
📌 이 글은 권철민님의 딥러닝 컴퓨터 비전 완벽 가이드 강의를 바탕으로 정리한 내용입니다.
목차
- RCNN 모델의 단점
- SPP layer
- SPPNet 구조
- SPP(Spatial Pyramid Pooling)
- SPM(Spatial Pyramid Matching)
요약
1. Selective Search로 인풋 이미지에 대해 많은 Region Proposal들을 추출
2. Region Proposal 들의 크기가 서로 다름
3. 고정된 사이즈의 벡터로 결합(Spatial Pyramid Pooling)
4. SPP = Bag of Visual Words + 분면 테크닉을 통한 Max Pooling 과정
RCNN 모델의 단점
- 각 Region Proposal 마다 Object Detection을 별개로 수행해주어야 해서 매우 오랜 학습시간이 소요된다.
- 여러개의 Region Proposal들을 Pretrained된 Feature Extractor가 요구하는 고정된 사이즈로 통일시켜주어야 해서 Region Proposal을 자르거나 찌그러뜨려 이미지를 손상(?)시키게 된다.
원본이미지 추출(Selective search) 에서 추출한 것만 Feature extractor에 넣어서 피쳐맵을 추출하자!
근데 이게 안됐다.
Dense layer에 가야하는데 피쳐맵 사이즈를 고정 해줘야 된다. 근데 그게 안되는 것이다.
Flattened fc에 넣기 위한 고정 사이즈가 필요하다.
이걸 할 수 있는 별도의 레이어를 만들자!
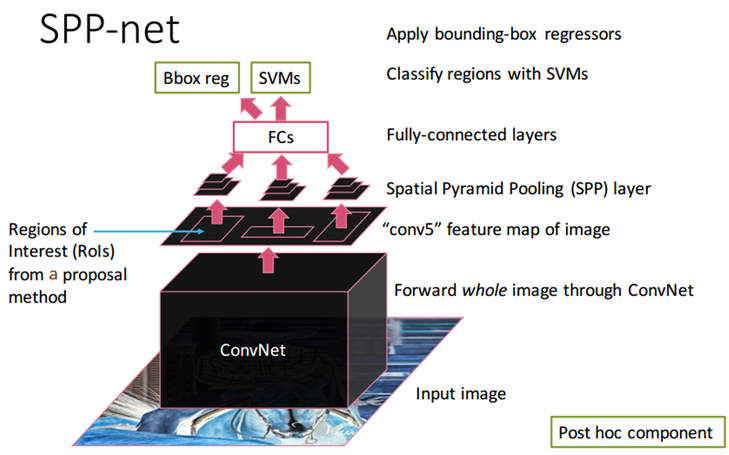
SPP layer
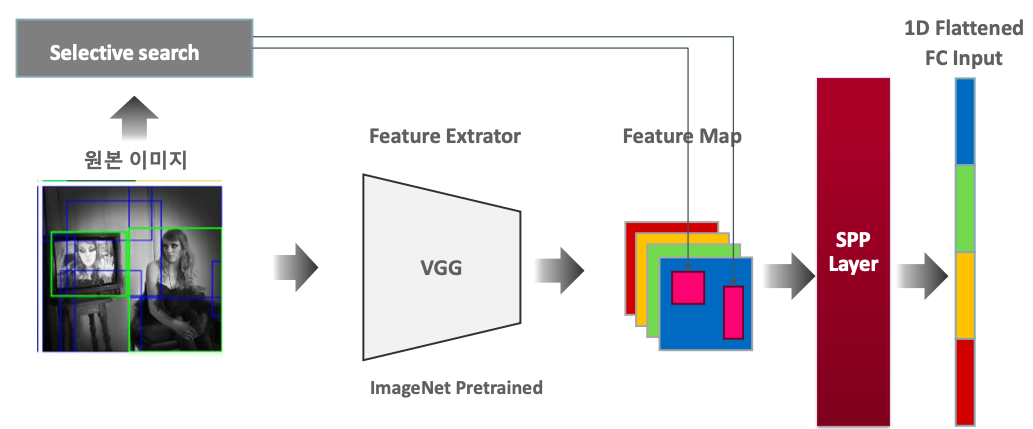
"인풋 이미지 사이즈를 고정 시키지 말자"에서 출발해서, Feature Extractor와 Flattend Fully Connected layer 중간에서 유연하게 가져갈 수 있는 별도의 레이어를 넣자!
그것은 바로 SPP layer
이미지를 crop하면 이미지가 소실되는 부분이 많다. 이걸 소실시키지 말자!
이런 RCNN 모델의 단점을 극복하기 위해 나온 모델이 바로 SPPNet
SPPNet 구조


SPP Net은 SPP라는 Pooling Layer가 여러개 겹쳐있는 네트워크를 의미한다.
Dense layer 뒷 부분은 기본적인 Object Detection Network들의 객체 클래스 분류를 위한 Softmax Layer와 SVM Classifier, 그리고 분류한 객체를 표시하는 Bounding Box Regression 구조로 RCNN 모델과 동일하다.
그럼 SPP는 뭘까?
Spatial Pyramid Pooling
SPP는 특정 Pooling 과정을 통과하면 사이즈가 다른 Region Proposal들을 고정된 사이즈의 벡터들로 변환시키는 과정이다.


위에서 보는 것처럼 SPP를 적용하게 되면 이미지를 자르거나 찌그러뜨리는 단계가 없다. 단, SPP는 Convolution이 적용되는 CNN Model을 거치고 난 후 적용된다. 왜냐하면 SPP를 이용해서 동일한 크기 사이즈의 벡터로 결합을 하고 Flatten 시켜 FC Layer를 만들어야 하기 때문이다.
Spatial Pyramid Matching
SPP는 원래 SPM(Spatial Pyramid Matching)에 기반을 둔 방법이다. 따라서 SPP를 이해하기 전에 SPM을 먼저 이해해야 한다. SPM은 마치 NLP(자연어 처리) 분야에서 Bag of Words와 비슷하다.
Bag of Words란, 특정 문서에서 단어의 빈도수에 기반해 만든 벡터를 의미한다. 예를 들어, "강아지는 동물이다. 강아지는 사람을 잘 따르고 가끔은 인간보다 똑똑한 것 같다. 그러나 강아지의 실제 IQ 지수는 그렇지 않다." 라는 문장이 있다고 가정하자. 이 문장에서 각 단어의 빈도수를 count 해보면 '강아지' 라는 단어가 가장 많을 것이다. 따라서 해당 문장은 '강아지' 라는 주제에 관한 문장임을 추측할 수 있다.
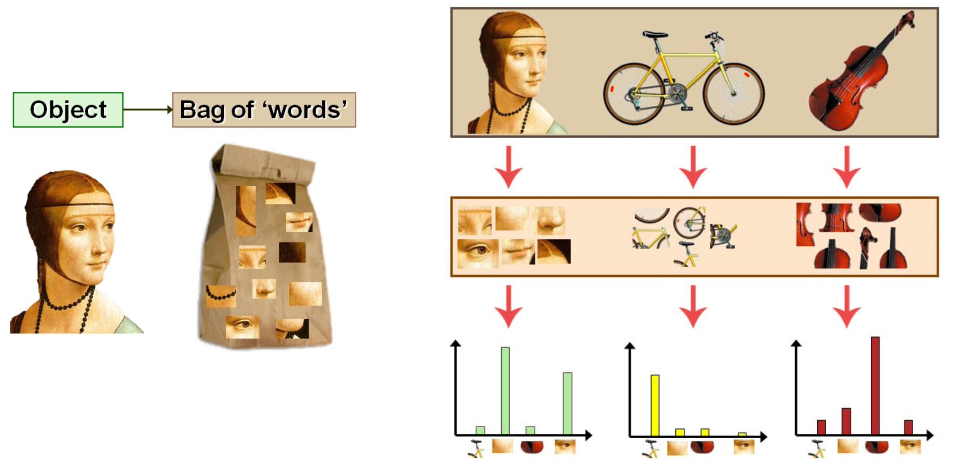
Bag of Words의 원리를 이미지 분야에 적용한 것이 Bag of Visual Words이다.
이미지의 Region 별로 여러개의 Feature들을 추출하고, 각 Feature 별로 이미지에서 나타나는 빈도수를 count하고, 히스토그램으로 표시한다. 그래서 "어떤 Feature들이 많이 나타나면 어떤 이미지일 것이다!" 라는 추론을 할 수 있다.
이처럼 Bag of Visual Words는 원본의 정보를 새로운 맵핑 정보로 변환하는 것이다. 여기서 맵핑 정보는 히스토그램이다.
비정형적인 데이터를 정형화된 피쳐 속성으로 만들되, 피쳐의 속성을 히스토그램으로 만드는 것이다.

그러나 Bag of Visual Words는 치명적인 단점이 있다. 바로 이미지의 위치적인 특성을 고려하지 못한다는 점이다. 예를 들어 위의 사막에서 나무에 대한 Feature들이 많이 나와서 이 이미지는 숲 일 것이다라고 판단해버릴 수 있는 것이다.
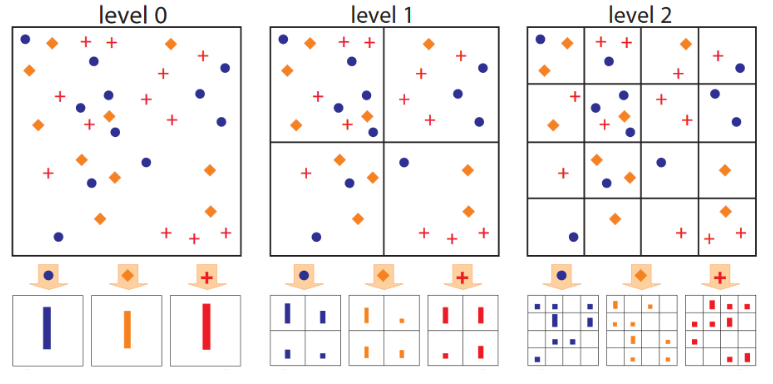
이러한 문제를 해결하기 위해서 이미지를 분할하여 분면을 나누는 방법을 이용한다. 나온 것이 바로 SPM이다.
위치 정보를 감안해서 픽셀값을 히스토그램으로 나타낸 것이다. 위의 그림처럼 원본 데이터를 다양한 히스토그램 정보로 변환할 수 있다.
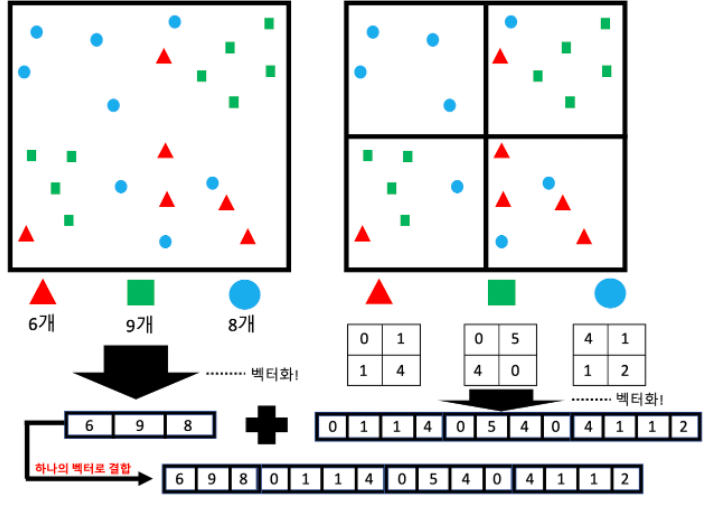
위와 같이 분면을 아예 하지 않았을 때, 4분면으로 나누었을 때 2번을 수행하여 SPM을 진행하고 이를 기반으로 Count한 벡터들을 하나로 결합한다. 위의 예시에서는 2번만 분할을 수행했지만 경우에 따라 8분면, 16분면 등 여러 번 분면을 수행해서 고정된 사이즈로 벡터를 결합할 수 있다.
그리고 계속해서 SPM으로 분면을 나누면, 서로 다른 크기의 피쳐맵을 균일한 크기의 벡터로 변환하고 하나의 벡터로 결합할 수 있다!
즉, Feature Map 또는 Region Proposal 사이즈가 서로 달라도 분면 나누는 개수, 횟수를 동일하게 설정만 한다면 결합한 벡터들의 사이즈는 동일하게 된다.

그렇다면 SPP는 무엇일까? 바로 위 그림에서 Count 벡터를 추출할 때 Max값만 Pooling 해서 벡터를 결합하는 것이다.
이렇게 모든 피쳐맵을 동일한 사이즈의 벡터로 만들고, Dense Layer로 넘겨주면서 최종 클래스를 분류하고, 동시에 Bounding Box 회귀를 수행한다.
Ref : 앎의 공간
딥러닝 컴퓨터비전 완벽가이드
'🖼 Computer Vision > Object Detection' 카테고리의 다른 글
| CV - Faster RCNN (2) | 2022.04.29 |
|---|---|
| CV - Fast RCNN (0) | 2022.04.28 |
| CV - RCNN (Region with CNN features) (0) | 2022.04.28 |
| CV - Object Detection Architecture (0) | 2022.04.28 |
| CV - OpenCV (0) | 2022.04.23 |