
📌 이 글은 권철민님의 딥러닝 CNN 완벽 가이드를 바탕으로 정리한 내용입니다.
목차
- 전처리
- 학습 데이터, 테스트 데이터 분리
- scaling 및 형 변환
- 원핫 인코딩
- 학습, 검증 데이터 분리
- 학습, 검증, 테스트 데이터 셋 생성
- 모델링
- 모델 생성
- 모델 학습
- 모델 성능 평가
전처리
from tensorflow.keras.datasets import fashion_mnist
import numpy as np
from tensorflow.keras.utils import to_categorical
from sklearn.model_selection import train_test_split학습 데이터, 테스트 데이터 분리
# 전체 6만개 데이터 중, 5만개는 학습 데이터용, 1만개는 테스트 데이터용으로 분리
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()scaling 및 형 변환
def get_preprocessed_data(images, labels):
# 학습과 테스트 이미지 array를 0~1 사이값으로 scale 및 float32 형 변형.
images = np.array(images/255.0, dtype=np.float32)
labels = np.array(labels, dtype=np.float32)
return images, labels원핫 인코딩
# 0 ~ 1사이값 float32로 변경하는 함수 호출 한 뒤 OHE 적용
def get_preprocessed_ohe(images, labels):
images, labels = get_preprocessed_data(images, labels)
# OHE 적용
oh_labels = to_categorical(labels)
return images, oh_labels학습, 검증 데이터 분리
# 학습/검증/테스트 데이터 세트에 전처리 및 OHE 적용한 뒤 반환
def get_train_valid_test_set(train_images, train_labels, test_images, test_labels, valid_size=0.15, random_state=2021):
# 학습 및 테스트 데이터 세트를 0 ~ 1사이값 float32로 변경 및 OHE 적용.
train_images, train_oh_labels = get_preprocessed_ohe(train_images, train_labels)
test_images, test_oh_labels = get_preprocessed_ohe(test_images, test_labels)
# 학습 데이터를 검증 데이터 세트로 다시 분리
tr_images, val_images, tr_oh_labels, val_oh_labels = train_test_split(train_images, train_oh_labels, test_size=valid_size, random_state=random_state)
return (tr_images, tr_oh_labels), (val_images, val_oh_labels), (test_images, test_oh_labels )학습, 검증, 테스트 데이터 셋 생성
# Fashion MNIST 데이터 재 로딩 및 전처리 적용하여 학습/검증/데이터 세트 생성.
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
print(train_images.shape, train_labels.shape, test_images.shape, test_labels.shape)
(tr_images, tr_oh_labels), (val_images, val_oh_labels), (test_images, test_oh_labels) = \
get_train_valid_test_set(train_images, train_labels, test_images, test_labels, valid_size=0.15, random_state=2021)
print(tr_images.shape, tr_oh_labels.shape, val_images.shape, val_oh_labels.shape, test_images.shape, test_labels.shape)
학습데이터 60000개를 쪼개서 학습(51000), 검증(90000) 데이터로 다시 나눈다.
모델링
모델 생성
from tensorflow.keras.layers import Dense, Flatten
input_tensor = Input(shape=(28, 28, 1))
x = Conv2D(filters=32, kernel_size=3, strides=1, padding='same', activation='relu')(input_tensor)
x = Conv2D(filters=64, kernel_size=3, activation='relu')(x)
x = MaxPooling2D(2)(x)
# 3차원으로 되어있는 Feature map 결과를 Fully Connected 연결하기 위해서는 Flatten()을 적용해야함.
x = Flatten()(x)
x = Dense(100, activation='relu')(x)
output = Dense(10, activation='softmax')(x)
model = Model(inputs=input_tensor, outputs=output)
model.summary()
flatten을 해버리고 나서 파라미터가 100만개나 생긴다.
학습을 하면 이 과정에서 오버피팅이 생기기 쉽다.
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.losses import CategoricalCrossentropy
from tensorflow.keras.metrics import Accuracy
model.compile(optimizer=Adam(0.001), loss='categorical_crossentropy', metrics=['accuracy'])
optimizer는 Adam을 사용하고,
원핫인코딩을 적용 했으니까, 반드시 loss function은 categorical crossentropy를 이용해준다.
모델 학습
history = model.fit(x=tr_images, y=tr_oh_labels, batch_size=128, epochs=30, validation_data=(val_images, val_oh_labels))그리고 학습을 진행 해준다.

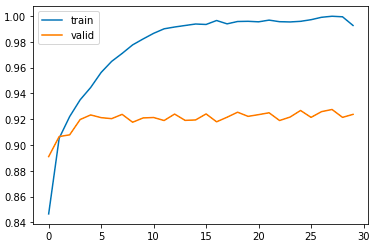
학습데이터 정확도가 99정도가 되면 더이상 올라갈 곳이 없다.
거의 뒤로 가도 validation 쪽에서는 성능 향상을 기대하기가 어렵다.
모델 성능 평가
import matplotlib.pyplot as plt
%matplotlib inline
def show_history(history):
plt.plot(history.history['accuracy'], label='train')
plt.plot(history.history['val_accuracy'], label='valid')
plt.legend()
show_history(history)
# 테스트 데이터 세트로 모델 성능 검증
model.evaluate(test_images, test_oh_labels, batch_size=256, verbose=1)
92% 정도 나오는 것을 확인할 수 있다.
위에서 확인 했듯이 Flatten을 하게 되면 파라미터 수가 굉장히 많아지고, 이로 인해 오버피팅이 발생할 수 있으므로, Dropout을 적용한다.
Dropout
Fully Connected Layer의 너무 촘촘한 연결로 인한 많은 파라미터(weight) 생성은 오히려 오버 피팅을 가져 올 수 있음.
Dropout을 통해 Layer간 연결을 줄일 수 있으며 오버 피팅 개선을 가져 올 수 있음.

from tensorflow.keras.layers import Dense, Flatten, Dropout
input_tensor = Input(shape=(28, 28, 1))
x = Conv2D(filters=32, kernel_size=3, strides=1, padding='same', activation='relu')(input_tensor)
x = Conv2D(filters=64, kernel_size=3, activation='relu')(x)
x = MaxPooling2D(2)(x)
x = Flatten()(x)
x = Dropout(rate=0.5)(x)
x = Dense(100, activation='relu')(x)
output = Dense(10, activation='softmax')(x)
model = Model(inputs=input_tensor, outputs=output)
model.summary()
validation 정확도가 93%로 조금 향상된 것을 확인할 수 있다.
show_history(history)
model.evaluate(test_images, test_oh_labels, batch_size=256, verbose=1)

엄청 높아지진 않았지만 조금 높아진 것을 확인할 수 있다.
좀더 적극적으로 Dropout 해보자
from tensorflow.keras.layers import Dense, Flatten, Dropout, GlobalAveragePooling2D
def create_model():
input_tensor = Input(shape=(28, 28, 1))
x = Conv2D(filters=32, kernel_size=3, strides=1, padding='same', activation='relu')(input_tensor)
x = Conv2D(filters=64, kernel_size=3, activation='relu')(x)
x = MaxPooling2D(2)(x)
x = Dropout(rate=0.5)(x)
x = Flatten()(x)
x = Dropout(rate=0.5)(x)
x = Dense(200, activation='relu')(x)
x = Dropout(rate=0.2)(x)
output = Dense(10, activation='softmax')(x)
model = Model(inputs=input_tensor, outputs=output)
model.summary()
return model
model = create_model()
model.compile(optimizer=Adam(0.001), loss='categorical_crossentropy', metrics=['accuracy'])
history = model.fit(x=tr_images, y=tr_oh_labels, batch_size=128, epochs=30, validation_data=(val_images, val_oh_labels))show_history(history)
model.evaluate(test_images, test_oh_labels, batch_size=256, verbose=1)
좀더 성능이 좋아진 것을 확인할 수 있다.
'🖼 Computer Vision > CNN' 카테고리의 다른 글
| CNN - Convolution 연산 후 Feature map 크기 계산 이해하기 (0) | 2022.03.02 |
|---|---|
| CNN - Convolution 연산에서 Filter에 대한 이해 (3) | 2022.03.02 |
| CNN - Conv2D 와 Pooling 적용 실습 (0) | 2022.02.18 |
| CNN - Stride, Padding, Pooling (0) | 2022.02.15 |
| CNN - Kernel & Feature map (0) | 2022.02.15 |