


Introduction
최근 Neural Rendering에 쓰이는 방법들은 NeRF 처럼 implicit field를 이용한 방법을 많이 적용 되고 있는데, Spatial location과 Ray direction을 input으로 넣어주고 어떤 implicit한 function(MLP)를 지나고 나면 그것에 해당하는 Color와 Probability density 값을 구해주는 function을 구하는 방식이 많이 이용되고 있다. 허나 이는 제한된 네트워크 용량이나 Ray와 scene geometry의 정확한 교차점을 찾는 어려움으로 인해 흐릿한 렌더링을 종종 보여준다. 이 논문에서는 Sparse Voxel Field를 사용해서 NeRF보다 더 좋은 성능으로 View synthesis를 할 수 있다고 한다. 랜더링 속도도 40배 정도 빠르다고 한다. NeRF는 비어있는 공간에 대해서도 샘플링하고 training해서 시간이 오래 걸리는데, NSVF는 비어있는 공간에 대해서는 샘플링을 피하고 물체가 있는 공간만 샘플링(objectiveness) 한다.
Background
최근에는 아래와 같이 implicit field를 적용하는 방식이 대부분이다.
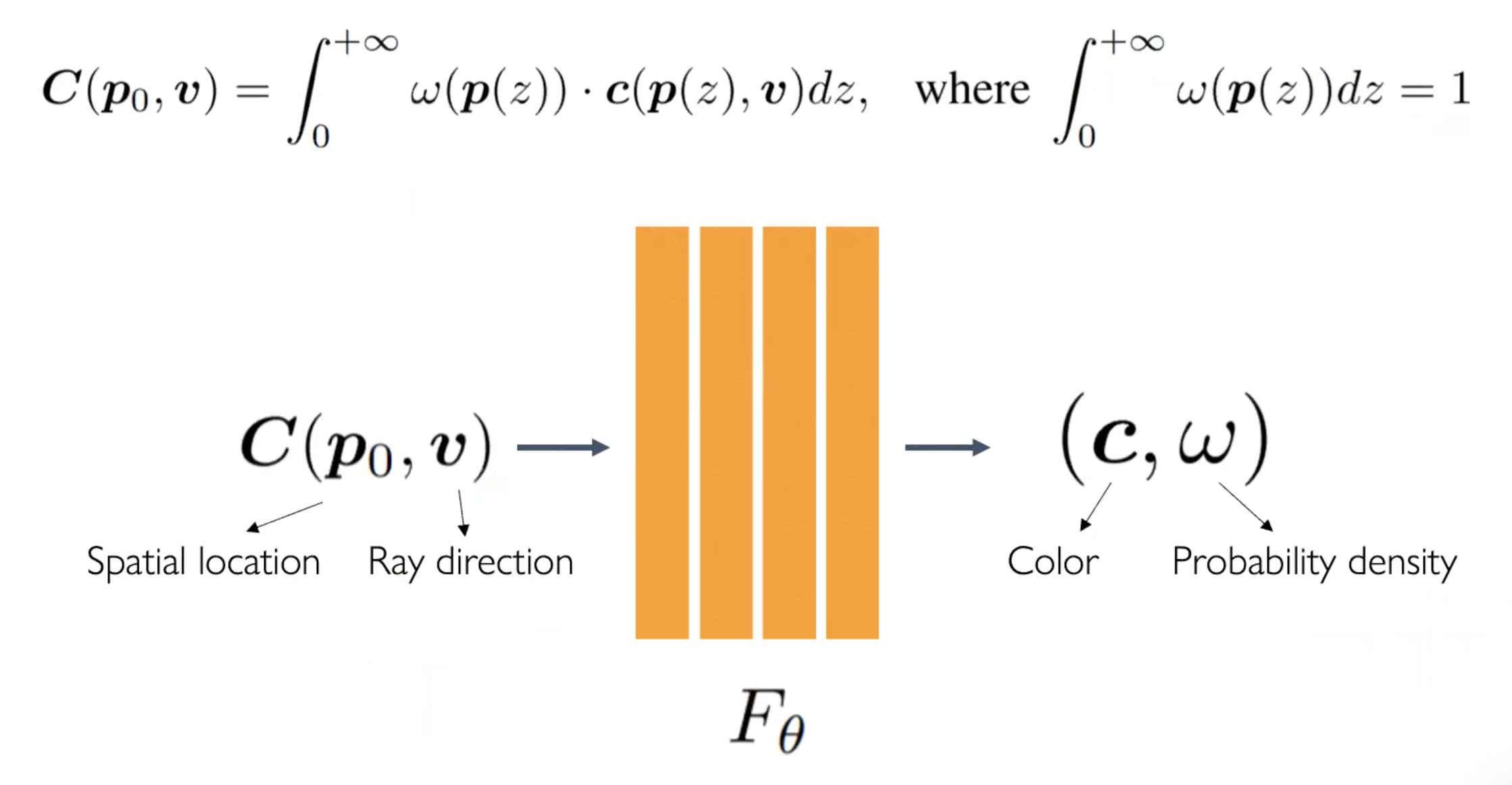
NeRF 방식은 전체에 대해 샘플링을 진행하고, 샘플링 된 것들을 합쳐서 optical ray marching으로 확인한다. 이 방식은 Volume Rendering 자체도 Time cosuming 하다. 좋은 퀄리티를 얻을 수 있지만 시간이 너무 오래 걸린다는 단점이 있다.

위의 그림처럼 비어있는 공간에 대해서는 고려할 필요가 없는데, NeRF는 인식하지 못한다. 즉 모든 부분에 대해 샘플링이 진행이 된다는 것이다. 실제로 물체가 있는 공간만 샘플링을 하자는 것이 NVRF에서 하고자 하는 것이다. 비어있는 space에 대해서는 샘플링을 피하자!
그럼 비어있는 공간은 어떻게 추적해? → Objectiveness
Neural Sparse Voxel Field
그래서 제안한 것이 바로 Neural Sparse Voxel Field이다.
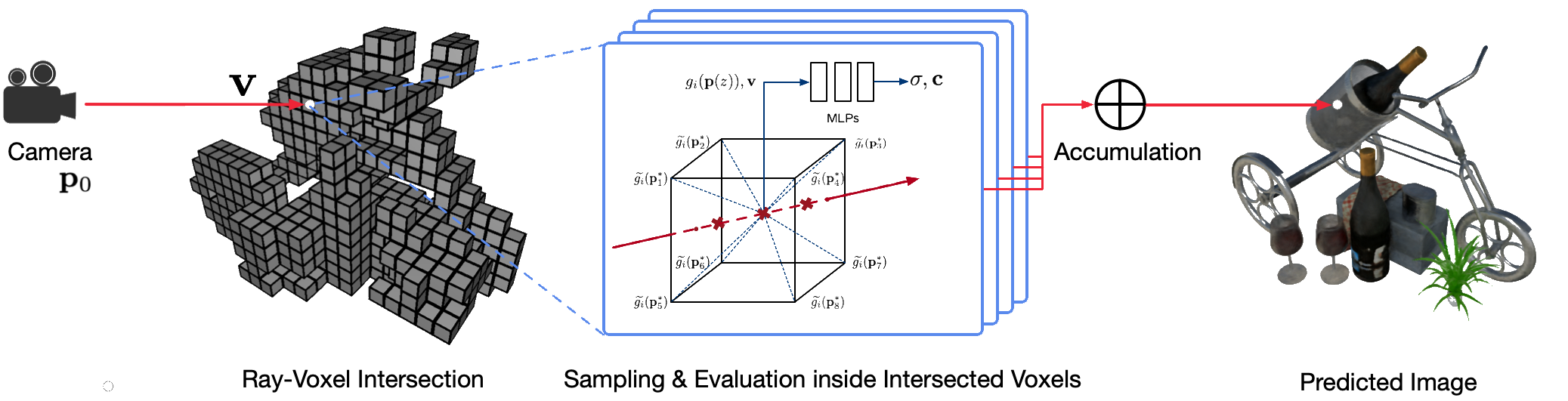
NSVF의 Pipeline은, 먼저 Voxel grid를 만들고, Ray와 겹치는 부분의 Voxel 정보를 aggregation하고, 이 aggregation 정보들을 MLP의 input으로 넣어서 occupancy와 color를 만든 다음, 그것들을 합쳐서 이미지를 생성하는 것이다. 그리고 점점 Voxel을 Pruning 하면서 Progressive Training을 진행한다.
NSVF Pipeline
- Voxel grid 생성 (Neural sparse voxel field)
- Volume Rendering
- Ray-Voxel Intersection : 각 Ray에 대해 교차하는 Voxel을 구함
- Ray와 겹치는 Voxel 정보 aggregation (꼭지점 임베딩, trilinear interpolation 후 p 값, p를 positional encoding)
- Sampling(Ray marching inside voxels) : Voxel 안의 겹치는 애들에 대해서만 샘플링 함 (Rejection sampling으로 안겹치는 Voxel을 쳐냄)
- Early termination : Transparency에 대해 안보이는 뒷 부분에 대해서는 학습하지 않는 것
- Loss : NeRF와 비슷하게 예측 color와 GT color로 구함
- 다른 것은 Beta distribution 을 이용(Surface에 집중하기 위해 Early termination을 하기 위한 것)
- 반투명하거나 빛이 반사되는 부분은 학습 잘 안됨
- aggregation 정보를 MLP의 input으로 넣어 occupancy와 color를 만든다.
- Voxel prunning
Voxel-bounded implicit fields
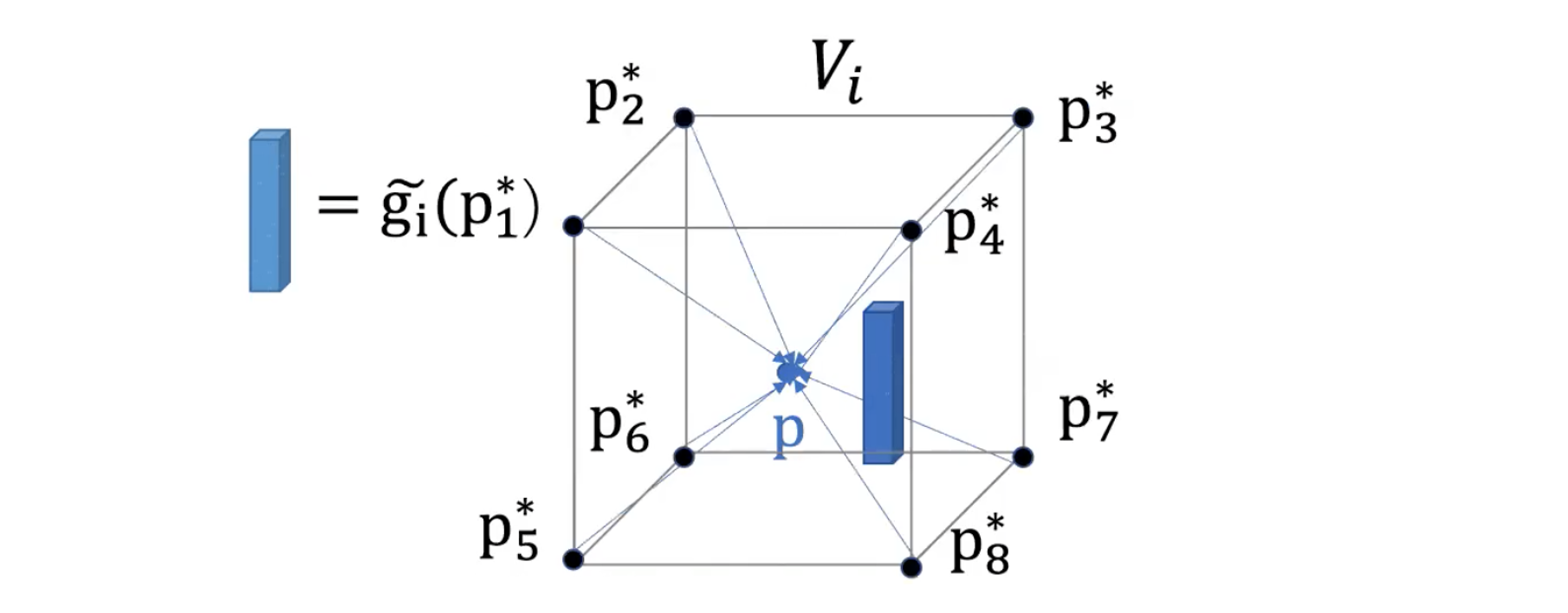
Voxel의 각 꼭지점에 있는 점들인 p1 ~ p8에 대해서 g라는 임베딩을 거친다. 그러면 각 꼭지점들에 대해 임베딩이 쌓이고, 그것을 trilinear interpolation해서 중간의 포인트를 샘플링 하고, 그 포인트의 값의 임베딩을 구해주고, 그 임베딩을 Positional encoding을 해서 point로 넣어줄 input을 결정한다.

아래 그림처럼 Voxel이 있다면 Voxel의 각 꼭지점들의 임베딩을 만들어주고(실제로는 32 dimension), 안쪽의 p 로 샘플링으로 잡았을 때, trilinear 방식으로 p값을 정해주고, p를 Positional encoding을 거쳐서 함수의 input으로 넣어준다.
Volume Rendering
NeRF는 Ray를 쏘고 지나가면서 해당되는 샘플링 점들에 대해서 합치는 방식이었는데, NSVF는 Voxel을 가지고 정보를 aggregation해서 사용하다 보니, 지나가는 Voxel에 대해서 먼저 확인하고, 그 Voxel들의 aggregation 정보를 Ray marching 하겠다는 것이다.
즉, 2 Stage 이다. Ray-Voxel Intersection → Sampling and Ray marching inside Voxel

Ray-Voxel Intersection
Ray-Voxel Intersaction은 각 Ray 에 대해 AABB(Axis Aligned Bounding Box intersection)의 방법을 사용한다. AABB는 Octree 구조에 효과적이고 real time이 가능하다.

즉 Ray에 대해 Octree 마다 계속 Voxel을 쪼개면서 구하는 것이다.
Ray marching inside Voxels
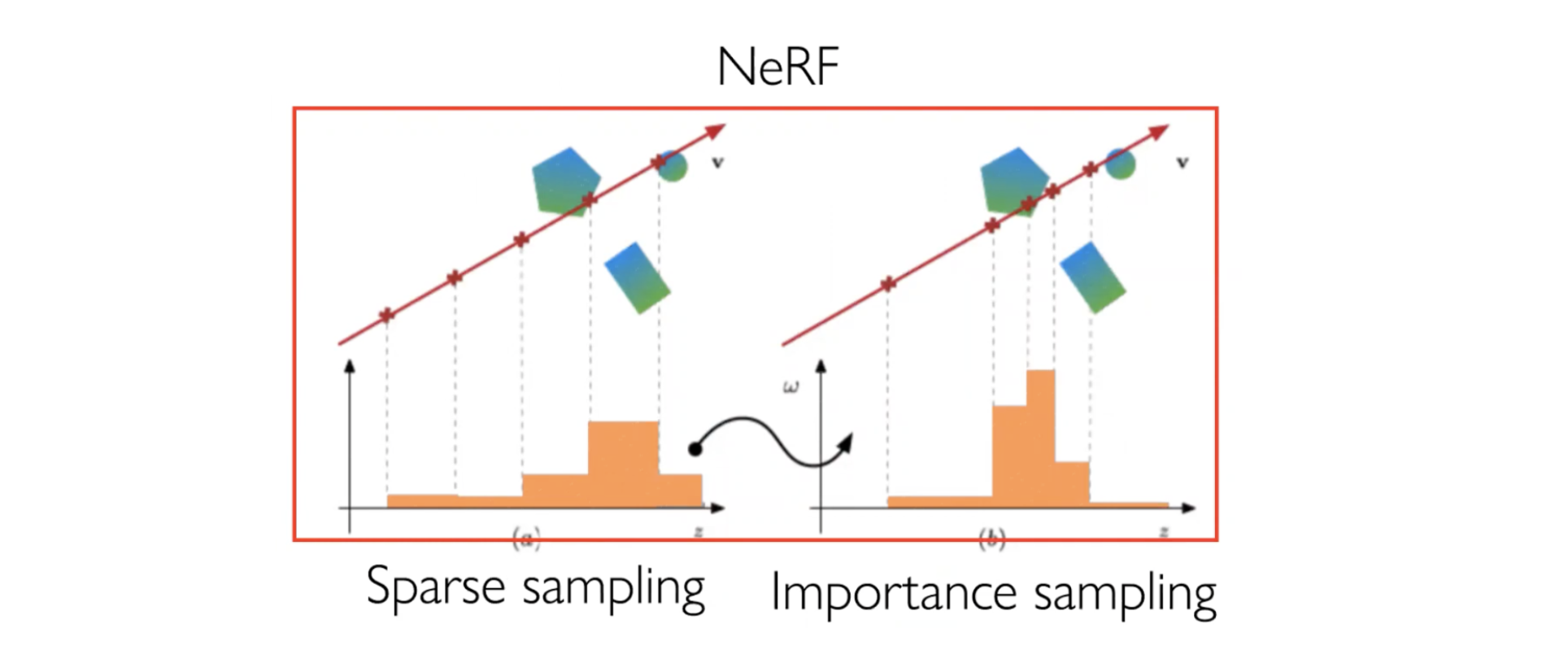
기존의 NeRF는 Stratified sampling approach 로 uniform하게 뽑고 그 결과를 가지고 probability에 초점을 맞춰서 importance sampling을 다시 진행하는 두가지 과정을 거친다.

NSVF는 Voxel 안에 있는 애들에 대해서 겹치는 곳만 샘플링을 진행하겠다는 것이다. 위의 그림처럼 Ray와 Voxel의 교점을 모두 샘플링을 한다. 그리고 나서 겹치는 Voxel 정보에 대해서 Rejection sampling으로 샘플링을 추가적으로 해준다. 여기서 Rejection sampling은 샘플링된 Voxel에서 물체와 겹치지 않는 Voxel이 들어있다면 쳐내는 방법이다. 그 다음 NeRF에서 진행했던 방식과 비슷하게 각 점의 중심점과 각 점들의 gap을 통해 weighted sum하면서 렌더링을 진행한다.
아래는 Neural Rendering의 방식을 나타낸다.

A는 투과율이다.
Early Termination

Early Termination은 어느정도 학습이 진행이 되고 나면, Transparency에 대하여 뒤의 정보는 안보이겠구나 라는 부분에 대해서는 학습을 하지 않는 것이다. 위의 그래프는 빠르게 Termination이 진행된 것을 나타낸 것이고 아래 부분은 조금 뒤에 Termination이 진행된 것을 나타낸다. Early Termination을 하면 시간이 많이 줄어든다.
Training
Loss
NeRF와 비슷하게 예측 Color와 GT의 Color의 Loss를 구한다. NeRF와 다른 것은 Beta-distribution regularizer를 도입한다는 것이다. 투과도인 A가 0 또는 1 값을 갖게 하여 Surface 정보가 빨리 학습되도록(빠른 Termination) 하기 위한 distribution을 넣어준다. 즉, Surface를 집중적으로 하기 위한 도입이다. 그러나 이러한 부분에 대해서 반투명하거나 빛의 반사가 되는 부분에 대해서 학습이 잘 안된다고 한다.

Voxel Initialization
처음에 Volume에 대해서 10개로 나눈 것으로 initialization 한다. 10x10x10 개의 Voxel로 시작한다.
Self-Pruning
각각의 점에 대해서 occupancy를 구했을 때, 모든 값에 대해서 일정 threshold 보다 낮으면 해당 Voxel에 대해서 Pruning 한다. 하나라도 차있다고 계산되면 Pruning 하지 않는다. 아래 그림과 같이 계속 비어있는 부분은 pruning 하고, 계속 세밀한 Voxel에 대해서 같은 과정을 반복해서 진행한다.


Progressive Training
Result

↑ PSNR(Peak Signal to Noise Ratio) : Resolution에 대한 손실 정보
↑ SSIM(Structure similarity) : luminance, contrast, structural
↓ LPIPS (Learned perceptual image patch similarity)

SRN, NV, NeRF와 비교했을 때 전체적으로 수치가 높은 것을 확인할 수 있다.
Rendering speed를 좀 더 강조하는 것 같다.

성능은 NeRF와 비슷하거나 높은데 속도는 빨랐다.
Ref.
NSVF github : https://github.com/facebookresearch/NSVF
NSVF arxiv : https://arxiv.org/pdf/2007.11571.pdf
https://lingjie0206.github.io/papers/NSVF/
.
'🖼 Computer Vision > Paper Review' 카테고리의 다른 글
| Paper Review - Plenoxels (Radiance Fields without Neural Network) (1) | 2022.08.30 |
|---|---|
| Paper Review - PlenOctrees (0) | 2022.08.27 |
| Paper Review - NeRF (Representing Scenes as Neural Radiance Fields for View Synthesis) (4) | 2022.08.23 |
| 논문 읽기와 ML/DL 커리어 경력에 대한 조언 by 앤드류 응 (0) | 2022.06.16 |