Detection Architecture (0) | 2022.04.28 |
|---|---|
| CV - OpenCV (0) | 2022.04.23 |
| CV - OD 성능 평가 Metric - mAP (0) | 2022.04.23 |
| CV - NMS(Non Max Suppression) (0) | 2022.04.23 |
| CV - OD 성능평가 Metric - IoU (Intersection over Union) (0) | 2022.04.23 |