
📌 이 글은 권철민님의 딥러닝 CNN 완벽 가이드를 바탕으로 정리한 내용입니다.
목차
- Loss function(손실함수) : 네트웍 모델이 얼마나 학습데이터에 잘 맞고 있는지, 학습을 잘하고 있는지에 대한 길잡이
- Loss function의 역할
- Regression의 Loss function : MSE
- Classification의 Loss function : Cross Entropy Loss
- Cross Entropy Loss는 무엇인가?
- Cross Entropy Loss는 어떻게 구하는가?
- Cross Entropy Loss의 특성
Loss function (손실함수)
손실함수 = 비용함수 = 목적함수
Loss function = Cost function = Object function
다 똑같은 함수다.
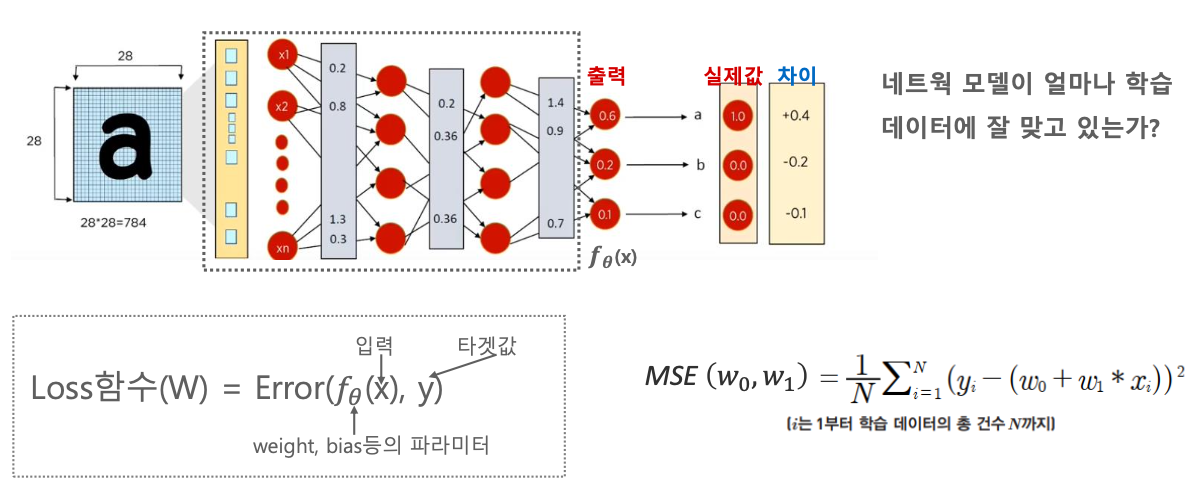
모델이 더 좋은 모델로 가기 위해서 네트웍 모델이 얼마나 학습 데이터에 잘 맞고 있는지, 학습을 잘 하고 있는지에 대한 길잡이가 있어야 한다. 그리고 그 길잡이에 기반해서 Gradient도 적용을 해야 된다. 그 길잡이가 Loss function이다.
잠깐 복습해보자.
위 그림의 오른쪽에 나와 있는 MSE는 주로 Regression에서 많이 쓰이는데, 실제값과 예측값의 차이를 빼서 제곱을 한다.
N은 학습데이터의 총 건수이다.
그러면 데이터 건수가 높은건 무조건 Loss가 높나?
그렇게 하지 않기 위해서 N으로 나눠서 평균으로 계산하게 된다. 그래서 Mean이다.
또 0보다 작은 값이 있을 수 있으므로 제곱(square)를 하게 된다.
Loss function의 역할
Loss function은 학습 과정이 올바르게 이뤄질 수 있도록 적절한 가이드를 제공할 수 있어야 한다.
우리가 만들고자 하는 모델에 맞춰서 Loss function이 만들어져야 한다.
대표적으로 Regression은 주로 MSE(Mean Squared Error),
Classification은 주로 Cross Entropy(binary, categorical)를 이용한다.
Regression의 Loss function : MSE
MSE는 (실제값 - 오류값)^2 해서 더한 뒤 데이터 개수로 나누는 방식이다.


이 Loss function에 기반해서 Gradient 값을 구한다.
Classification의 Loss function : Cross Entropy Loss

예측값과 실제값을 가지고 Cross Entropy Loss 라는 것을 계산한다.
Cross Entropy Loss에 기반해서 Gradient를 계산한 다음, Backpropagation을 통해 업데이트를 한다.
Cross Entropy Loss 란

yi = 실제값
yi^ = 예측값
m = 데이터의 건수
보통의 식은 이렇게 나타낸다.
데이터 하나의 Cross Entropy는 어떻게 구하나

Output layer에 값이 들어오면 Softmax로 Activation 시킨다.
그러면 Probability 값으로 딱 떨어진다.
그러면 이 데이터는 위에서 보다시피 두번째 클래스 일 것이라고 예측을 하게 된다.
이렇게 Softmax는 One-hot 타겟 값으로 들어오게 된다.
한 건의 데이터에 대해서 다섯개의 클래스 중 하나의 클래스를 예측할 때 이렇게 예측된다.

yi = 실제값
yi^ = 예측값
여기서 i는 데이터의 건수가 아니라 클래스의 유형의 건수이다.
위에서 본 클래스의 유형은 5개이므로 C=5 가 된다.

그래서 log 씌우고 더하고, log 씌우고 더하고 하면
-{log(0.02*0 ) + log(0.90*1) + log(0.05*0) + log(0.01*0) + log(0.02*0)} = -log(0.90) = 0.105
가 되는 것이다.
Cross Entropy Loss의 특성

실제 클래스에 해당되는 Softmax의 결과 값에만 Loss를 부여한다.
그 값이 1에 가까워질수록 Loss는 0에 가까워진다.
반대로 잘못된 예측 결과에는 높은 Loss가 부여된다.
'🖼 Computer Vision > CNN' 카테고리의 다른 글
| CNN - Optimizer (0) | 2022.01.20 |
|---|---|
| CNN - Cross Entropy (0) | 2022.01.20 |
| CNN - Activation function (활성화 함수) (0) | 2022.01.20 |
| CNN - Backpropagation의 Gradient 적용 메커니즘 (0) | 2022.01.19 |
| CNN - Backpropagation (0) | 2022.01.19 |