Fashion_mnist 데이터를 분류하는 예측 모델을 구현해보자.
목차
- Fashion MNIST data 가져오기
- Fashion MNIST image 시각화
- 데이터 전처리 수행
- Dense Layer를 기반으로 모델 생성
- 모델의 Loss와 Optimizer 설정 및 학습
- 테스트 데이터를 기반으로 Label 값 예측
Fashion MNIST data 가져오기
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
from tensorflow.keras.datasets import fashion_mnist
# 전체 6만개 데이터 중, 5만개는 학습 데이터용, 1만개는 테스트 데이터용으로 분리
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
# image size는 28x28의 grayscale 2차원 데이터
print("train dataset shape:", train_images.shape, train_labels.shape)
print("test dataset shape:", test_images.shape, test_labels.shape)
위와 같이 데이터 구조를 항상 파악하고 가야한다.
아 학습 데이터 셋은 3차원 데이터이고 라벨은 1차원 데이터이구나!
MNIST image array 시각화
6만개의 데이터 중에 첫번째 이미지를 확인해보자.
import matplotlib.pyplot as plt
%matplotlib inline
# 6만개 중에 첫번째 이미지
plt.imshow(train_images[0], cmap='gray')
plt.title(train_labels[0])
# 3차원 행렬로 들어가 있는 것을 확인할 수 있다.
plt.imshow(train_images[0], cmap='gray')
print(train_images[0, :, :])
print("label =", train_labels[0])
# 맨끝에 레이블 9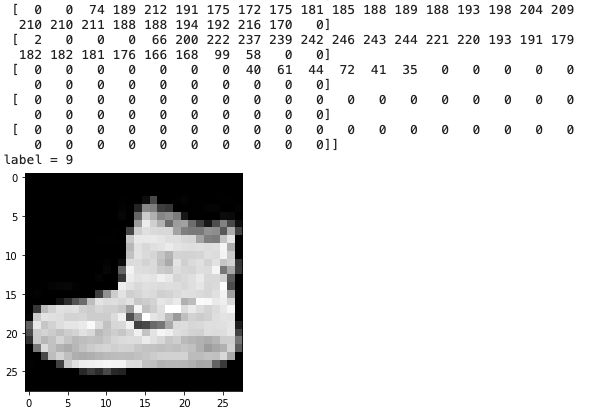
데이터를 확인해보면 이미지 데이터는 3차원 행렬로 들어가 있는 것을 확인할 수 있다.
또한 데이터의 라벨도 확인할 수 있다.
이미지를 8개씩 확인하는 show_images() 함수를 만들어보자.
import matplotlib.pyplot as plt
%matplotlib inline
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat','Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
def show_images(images, labels, ncols=8): # ncols = 8개의 subplot
figure, axs = plt.subplots(figsize=(22,6), nrows=1, ncols=ncols) #여러개의 그래프를 한번에 그리겠다.
for i in range(ncols):
axs[i].imshow(images[i], cmap='gray') # 1행에 위치
axs[i].set_title(class_names[labels[i]])
show_images(train_images[:8], train_labels[:8], ncols=8)
show_images(train_images[8:16], train_labels[8:16], ncols=8)
데이터 전처리 수행
- 0 ~ 255 사이의 픽셀값을 0 ~ 1 사이 값으로 변환 (Normalization)
- 큰 값보다는 0~1 사이 값이 성능이 훨씬 좋게 나오기 때문에
- array type은 float 32
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
def get_preprocessed_data(images, labels):
# 학습과 테스트 이미지 array를 0~1 사이값으로 scale 및 float32 형 변형.
images = np.array(images/255.0, dtype=np.float32) # 이미지는 그냥 255로 나눠버림, tensorflow의 기본 타입=float32
labels = np.array(labels, dtype=np.float32)
return images, labels
train_images, train_labels = get_preprocessed_data(train_images, train_labels)
test_images, test_labels = get_preprocessed_data(test_images, test_labels)
print("train dataset shape:", train_images.shape, train_labels.shape)
print("test dataset shape:", test_images.shape, test_labels.shape)
학습을 위해서 데이터 전처리를 해준다.
# 0~1 사이 값으로 바뀐 것 확인
train_images[0]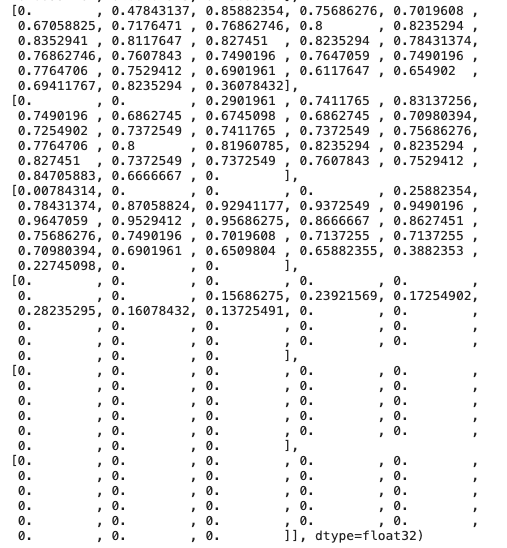
Dense Layer를 기반으로 모델을 생성
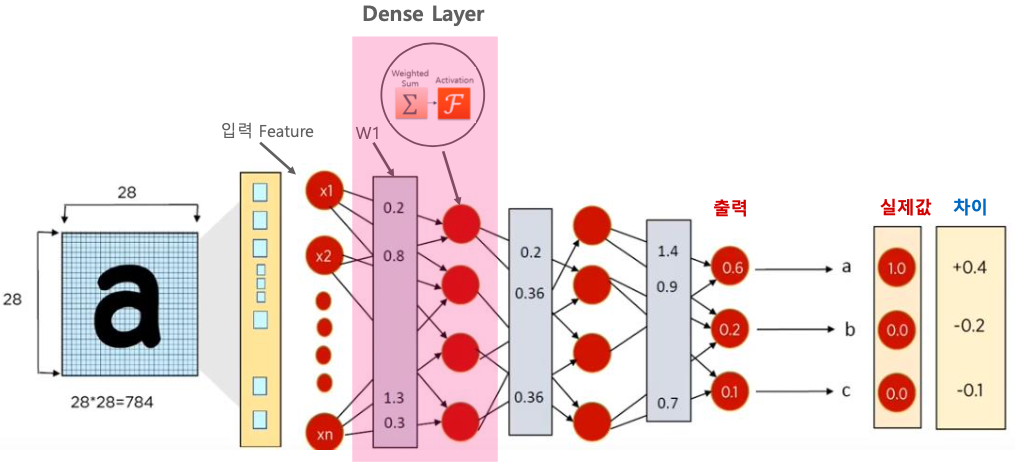
INPUT_SIZE = 2828 x 28 = 784
총 784개의 픽셀로 구성이 되어 있다.
dense는 1차원적인 입력 밖에 못 받아드린다. 그렇기 때문에 성능이 떨어지는 경향이 있다.
그러나 이미지가 가운데에 위치하고 있기 때문에 dense로도 어느 정도 성능이 나온다.
현재는 입력을 1차원으로 바꾸어 주어야 한다. 784개가 모두 피쳐가 되어야 한다.
그렇게 해주는 것이 바로 Flatten 이다.
첫번째 Dense의 output을 받아서 두번째 Dense의 input으로 넣는다.
마지막은 softmax로 바꾸어준다.
from tensorflow.keras.layers import Dense, Flatten # Dense : 입력, 히든 layer 만드는 것 / Flatten
from tensorflow.keras.models import Sequential # 모델
model = Sequential([
Flatten(input_shape=(INPUT_SIZE, INPUT_SIZE)), # 28x28 data를 뭉개버려라.784개가 만들어진다.784개가 모두 피쳐이다.
# Dense layer를 적용해주면 output까지 나온다. activation 함수를 설정해주면 weighted sum까지 나온다.
Dense(100, activation='relu'), # 첫번째 dense layer 100개, 활성함수는 ReLU, weight는 784*100 = 78400개 + bias 100개
Dense(30, activation='relu'), # 두번째 dense layer 30개, weight는 100 * 30 = 3000개 + bias 30개
Dense(10, activation='softmax') # 마지막 layer, weight는 30 * 10 = 300개 + bias 10개
])
model.summary()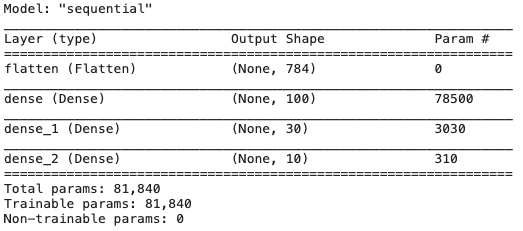
784개의 피쳐 하나당 dense layer 1번, 2번, .. 100번 까지 100개의 뉴런이 만들어지면 784x100 해서 78400개의 파라미터가 생긴다.
첫번째 dense layer에서 weighted sum하고 output1, output2 .. output 100까지 나온다.
bias도 100개에 연결돼서 100개의 output이 생기므로 총 78500개의 파라미터가 만들어진다.
여기서 Output Shape의 None은 batch이다.
아직 설정이 안되어 있으므로 None이다.
None으로 되어 있는 이유는 Batch에 맞추겠다 라는 뜻이다.
총 파라미터의 개수는 81840개가 나온다.
* sequential 모델 : sequential 하게 하나씩 하나씩 layer를 피드포워드로 만든다.
모델의 Loss와 Optimizer 설정하고 학습 수행
- loss는 categorical_crossentropy로, optimizer는 Adam으로 설정
- categorical crossentropy를 위해서 Lable을 OHE 로 변경
- categorical crossentropy는 반드시 타겟값이 원핫인코딩이 되어야 한다.
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.losses import CategoricalCrossentropy
from tensorflow.keras.metrics import Accuracy
model.compile(optimizer=Adam(0.001), loss='categorical_crossentropy', metrics=['accuracy'])
from tensorflow.keras.utils import to_categorical
# categorical ce는 반드시 원핫 인코딩되어야 한다.
train_oh_labels = to_categorical(train_labels) # 원핫레이블로 바꿔주기
test_oh_labels = to_categorical(test_labels)
print(train_oh_labels.shape, test_oh_labels.shape)
# 1차원이었던 레이블이 2차원으로 바뀌게 된다. (60000,) -> (60000, 10)>> (60000, 10) (10000, 10)
train_labels.shape>> (60000,)
보다시피 레이블은 1차원 데이터이다.
60000개의 이미지(3차원인 train_images (60000,28,28))를 flatten으로 뭉개버린다.
batch는 framework이 알아서 하므로 60000개를 모델 생성할 때 할 필요는 없다.
history = model.fit(x=train_images, y=train_oh_labels, batch_size=32, epochs=20, verbose=1)
# 60000 data / 32 batch size = 1875 data
# 1875개의 데이터를 20번 돌았다.
# 훈련 데이터만 성능이 좋아지고 있는 것을 확인할 수 있다. 훈련데이터만 죽어라 돌고있다.
print(history.history['loss']) # loss가 20번 iteration 할 때마다 감소되는 것 확인할 수 있다.
print()
print(history.history['accuracy']) # accuracy는 증가함
test data를 기반으로 Label 값 예측
- model.predict()를 이용하여 label값 예측
- predict()의 인자로 입력되는 feature array는 학습의 feature array와 shape가 동일해야함.
- fit() 시 3차원(28x28 2차원 array가 여러개 존재) array 입력 했으므로 predict()도 동일한 3차원 데이터 입력
- 특히 한건만 predict() 할때도 3차원 데이터여야 함. 이를 위해 expand_dims()로 2차원 image 배열을 3차원으로 변경
test_images.shape>> (10000, 28, 28)
테스트 데이터셋은 3차원으로 되어있다.
# test images를 학습된 모델로 예측해보자.
pred_proba = model.predict(test_images)
print(pred_proba.shape)>> (10000, 10)
10000개가 10개의 레이블로 구분이 된다.
pred_proba[0]
하나만 봐보면 10번 라벨이 가장 큰 확률을 보이는 것을 확인할 수 있다.
test_images[0].shape>> (28, 28)
모든 이미지를 다 보진 않기 때문에 한개의 이미지가 뭔지만 봐보자.
그런데 한개의 이미지는 2차원이기 때문에 오류가 날 수 있다.
print(np.expand_dims(test_images[0], axis=0).shape) # <<<<<< 이 형태로 넣어준다
print(np.expand_dims(test_images[0], axis=1).shape)
print(np.expand_dims(test_images[0], axis=2).shape)
print(np.expand_dims(test_images[0], axis=-1).shape)>>
(1, 28, 28)
(28, 1, 28)
(28, 28, 1)
(28, 28, 1)
우리가 모델을 학습할때, 그리고 예측할 때에도 데이터를 3차원으로 넣었다.
그렇기 때문에 하나의 데이터만 확인하고 싶을 때에도 3차원으로 만들어 준 다음 넣어야 한다.
pred_proba = model.predict(np.expand_dims(test_images[0], axis=0))
print('softmax output:', pred_proba)
pred = np.argmax(np.squeeze(pred_proba)) # 하나의 차원을 줄여준 다음
print('predicted class value:', pred)
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat','Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
print('target class value:', test_labels[0], 'predicted class value:', pred)
# 9번 레이블로 예측이 잘 된 것을 확인할 수 있다.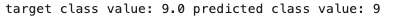
테스트 데이터 세트로 모델 성능 검증
# 테스트 데이터로 모델 성능을 검증해보자. (Evaluation)
model.evaluate(test_images, test_oh_labels, batch_size=64)
'🖼 Computer Vision > CNN' 카테고리의 다른 글
| CNN - Callback (0) | 2022.02.14 |
|---|---|
| CNN - Fashion_MNIST 분석 (0) | 2022.02.12 |
| CNN - Functional API (0) | 2022.01.21 |
| CNN - Image Array (0) | 2022.01.20 |
| CNN - Training Epoch, Batch Size, Learning Rate (0) | 2022.01.20 |