
📌 이 글은 권철민님의 딥러닝 CNN 완벽 가이드를 바탕으로 정리한 내용입니다.
목차
- Stride : Sliding window가 이동하는 간격
- Padding : 모서리에 0값을 채워 원본 Feature Map의 크기를 유지시키는 방법
- Pooling : Feature Map의 일정 영역별로 하나의 값을 추출하여 Feature Map의 크기를 줄이는 방법
- Stride와 Pooling의 비교
Stride
stride는 입력 데이터(원본 image 또는 입력 feature map)에 Conv Filter를 적용할 때 Sliding Window가 이동하는 간격을 의미한다.


- stride는 입력 데이터(원본 image또는 입력 feature map)에 Conv Filter를 적용할 때 Sliding Window가 이동하는 간격을 의미
- 기본은 1이지만, 2를(2 pixel 단위로 Sliding window 이동) 적용하여 입력 feature map 대비 출력 feature map의 크기를 대략 절반으로 줄일 수 있다.
- stride를 키우면 공간적인 feature 특성을 손실할 가능성이 높아지지만, 이것이 중요 feature들의 손실을 반드시 의미하지는 않는다.
오히려 불필요한 특성을 제거하는 효과를 가져 올 수 있다. 또한 Convolution 연산 속도를 향상 시킬 수 있다.
Padding

- Filter를 적용하여 Conv 연산 수행 시 출력 Feature Map이 입력 Feature Map 대비 계속적으로 작아지는 것을 막기 위해 적용한다.
- Filter 적용 전, 보존하려는 Feature Map 크기에 맞게, 입력 Feature Map의 좌우 끝과 상하 끝에 각각 열과 행을 추가한 뒤, 0값을 채워, 입력 Feature map 사이즈를 증가시킨다.
- 위의 4x4 Feature Map에 2x2 Filter를 적용 시, 출력 Feature map은 3x3이 된다.
- 입력 Feature map과 출력 Feature map의 크기를 맞추기 위해 좌우 끝과 상하 끝에 0값을 채워서, 6x6 Feature map으로 변경한다.
- 그리고 2x2 filter를 적용하여 Padding 적용 전 원본 feature map 크기와 동일한 4x4 Feature Map을 출력한다.
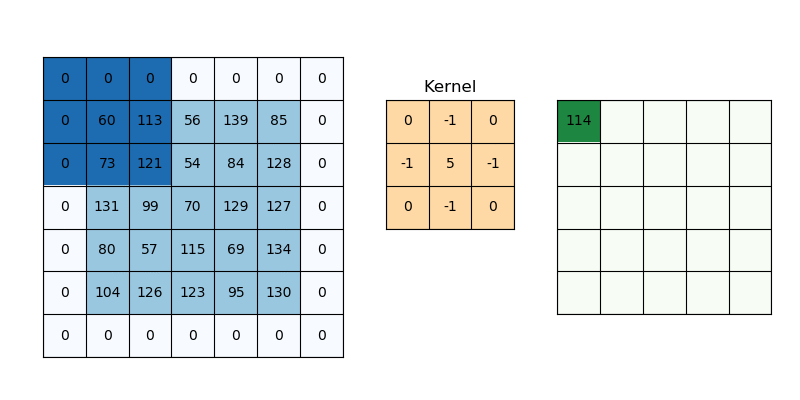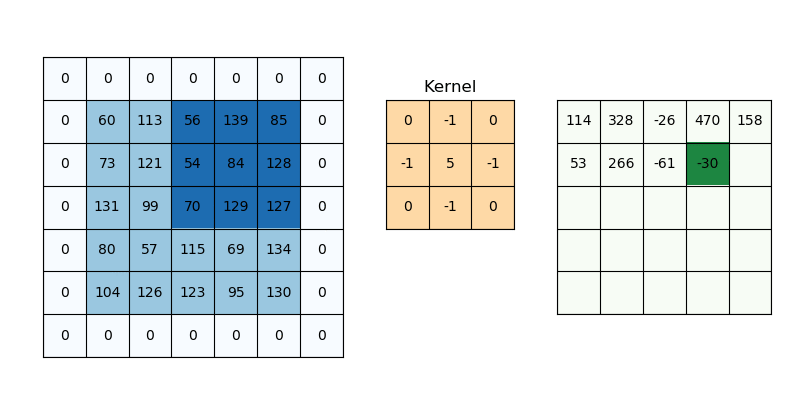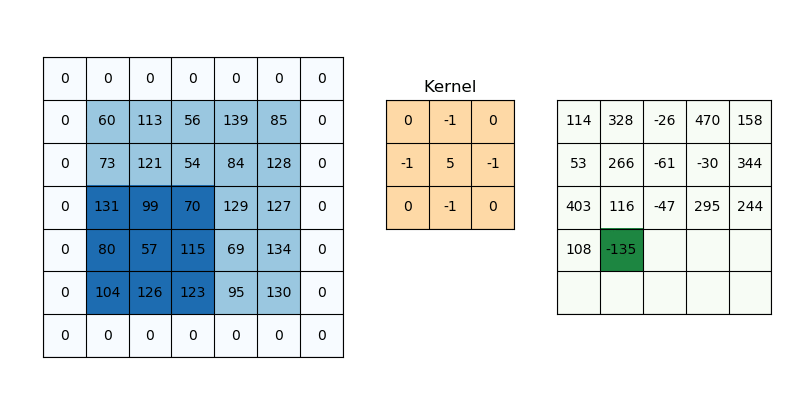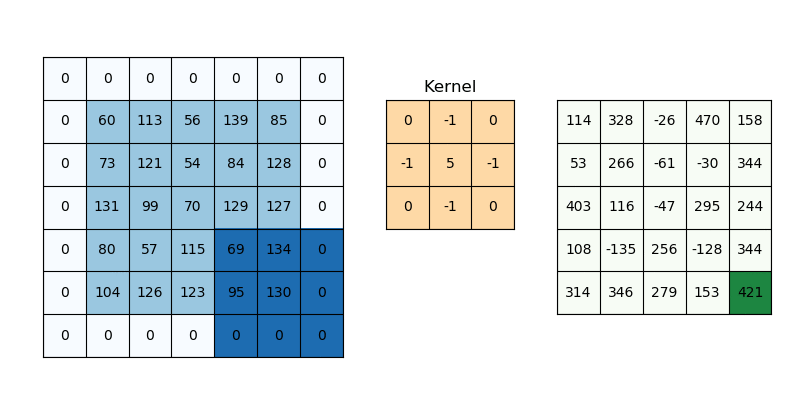

- CNN Network 이 깊어질수록(Conv 적용을 많이 할 수록) Feature Map 크기가 줄어드는 현상을 막을 수 있다.
- 모서리 주변(좌상단, 우상단, 좌하단, 우하단)의 Conv 연산 횟수가 증가되어 모서리 주변 feature들의 특징을 보다 강화하는 장점이 있다.
- Zero Padding의 영향으로 모서리 주변에 0값이 입력되어 Noise가 약간 증가되는 우려도 있지만 큰 영향은 없다.
- Keras에서 Conv2D() 인자로 padding=‘same’을 넣어주면, Conv 연산 시 자동으로 입력 feature map의 크기를 출력 feature map에서 유지할 수 있게 padding 면적을 계산하여 적용한다.
- padding=‘valid’를 적용하면 별도의 padding을 적용하지 않고, Conv 연산을 수행한다.
Pooling

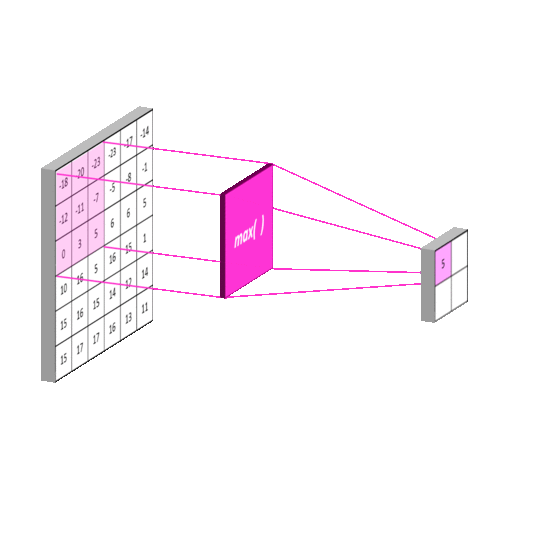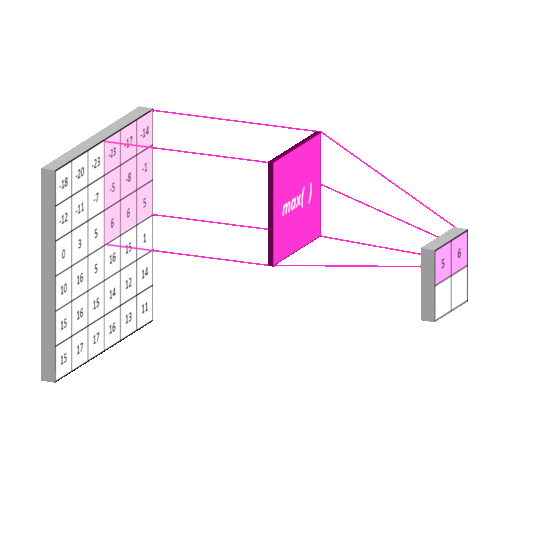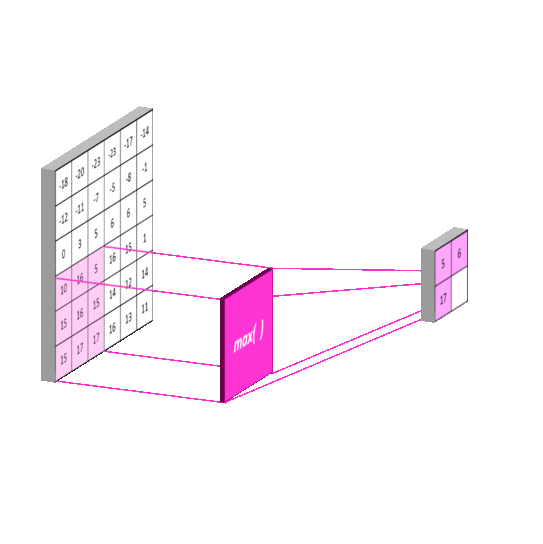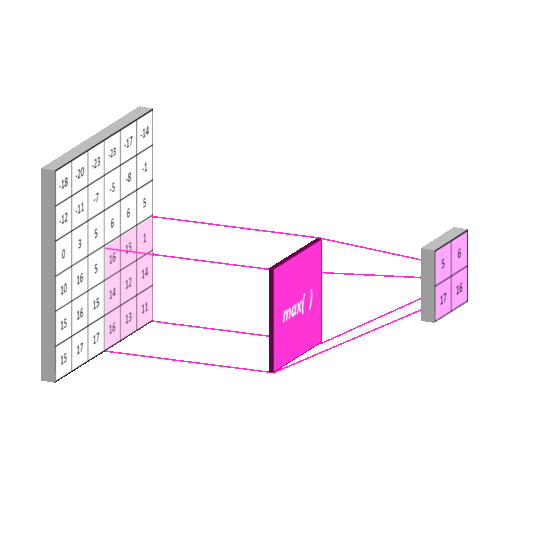
- Conv 적용된 Feature map의 일정 영역 별로 하나의 값을 추출하여(주로 Max 또는 Average 적용), Feature map의 사이즈를 줄인다(sub sampling).
- 일반적으로 Pool 사이즈와 Stride 값을 같게 한다.
- 일정 영역에서 가장 큰 값 또는 평균값을 추출하므로 위치의 변화에 따른 feature 값의 변화를 일정 수준 중화시킬 수 있다.
- 일반적으로 Max Pooling을 많이 쓴다(가장 큰 값이 피쳐를 나타낸다).
- 보통은 Conv->ReLU activation 적용 후 Activation Map에 Pooling 적용.
- Pooling 은 비슷한 feature 들이 서로 다른 이미지에서 위치가 달라지면서 다르게 해석되는 현상을 중화시켜 준다.
- Feature Map의 크기를 줄이므로 Computation 연산 성능이 향상된다. (Conv 적용 보다 computation이 더 간단)
- Max Pooling의 경우 보다 Sharp한 feature 값을(Edge등) 추출하고 Average Pooling의 경우 보다 Smooth한 feature값을 추출
- 일반적으로는 Sharp한 feature가 보다 Classification에 유리하여 Max Pooling이 더 많이 사용된다.
Stride와 Pooling의 비교
Stride는 Convolution 연산을 할 때 함께 적용된다. (한칸씩 이동할 건지, 두칸씩 이동할 건지)
Pooling은 일단 Convolution 연산을 한 후 Feature Map이 나온 것을 다시 줄이는 것이다. (평균 값으로 줄이든, 가장 큰값으로 줄이든)
결국 둘다 Feature Map의 크기를 줄이는데 사용이 된다.
근데 보통 Pooling을 잘 안쓴다. Stride로 Feature Map 크기를 줄이는 것이 Pooling 보다 더 나은 성능을 보인다는 연구 결과 때문.
'🖼 Computer Vision > CNN' 카테고리의 다른 글
| CNN - Fashion MNIST 예측 모델 구현하기 (0) | 2022.03.02 |
|---|---|
| CNN - Conv2D 와 Pooling 적용 실습 (0) | 2022.02.18 |
| CNN - Kernel & Feature map (0) | 2022.02.15 |
| CNN - Convolution 연산의 이해 (0) | 2022.02.15 |
| CNN - Callback (0) | 2022.02.14 |