
NeRF training pipeline
2022. 9. 14. 17:15
🖼 Computer Vision/3D Reconstruction
NeRF training pipeline NeRF의 학습 과정에 대해서 알아보자. 논문에서 소개하는 method와 철학을 이해하는 것과 실제로 코드를 돌려보는 것과 학습 과정을 아는 것은 정말 차이가 크게 느껴져서 따로 정리하게 되었다. 각각의 Ray 상의 Radiance로부터 weighted sum된 RGB와 density 값을 가지고 Volume Rendering을 거쳐서 얻은 각각의 pixel 값을 구해야 한다. 그리고 그 pixel값과 Ground Truth의 RGB와의 MSE Loss를 Backpropagation 함으로써 Loss를 줄여가는 방향으로 MLP를 학습한다. Create Ray origin, direction input = (height, width, focal, pose), out..

Paper Review - Plenoxels (Radiance Fields without Neural Network)
2022. 8. 30. 16:06
🖼 Computer Vision/Paper Review
Introduction Plenoxels는 NeRF와 다르게 Neural Network를 이용하지 않는, view-dependent한 sparse voxel grid를 기반으로 하는 explicit한 volumetric representation이다. optimization 시간은 bounded scene에서 NeRF가 하루가 걸린다면, Plenoxels은 100배 빠르게 11분, unbounded scene에 대해서는 NeRF가 4일 걸린다면 Plenoxels는 27분 걸렸다. 다만 렌더링은 최적화 되지 않았다고 한다. Plenoxels는 opacity(불투명도)와 Spherical Harmonic coefficients를 저장하는 sparse voxel grid를 이용한다. SH coefficient..

Paper Review - PlenOctrees
2022. 8. 27. 15:02
🖼 Computer Vision/Paper Review
Background Voxel : Volume과 Pixel의 합성어이며 직역하면 부피를 가진 픽셀이다. 즉, 픽셀을 3차원 공간으로 나타낸 것이다. 마인크래프트의 모든 물체가 Voxel로 이루어져 있다고 생각하면 된다. Voxel 자체는 명시적으로 인코딩된 위치를 갖지 않지만, 랜더링 할 때는 다른 Voxel의 위치에 대해서 해당 Voxel의 위치를 나타낸다. 큰 물체나 해상도가 올라갈수록 Voxel로 표현하기엔 연산량이 매우 많아진다는 단점이 있다. Octree : 3D를 만드는데에 사용되는 tree 구조이다. 아래 그림처럼 각 노드는 8개(Octopus)의 자식노드가 있거나 아무것도 없거나 둘 중 하나이다. 각 자식 노드는 RGB 색상 정보를 가질 수 있다. 이런 구조는 트리 크기를 제한하기 때문에 ..

Paper Review - NSVF (Neural Sparse Voxel Fields)
2022. 8. 26. 14:56
🖼 Computer Vision/Paper Review
Introduction 최근 Neural Rendering에 쓰이는 방법들은 NeRF 처럼 implicit field를 이용한 방법을 많이 적용 되고 있는데, Spatial location과 Ray direction을 input으로 넣어주고 어떤 implicit한 function(MLP)를 지나고 나면 그것에 해당하는 Color와 Probability density 값을 구해주는 function을 구하는 방식이 많이 이용되고 있다. 허나 이는 제한된 네트워크 용량이나 Ray와 scene geometry의 정확한 교차점을 찾는 어려움으로 인해 흐릿한 렌더링을 종종 보여준다. 이 논문에서는 Sparse Voxel Field를 사용해서 NeRF보다 더 좋은 성능으로 View synthesis를 할 수 있다고 ..

Paper Review - NeRF (Representing Scenes as Neural Radiance Fields for View Synthesis)
2022. 8. 23. 12:58
🖼 Computer Vision/Paper Review
NeRF 논문 리뷰 포스팅입니다. 3D Vision 공부를 시작한 이후 첫 논문 리뷰 및 정리인 만큼 잘못된 부분이 많을 수 있으니, 잘못된 부분은 언제든 코멘트 해주시기 바랍니다. Introduction NeRF는 어떤 물체를 찍은 여러장의 사진을 입력 받아, 새로운 view에서 바라본 객체의 모습을 알아내는 view synthesis에 대한 새로운 방식에 대한 논문이다. 즉, N개의 시점에서 찍은 2D image를 받으면, N개의 시점으로 보여주는 것이 아니라 continuous하게 임의의 시점에서 2D image를 만들어내는 것이 이 논문의 핵심이다. 예를 들어, 100개의 시점이 있다면 80개를 input으로 쓰고 Rendering을 거친 다음에 나머지 20개 시점을 만들고, 실제 20개의 시점의..
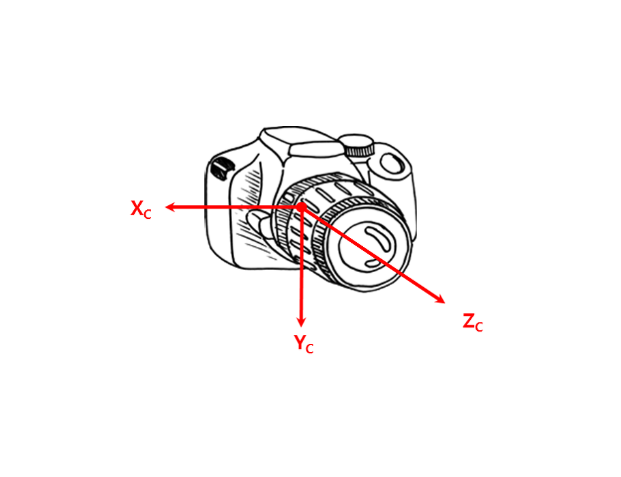
Multi-View Geometry
2022. 8. 13. 13:44
🖼 Computer Vision/3D Reconstruction
Multi-View Geometry의 개념을 정리한 포스팅이다. 다크 프로그래머 님의 포스팅을 요약하였다. 목차 좌표계 (Coordinate System) 동차 좌표계 (Homogeneous Coordinates) 변환 (Transformation) 이미지 투영 (Image Geography) Epipolar Geometry 좌표계 (Coordinate System) MVG에서는 크게 4가지 좌표계가 존재한다. 월드 좌표계 (World Coordinate System) 카메라 좌표계 (Camera Coordinate System) 픽셀 좌표계 (Pixel Image Coordinate System) 정규 좌표계 (Normalized Image Coordinate System) 월드 좌표계 (World C..
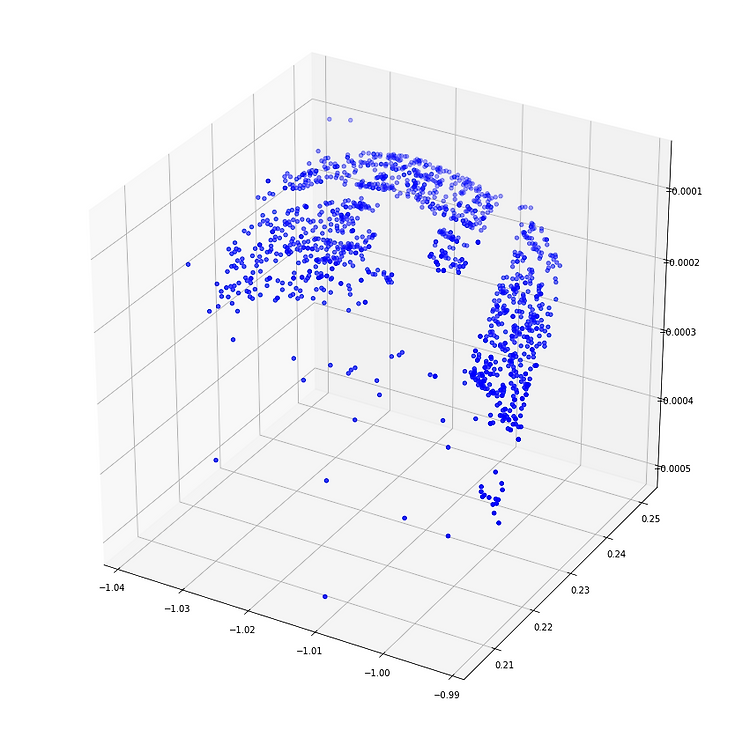
SFM(Structure from Motion) 구현 (with Python)
2022. 8. 12. 18:09
🖼 Computer Vision/3D Reconstruction
Structure from Motion Structure from Motion (SFM) Structure from Motion Structure from Motion은 2차원 영상으로부터 3차원 정보를 추출하여 3D로 재구성하는(structure = 3D structure, motion=Camera pose) 것을 Structure from Motion(SFM)이라고 부릅니다.. woochan-autobiography.tistory.com SfM 개념에 이어, Python 구현에 관한 포스팅입니다. 2 view만 구현하였고, 내용상 잘못된 부분이 있을 수 있으니 참고만 하시고 틀린 부분은 댓글로 지적해주시면 감사하겠습니다. GitHub - SunWooChan/sfm Contribute to SunWoo..
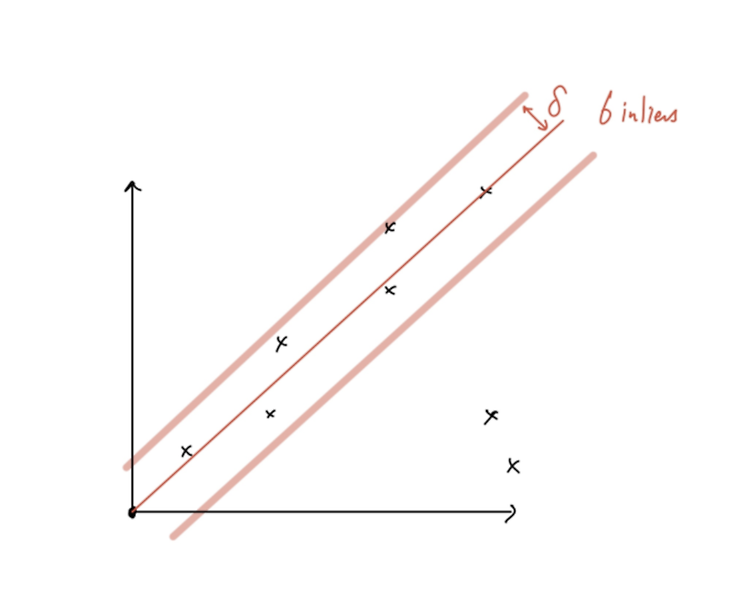
RANSAC (RANdom SAmple Consensus)
2022. 7. 28. 14:27
🖼 Computer Vision/3D Reconstruction
RANSAC은 1981년에 Fischler와 Bolles가 제안한 Model fitting 방법론이다. RANSAC의 이름은 RANdom SAmple Consensus를 줄여서 만들어졌다. 논문이 처음 제안했던 방법도 컴퓨터 비전 분야에서의 사용 방법을 제안하였지만, 크게 주목을 받지 못하다가 2004년 Nister가 제안하는 이미지 프레임간 relative motion을 robust하게 찾아내는 5-point algorithm + RANSAC 프레임워크를 통해 주목을 받게 되었다. 그 후, 많은 양의 데이터로부터 outlier를 거르고 model fitting을 하는 방식으로 RANSAC이 많이 사용되고 있다. Fundamental matrix, Essential matrix, Homography, P..

SIFT (Scale Invariant Feature Transform)
2022. 7. 28. 11:06
🖼 Computer Vision/3D Reconstruction
SIFT란? (Scale Invariant Feature Transform) 크기, 회전, 조도, affine의 변화 및 noise에 불변하는 특징을 추출하는 알고리즘이다. 이는 다음과 같은 절차로 이루어 진다. Find Scale-Space Extrema 우선 크기에 불변하는 특징을 추출하기 위해서, 각 원본 이미지를 1/2 배씩 다운 샘플링 하면서 이미지를 나열한다. 이처럼 같은 이미지에 대해 scale space를 다양하게 하는 이유는 스케일에 따라 세부적인 내용에 집중할수도, 전체적인 구조에 집중할 수도 있기 때문이다. 그렇기 때문에 크기에 불변하는 특징을 모두 추출하기 위해서는 다양한 scale space로 부터 feature를 추출해야 한다. 또한 사진이 멀리서 찍혔다거나, 포커스가 맞지 않거..
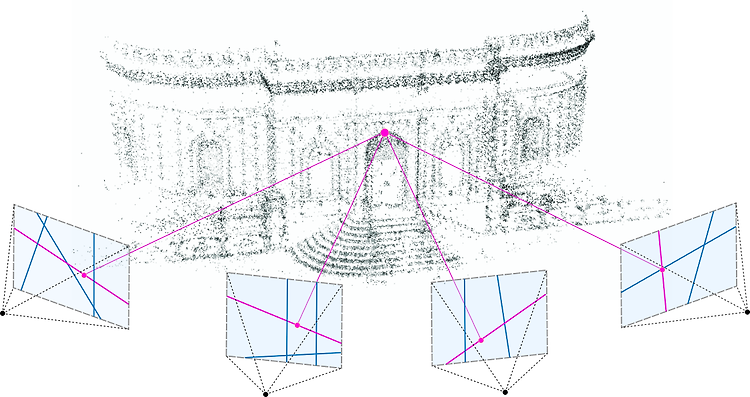
Structure from Motion (SFM)
2022. 7. 26. 18:18
🖼 Computer Vision/3D Reconstruction
Structure from Motion Structure from Motion은 2차원 영상으로부터 3차원 정보를 추출하여 3D로 재구성하는(structure = 3D structure, motion=Camera pose) 것을 Structure from Motion(SFM)이라고 부릅니다. Structure from Motion은 순차적인 이미지 세트로부터 그림에서 보이는 바와 같이 Structure의 3D 재구성을 진행합니다. 3D scene structure를 어떻게 정확하게 찾아 낼 것인지, cameara pose(사진이 어디서 찍혔는지), camera intrinsic, extrinsic parameter를 어떻게 찾아낼 것인지를 알아보는 것입니다. 목차 Camera Calibration (In..
CG - Screen space Object Manipulation
2022. 7. 22. 18:18
☘️ Computer Graphics/Fundamental
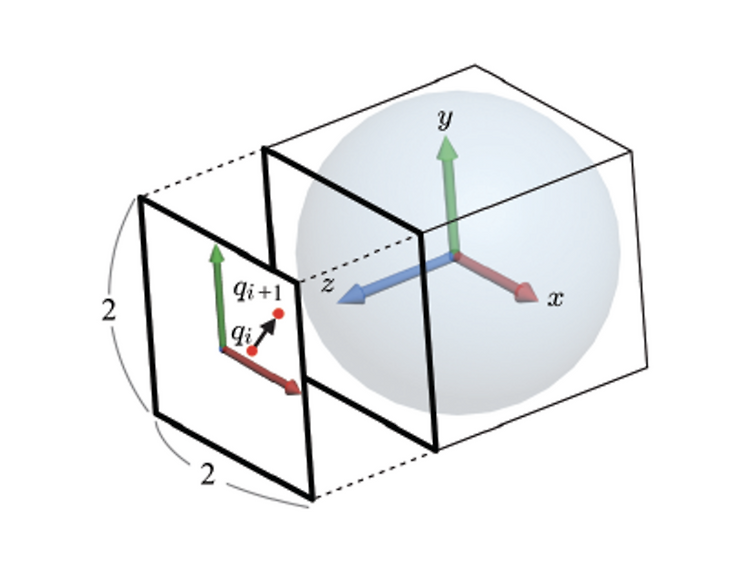
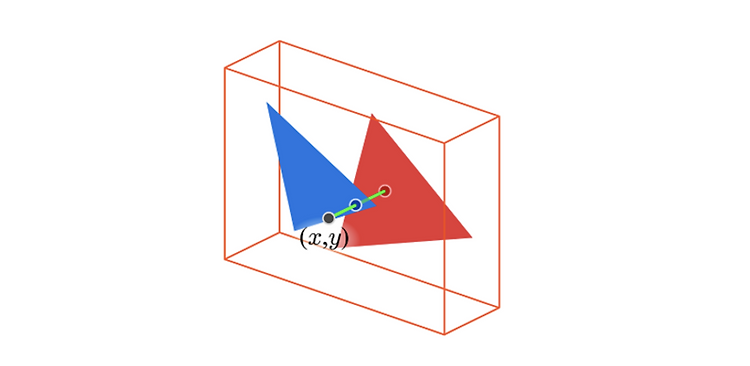
이제 스크린에서 물체를 선택하는 방식과 회전하는 것에 대해 알아보고자 한다. 스크린을 조작하여 물체를 선택할 때 어떤 물체가 선택되는지, 손가락으로 물체를 슬라이드하면 어떻게 돌아가는지 등에 대한 내용이다. Object Picking 2차원 스크린의 게임 상에서 마우스 커서로 유닛이나 물체를 클릭할 때, 스크린에서 z값이 가장 작은(카메라와 가장 가까운) 물체를 선택하게 된다. 이는 매우 간단한 작업처럼 보이지만 여기에는 생각보다 고려해야 할 부분이 많다. 가장 가까운 물체를 선택하는 방식은 레이저(Ray)를 쏴서 가장 먼저 맞는 물체를 선택하는 것과 동일하다. 우리가 Screen space의 x,y 좌표(start point)를 클릭한다면 Screen space에서는 (x, y, 0) 에서 (x, y,..
CG - Euler Transforms and Quaternion
2022. 7. 21. 21:07
☘️ Computer Graphics/Fundamental
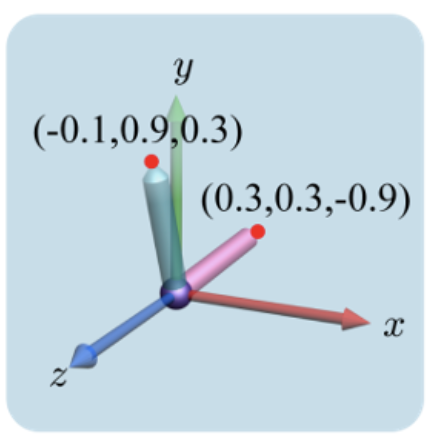
Euler Transforms 물체의 회전에 대해 다룬 적이 있다. 지금까지는 오일러 각(지금까지 사용했던 일반적인 각도)을 이용한 변환을 다루었다. 아래의 그림처럼 x, y, z축을 골고루 이용하면 물체에 임의의 방향을 줄 수 있다. 이렇게 주축 중심 회전을 결합해서 임의의 방향을 제공하는 것을 Euler transform이라고 한다. 위 그림에서는 x축으로 45도, y축으로 60도, z축으로 -45도 회전한 물체를 보았다. 하지만 아래 그림처럼 회전의 순서에 따라 결과값이 다르게 나타난다. Keyframe Animation in 2D 여기까지 오일러 각도를 이용한 회전을 기억하고 있자. 이젠 지금까지와 다른 주제에 대해서 생각해보고자 한다. 지금까지 우리가 다룬 animation은 하나의 결과 장면이..
CG - Output Merger
2022. 7. 20. 22:54
☘️ Computer Graphics/Fundamental
Output Merger 이전 포스팅에서는 Fragment shader에서 진행되는 대표적인 작업인 texturing 과 lighting에 대해서 알아보았다. Fragment shader를 거치고 나면 각각의 fragment는 색상 값을 할당을 받게 된다. Fragment의 output은 RGBAZ fragment 라고도 한다(A : alpha, Z : depth). 그러면 이 색상은 곧 바로 스크린에 보여지는 것이 아니라 Output merger 단계를 거쳐야 한다. Output merger는 fragment를 스크린에 찍을건지 안찍을건지, 어떻게 변형시켜서 보여줄지를 결정한다. fragment 색상은 어찌됐건 위 그림의 viewport(실제로 스크린에 보여질 영역) 안에서 계산이 된다. Color &..
CG - Lighting
2022. 7. 19. 16:08
☘️ Computer Graphics/Fundamental
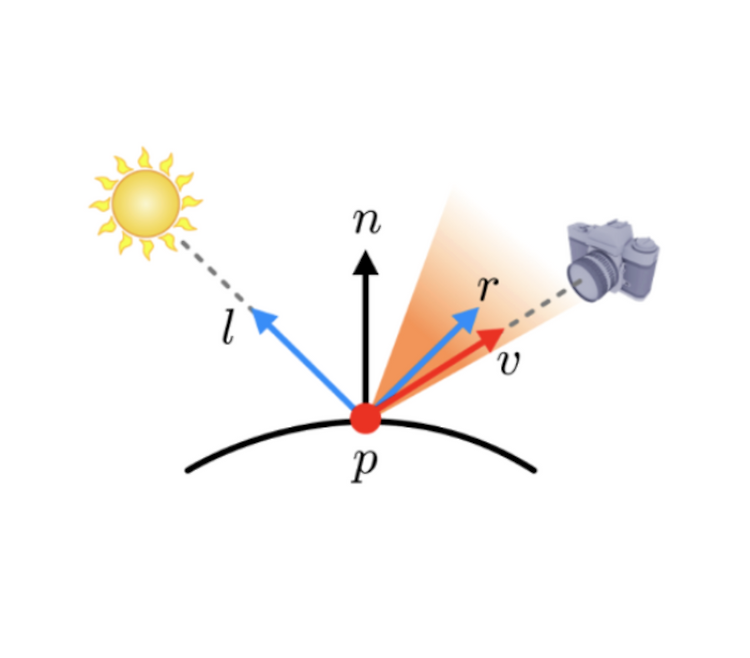
이전 포스팅에서 fragment shader 의 역할 중 첫 번째 역할인 texturing에 대해 배웠다. 이번 포스팅에서는 lighting에 대해 배워보자. 그중에서도 가장 기본이 되는 Lighting 모델인 Phong Lighting에 대해 배워보자. Phong Lighting Model Lighting은 물체와 빛 사이의 상호작용을 말한다. 사실적인 그래픽을 위해서는 lighting이 매우 중요하다. 그중에서도 유타대학 출신의 베트남 사람인 Phong 이 제안한 모델인 phong lighting model은 4개의 요소로 이루어져 있다. Diffuse, Specular, Ambient, Emissive 이다. 네가지 요소의 설명에 앞서 광원에 대해 생각해보자. 광원은 여러가지 종류가 있다. 가장 간..
CG - Image Texturing
2022. 7. 18. 11:04
☘️ Computer Graphics/Fundamental
이제 우리는 vertex shader로부터 rasterizer 까지 살펴 보았다. 하나의 삼각형 안에 들어가는 모든 fragment를 계산했다는 것이고, 그 fragment에는 선형보간을 통해 얻어진 normal과 texture coordinate가 저장이 되어있을 것이다. 그 다음 단계는 fragment shader이고 각 fragment의 색상을 결정한다. fragment shader는 texturing과 lighting을 진행한다. 이번 포스팅에서는 texturing을 알아보도록 하자. Texture Coordinates texture는 모델링한 polygon mesh에 입히는 옷이다. 다음과 같은 원통에 texturing을 진행한다고 해보자. 이미지와 mesh가 주어졌을 때 mesh 표면에다가 t..
CG - Rasterizer
2022. 7. 16. 20:55
☘️ Computer Graphics/Fundamental
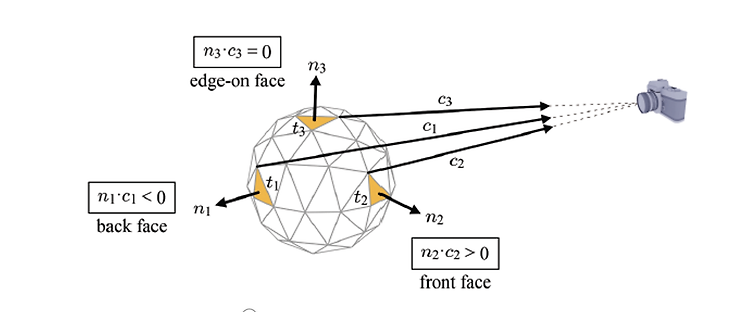
지금까지 Vertex shader와 Vertex shader가 하는 역할인 Object space부터 World space와 Camera space를 거쳐 Clip space까지의 변환을 배웠다. Vertex shader는 Clip space의 점들의 좌표을 Rasterizer에 넘겨준다. 그러면 Clip space의 점들을 다시 조립(assemble)한다. 그래서 하나의 삼각형이 스크린에 나타나게 된다. 그러면 삼각형의 픽셀들을 점유하면서 색깔(정보)들을 보여주며, 픽셀 위치마다 fragment를 정의하게 된다. Rasterizer는 여기서 fragment를 만드는 것이 주요 임무이다. Rasterizer는 Clipping, Perspective division, Back-face culling, Vi..