
소수(에라토스테네스 체)
2021. 9. 10. 20:51
⏰ 코딩테스트/구현
자연수 N이 입력되면 1부터 N까지의 소수의 개수를 출력하는 프로그램을 작성하세요. 만약 20이 입력되면 1부터 20까지의 소수는 2, 3, 5, 7, 11, 13, 17, 19로 총 8개입니다. 제한시간은 1초입니다. ▣ 입력설명 첫 줄에 자연수의 개수 N(2
자릿수의 합
2021. 9. 8. 10:59
⏰ 코딩테스트/구현
자릿수의 합 N개의 자연수가 입력되면 각 자연수의 자릿수의 합을 구하고, 그 합이 최대인 자연수를 출력하는 프로그램을 작성하세요. 입력설명 첫 줄에 자연수의 개수 N(3
정다면체
2021. 9. 7. 17:02
⏰ 코딩테스트/구현
정다면체 두 개의 정 N면체와 정 M면체의 두 개의 주사위를 던져서 나올 수 있는 눈의 합 중 가장 확률이 높은 숫자를 출력하는 프로그램을 작성하세요. 정답이 여러 개일 경우 오름차순으로 출력합니다. 입력설명 첫 번째 줄에는 자연수 N과 M이 주어집니다. N과 M은 4, 6, 8, 12, 20 중의 하나입니다. 출력설명 첫 번째 줄에 답을 출력합니다. 입력예제 1 4 6 출력예제 1 5 6 7 코드 n, m = map(int,input().split()) alist = [int(n/2), int(n/2+1)] blist = [int(m/2), int(m/2+1)] ans1 = [] for i in range(len(alist)): for j in range(len(blist)): ans1.append(a..
대표값
2021. 9. 7. 16:23
⏰ 코딩테스트/구현
대표값 N명의 학생의 수학성적이 주어집니다. N명의 학생들의 평균(소수 첫째자리 반올림)을 구하고, N명의 학생 중 평균에 가장 가까운 학생은 몇 번째 학생인지 출력하는 프로그램을 작성하세요. 답이 2개일 경우 성적이 높은 학생의 번호를 출력하세요. 만약 답이 되는 점수가 여러 개일 경우 번호가 빠른 학생의 번호를 답으로 한다. 입력설명 첫줄에 자연수 N(5

ML - 교차 검증
2021. 8. 26. 17:06
💡 AI/ML
교차 검증 1. k-fold from sklearn.model_selection import KFold iris = load_iris() features = iris.data label = iris.target dt_clf = DecisionTreeClassifier(random_state=156) # 5개의 폴드 세트로 분리하는 KFold 객체와 폴드 세트별 정확도를 담을 리스트 객체 생성. kfold = KFold(n_splits=5) cv_accuracy = [] n_iter = 0 # KFold객체의 split( ) 호출하면 폴드 별 학습용, 검증용 테스트의 로우 인덱스를 array로 반환 for train_index, test_index in kfold.split(features): # kfol..
ML - 예측 프로세스
2021. 8. 25. 19:58
💡 AI/ML
예측 프로세스 1. 데이터 셋 분리 (train data, test data로 분리) ↓ 2. 모델 학습 (train data 기반 ML 알고리즘을 적용해 모델을 학습) ↓ 3. 예측 수행 (학습된 ML 모델로 test data 예측) ↓ 4. 평가 (예측된 test data의 결과와 실제 test data의 결과 비교 후 성능 평가) Skitlearn Estimator fit() : 학습 predict() : 예측 Classifier (분류) DecisionTreeClassifier RandomForestClassifier GradientBoostingClassifier GaussianNB SVC Regressor (회귀) LinearRegression Ridge Lasso RandomForestReg..

ML - pandas 기본
2021. 8. 24. 17:07
💡 AI/ML
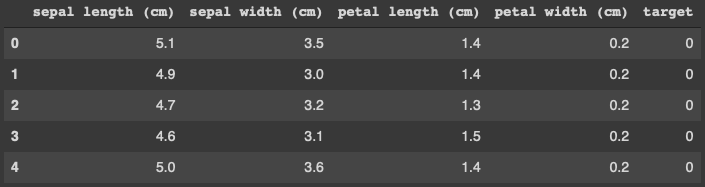
1. 판다스(pandas) 파이썬에서 데이터 처리를 위해 존재하는 가장 인기있는 라이브러리이다. 대부분의 데이터 셋은 2차원이다. 1.1. 판다스의 구성요소 DataFrame : Column x Row 로 구성된 2차원 데이터 셋 Series : 1개의 Column 만으로 구성된 1차원 데이터 셋 Index 1.2. 기본 API read_csv() head() shape info() describe() Value_counts() Sort_values() 1.3. DataFrame의 생성 딕셔너리 형태로 만든다. key 가 컬럼명으로 들어가고, 나머지 value가 나머지 값들로 들어가게 된다. dic1 = {'Name': ['Chulmin', 'Eunkyung','Jinwoong','Soobeom'], '..
ML - 머신러닝과 numpy 기본
2021. 8. 23. 21:26
💡 AI/ML
머신러닝의 개념 머신러닝은 세가지로 나뉜다. 지도학습(Supervised Learning) : 명확한 결정값이 주어진 데이터를 학습 분류 회귀 비지도학습(Un-supervised Learning) : 결정값이 주어지지 않은 데이터를 학습 군집화(클러스터링) 차원 축소 강화학습(Reinforcement Learning) 머신러닝 알고리즘의 유형 기호주의 : 결정트리 연결주의 : 신경망/딥러닝 (심층신경망을 기초로한) 유전 알고리즘 베이지안 통계 (기존의 가설을 새로운 데이터를 받으며 갱신) 유추주의 : KNN, SVM (유사한 것들의 추정) 머신 러닝의 단점 데이터에 의존적이다. 편향된 데이터만 넣으면 편향된 결과만 나온다. 최적의 결과를 도출하기 위한 머신러닝 모델은 실제 환경 데이터에 맞지 않을 수 있..

웹 화면 구현하기
2021. 8. 23. 17:47
📱 Full-Stack
index.html Banner Image Sales Product index.css #header { height: 64px; background-color: black; } #body { height: 100%; background-color: blue; width: 1024px; margin: 0 auto; } #footer { height: 200px; background-color: red; } #Banner { height: 300px; background-color: yellow; } 1차 완성 index.html Sales Product html.css body { margin: 0; /*디폴트 마진설정을 0으로*/ padding: 0; } #header { height: 64px; dis..
백준 알고리즘 - 1074 - Z
2021. 8. 22. 21:38
⏰ 코딩테스트/백준 알고리즘
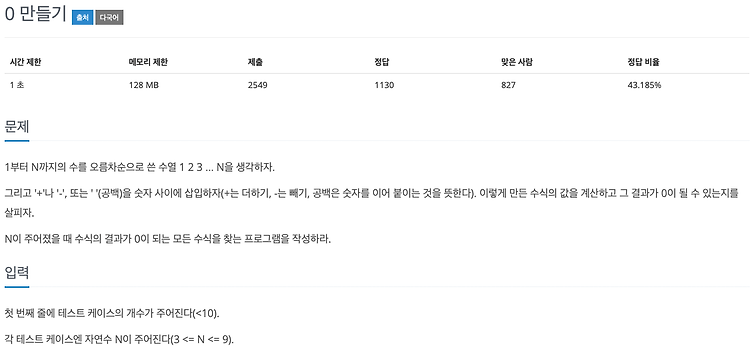
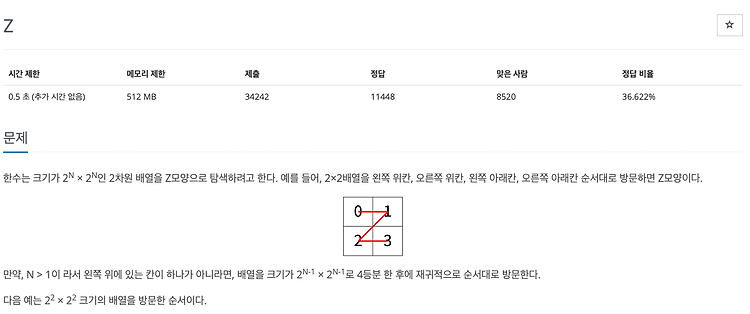
이 문제는 주어지는 입력값이 매우 크고, 제한 시간이 짧기 때문에 리스트를 만들어서 숫자를 나열한 후에 (r, c)에 있는 숫자를 출력하는 방식으로는 통과할 수 없다. 따라서 단순 구현식으로 이중리스트를 만드는 것이 아니라, 규칙을 찾아서 재귀함수를 통해 숫자를 출력해주는 것이 옳은 방법이다. def solve(n, x, y): global result if n == 2: if x == r and y == c: print(result) return # 현재의 함수에서 빠져 나와라 result += 1 if x == r and y + n/2 == c: print(result) return result += 1 if x + n/2 == r and y == c: print(result) return resul..

백준 알고리즘 - 2747 - 피보나치 수
2021. 8. 22. 17:27
⏰ 코딩테스트/백준 알고리즘
풀이 def fibo(n): if n == 0: return 0 elif n== 1: return 1 else: return fibo(n-1) + fibo(n-2) n = int(input()) fibo(n) 단순 재귀 함수로 구현하면 틀린다. 재귀의 한계 때문이다. 필요 없는 계산은 하면 안된다. 호출이 되는 횟수는 깊이 들어갈수록 2배씩 늘어난다. 즉, 시간복잡도는 O(2^n) 이 된다. def fibo(n): cache = [0] * (n+1) cache[0] = 0 cache[1] = 1 for i in range(2, n+1): cache[i] = cache[i-1]+cache[i-2] return cache[n] n = int(input()) fibo(n) DP로 풀어도 시간 초과가 나온다. ..
백준 알고리즘 - 10989 - 수 정렬하기 3
2021. 8. 21. 17:14
⏰ 코딩테스트/백준 알고리즘
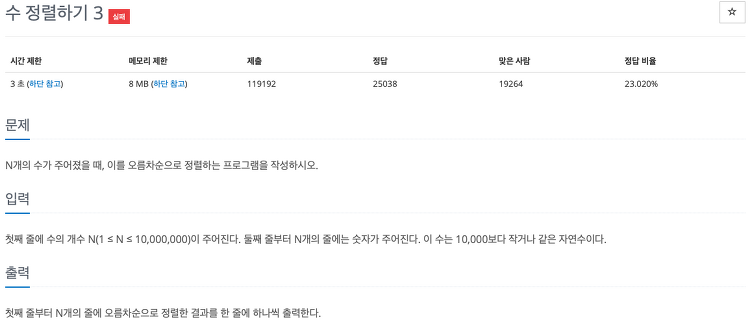
문제풀이 횟수 : 문제 풀이 핵심 아이디어 파이썬은 대략 1초에 약 2천만개까지 연산을 수행할 수 있다. 따라서 파이썬의 기본 정렬 라이브러리를 사용하면 이 문제를 풀 수 없다. 시간 복잡도가 O(N)의 정렬 알고리즘을 이용해야 하고, 데이터의 개수가 최대 1천만개 이므로 기본 정렬 라이브러리를 사용하면 안된다. 또한 수의 범위가 1~10000 이고, 범위가 작으므로 계수정렬(Counting sort)을 이용할 수 있다. 유의사항 데이터의 개수가 많을 때 파이썬에서는 sys.stdin.readline() 으로 읽어야 한다. input()함수에 비해서 빠르기 때문이다. 코드 import sys n = int(sys.stdin.readline()) arr = [0]*10001 for i in range(n)..

백준 알고리즘 - 11650 - 좌표 정렬하기
2021. 8. 21. 16:26
⏰ 코딩테스트/백준 알고리즘
문제 풀이 핵심 아이디어 (x좌표, y좌표)를 입력 받은 뒤, x좌표 y좌표 순서대로 차례대로 오름차순 정렬한다. 파이썬의 기본 정렬 라이브러리는 기본적으로 튜플의 인덱스 순서대로 오름차순 정렬한다. 따라서 단순히 기본 정렬 라이브러리를 이용하면 (key 속성 설정 없이) 저절로 정렬된다. 코드 n = int(input()) arr = [] for _ in range(n): x, y = map(int, input().split()) arr.append((x, y)) arr = sorted(arr) for i in arr: print(i[0], i[1])
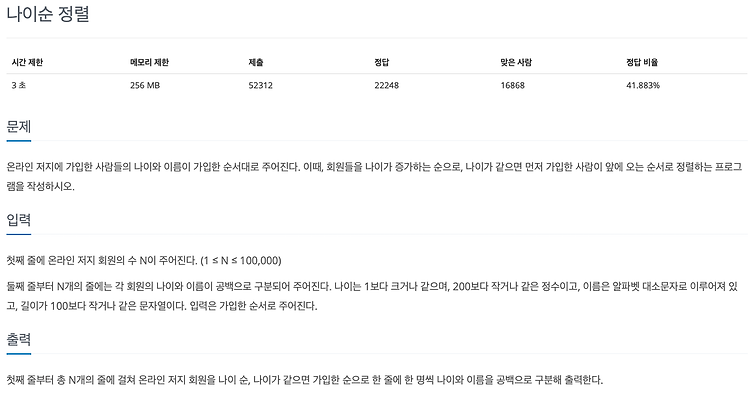
백준 알고리즘 - 10814 - 나이순 정렬
2021. 8. 21. 15:56
⏰ 코딩테스트/백준 알고리즘
튜플의 기본 of 기본 정렬의 기본 of 기본 코드 n = int(input()) arr = [] for _ in range(n): data = input().split() arr.append((int(data[0]), data[1])) # 튜플 형태 arr = sorted(arr, key=lambda x:x[0]) # 튜플의 (첫번째, 두번째)중 첫번째를 기준으로 정렬 for i in arr: print(i[0], i[1]) lambda 인자 : 표현식 sorted() 함수 sorted(정렬할 데이터) sorted(정렬할 데이터, reverse 파라미터) sorted(정렬할 데이터, key 파라미터) sorted(정렬할 데이터, key 파라미터, reverse 파라미터) sorted 함수는 파이썬 내장..
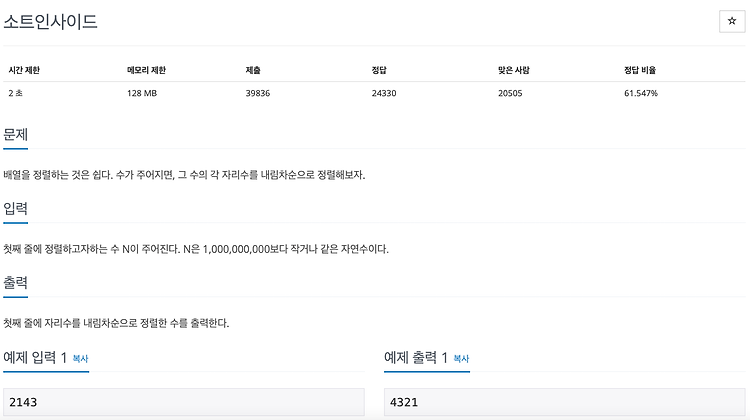
백준 알고리즘 - 1427 - 소트인사이드
2021. 8. 20. 18:32
⏰ 코딩테스트/백준 알고리즘
접근법 코드 N = input() for i in range(9, -1, -1): for j in N: if int(j) == i: print(i, end='') 다른 풀이 N = input() N = [int(n) for n in N] ans = sorted(N, reverse=True) for i in ans: print(i, end="")