
- Proportional Share Scheduling
- Real-time Systems
- Real-time CPU Scheduling
- Rate Monotonic Scheduling
- Earliest Deadline First
- Multiple-Processor Scheduling
- Processor Affinity
- Load Balancing
- Multicore Processors
- Algorithm Evaluation


큐마다 다른 비율로 각각의 프로세스를 나눠서 쓰는 것

time quantum을 주고 프로세스를 나눠줌

Lottery scheduling : 프로세스마다 티켓을 나눠준 개수에 비례해서 프로세스를 나눠줌

실행이 완료되어야할 dead line이 있는 프로세스
Real-time system은 task 처리에 걸리는 시간을 일관되게 유지할 수 있냐가 중요한 성능의 척도이다.
Real-time system의 목표는 실시간 성능 보장에 있다.
* Soft real-time systems: task 처리 시간이 달라지면 성능이 감소하는 경우 (streaming video 등)
* Hard real-time systems: task 처리 시간이 달라지면 실패하는 경우 (자동차의 air-bag 등)


Real-time 시스템은 선점형이고 우선 순위 기반의 scheduling이 필요하다.
Soft real-time 시스템은 위에서 설명했듯이 최선을 다하지만 보장하지는 않는다.
Hard real-time 시스템은 task들이 scheduling이 충분히 되도록 반드시 보장해야 한다.
이를 위해 admission-control algorithm을 사용하며, 주기 안에 돌아갈 수 있는 process만 받는다.
또한, 일정 시간 내에 무조건 실행돼야 하는 것들을 위해 process 개수를 제한한다.
Hard real-time 시스템의 task는 반드시 규칙적인 주기에 따라 실행돼야 한다.
위 그림처럼 주기 p, CPU burst t, deadline d가 있을 때, t ≤ d ≤ p 이다.
Rate Monotonic Scheduling

수행주기가 가장 짧은 프로세스에 우선순위 부여
부가 설명
Rate-Monotonic scheduling algorithm은 정적 우선순위의 선점형 알고리즘이다.
Rate가 가장 높은 것부터 스케줄링 하고 필요하다면 preemption 하겠다. Rate = 1 / Period
우선순위는 주기에 반비례하게 할당되며, 짧은 주기의 작업이 높은 우선순위를 받게 된다.

예를 들어, 두 개의 process P1, P2가 있는데 주기가 각각 50, 100, CPU burst가 각각 20, 35, deadline은 주기와 같다고 하자.
만약 우선순위가 제대로 지켜지지 않아서 P2가 먼저 실행된다면, P1은 deadline 내에 작업을 끝내지 못할 것이다.

반대로, P1이 높은 우선순위를 받으면, P1이 먼저 시작되고 P1이 작업을 마치면 P2가 시작된다.
P2는 35 중 30만 작업을 완료하지만 P1의 주기가 돌아와 선점된다. P1의 주기 = 50, P2의 주기 = 100
P1이 작업을 마치면 P2가 다시 시작되고, 나머지 작업 5를 마친다.

두 process는 75에 완료되고 다시 반복되기 전 25가 유휴상태가 된다.
이 알고리즘으로 scheduling 할 수 없는 process 집합은 다른 priority scheduler로도 scheduling 할 수 없다.
따라서 정적 우선순위를 사용하는 알고리즘 중에서 Rate-Monotonic Scheduling이 가장 적합한 것으로 여겨진다.
정적 우선순위로 schedule 할 수 없는 process 집합을 살펴보자. 예를 들어, 두 개의 process P1, P2는 주기가 각각 50, 80, CPU burst가 각각 25, 35, deadline은 주기와 같다고 하자. 아래 그림 7처럼 P1이 먼저 실행되어 25에 작업을 완료하고 P2가 시작되어 25만큼 하고 P1에 선점된다. 다시 P1이 75에 작업을 마치고 P2가 시작되어 나머지 작업 10을 하려하지만, P2의 주기인 80을 넘어 deadline을 놓쳤다.

P1 = 50초마다 도착, 처리하는데 20초
P2 = 100초마다 도착, 처리하는데 35초
처음엔 동시에 도착한다.
이때 Rate가 높은 애부터 스케줄링된다. 1/50 > 1/100.
P1이 P2보다 priority를 높게준다.
20초 동안 P1 돌린다.
35초 동안 P2 돌린다. 그런데 5초를 남겨놓고 P1이 도착한다.
preemption돼서 P2는 쫒겨나고 P1이 스케쥴링 된다.
그후 P2를 5초동안 돌리고 끝낸다.
100초가 되면 동일하게 돈다.

P1 = 50초마다 도착, 처리하는데 25초
P2 = 80초마다 도착, 처리하는데 35초
P1이 Rate가 높으니까 먼저 스케줄링 된다.
P2가 25초 처리되고 P1이 도착해서 preemption자리를 내준다.
P1을 처리하고 P2를 하려는데 또 P2가 와버렸다.
deadline을 못 맞췄다.

CPU가 있다. CPU가 있는데 전체 시간 중에 몇 퍼센트를 사용한다를 나타낼 수 있다.
CPU utilization = Process time / Period
어떤 각각 프로세스들 마다 utilization의 합을 구할 수 있겠다.
Example 1)
P1의 U = 20 / 50 = 40%
P2의 U = 35 / 100 = 35%
+= 75%
Example 2)
25 / 50 = 50%
35 / 80 = 43%
+= 93%
N = Process들의 갯수
CPU Utilization의 합 > N x (2^(1/N) - 1) 이면
RMS로는 스케줄링이 안되는 경우가 발생할 수 있다.
N = 2일 때 83% 이므로
Example 1은 스케줄링 되고 Example 2는 스케줄링 안 된다.
Earliest Deadline First

deadline이 가장 빨리 올 것부터 하겠다.
부가 설명
Earliest-Deadline-First(EDF) scheduling은 우선 순위를 동적으로 변경하여 deadline이 가장 빠른 process에게 가장 높은 우선순위를 부여한다. 아래 그림 8은 두 개의 process P1(50 / 25 / 50), P2(80 / 35 / 80)이 있을 때 EDF scheduling을 도시한 것이다.

50에서 P1이 들어왔음에도 P2의 deadline이 P1보다 빨라 선점되지 않는 것을 볼 수 있다. Rate-Monotonic scheduling과는 차이가 난다.
Rate-Monotonic scheduling보다 유휴시간이 적지만, ready queue에 process가 들어올 때마다 deadline을 확인해야 해서 overhead가 크다.


EDF 방법을 썼을 때 데드라인을 못 맞췄다면? 그건 CPU가 딸린 것이다. 니 능력이 딸린다는 뜻이다.


부가 설명
다중처리기 시스템의 CPU scheduling 방법에는
- asymmetric multiprocessing(ASMP),
- symmetric multiprocessing(SMP)
두 가지가 있다.
ASMP는 하나의 처리기가 모든 scheduling 결정과 kernel code의 실행을 담당하고, 나머지 처리기들은 사용자 코드만을 실행한다.
단지 하나의 처리기만 시스템 자료구조에 접근하므로, system data를 공유할 필요가 없어서 간단하다.
SMP는 각 처리기가 독자적으로 scheduling한다.
모든 process는 공동의(common) ready queue 또는 각 처리기의 ready queue에 있게 된다.
ready queue에 있는 프로세스들을 독자적으로 처리하는 것이라고 보면 된다.
거의 모든 현대 OS(Windows, Solaris, Linux, Mac OS X 등)들은 SMP를 지원한다.

Non Uniform Memory Access
메모리를 access 할텐데 (좌측)local memory에서 가져올 수 있고 (우측)remote memory에서 가져올 수 있다.
운영체제가 메모리를 떼서(할당해서) 준다.
가까운 곳에서 꺼내간다면 운영체제 입장에서 빨리빨리 줄 수 있다.
문제는 메모리가 좌측 메모리에 있는데 우측에 CPU를 할당해주면 메모리를 가져오는데 오래 걸린다.
그래서 프로세스를 새로 만들 때 어디다가 만들지 고려해서 돌리고 메모리 할당을 어디에다가 해줄지도 고려해야한다.

어디 노드에 프로세스를 줄지
리눅스에 taskset이라는 커맨드를 쓰면 affinity를 지정하는 것을 알 수 있다.
부가 설명
처리기들은 cache memory를 가질 수 있다. 처리기에 의해 가장 최근에 접근된 데이터가 그 처리기의 cache를 채우게 된다. 만약 process가 context switch를 하는데 다른 처리기로 옮겨간다면, 원래 처리기의 cache에 있던 내용은 무효화(invalidate) 되어야 하고, 새로운 처리기의 cache에 다시 채워야(reload) 한다. cache를 무효화하고 다시 채우는 작업은 비용이 크므로, 대부분의 SMP 시스템은 process를 같은 처리기에서 실행시키려고 한다. 이런 현상을 Processor Affinity라고 한다.
Soft Affinity는 process가 같은 처리기에서 처리되도록 하지만 보장은 되지 않는다. (이주할 수도 있다.) Linux같은 OS는 Hard Affinity를 지원하며, system call을 통해 process는 다른 처리기로 이주하지 않는다고 명시할 수 있다.
어떤 프로세스가 실행 중일 때, 그 프로세스를 수행하는 CPU의 cache에 프로세스 정보가 들어가는데,
만약 다음 스케줄링 때 다른 프로세스가 그 CPU를 할당 받게 되면, 새로운 프로세스의 정보가 cahce에 들어와야 한다.
이러한 오버헤드를 줄이기 위해서 affinity라는 기법을 사용한다.
soft affinity : affinity를 100% 보장하지 않는 스케줄링
hard affinity : 철저하게 affinity를 보장하는 스케줄링

부하 균등화 (Load Balancing)
SMP 시스템에서 CPU 효율량을 높이려면,
한 쪽 처리기에 프로세스가 몰려 있으면 안되고, 균등(balancing)하게 배분되어 있어야 한다.
이와 같이 부하 균등화는 모든 프로세서(처리기) 사이에 부하를 고르게 걸리게 만든다.
프로세서 마다 각자의 Ready queue를 가지고 있을 때 필요한 기법이다.
push migration : 특정 task가 처리기들의 부하를 체크하고 여유있는 처리기에 프로세스를 push한다. (수동적)
pull migration : 처리기 스스로 자기가 여유 있으면 프로세스를 pull 한다. (능동적)

부가 설명
- Core : CPU안에서 기초적인 연산을 처리하고 담당하는 부분을 말한다. 사람의 뇌로 생각을 하면 대뇌와 비슷하다.
- Multi Core : 하나의 CPU안에 여러개의 코어를 구현해 놓은 아키텍처를 멀티코어라고 한다.
- Hyper-Threading : 인텔에서 개발한 기술로 하나의 코어에 논리적으로 두개 이상의 코어처럼 동작하도록 설계한 기술을 의미한다.

왼쪽 멀티코어 프로세서 (CPU 2개)가 멀티 프로세싱 방식으로 일을 수행하고,
오른쪽 멀티코어 프로세서 (CPU 2개)가 멀티 프로세싱 방식이 아닌 독릭접은 방식으로 일을 수행한다.
Mulicore Processor


프로세스를 레디큐에 넣을지 말지 결정하는 것
CPU에 job을 5개까지 넣을 것이다 : degree of multiprogramming = 5
Long-term 스케줄러 (Job scheduler)
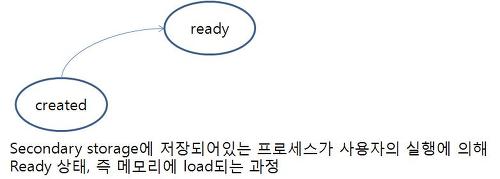
하드 디스크에서 메모리로 프로세스를 load하는 역할을 한다. 즉, 다음의 과정에서 long-term 스케줄러가 동작한다.
주로 디스크에 있는 프로세스들을 선택해서 실행을 위해 메모리로 load 함
(어떤 작업을 어떤 순서로 메모리에 가져와서 처리될 것인가를 결정하는 프로그램)
주어진 시간 안에 적은 수의 프로세스를 선택함 (드물게)
다중 프로그래밍 (multiprogramming)의 수준 (메모리에 있는 프로세스의 수)을 제어함
(CPU bound와 I/O bound 작업을 잘 혼합하여 선택해야 해서 신중하게)
Short-term 스케줄러 (CPU scheduler)
메모리에 있는 프로세스 중에서 프로세스가 CPU 점유권을 가질 때 어떤 프로세스가 선택되는지를 결정하는 스케줄러이다. 다음과 같은 과정에 동작한다.
MM의 실행할 준비가 되어있는 프로세스 중에 선택해서 CPU를 할당함
주어진 시간 안에 많은 수의 프로세스를 선택해야 함. 무척 빨라야 함.

Medium-term 스케줄러
asleep 상태에서 ready 상태로 넘어가지 못 하거나 ready 상태에서 running 상태로 넘어가지 못 하는 상황이 발생하면 어떤 일이 벌어질까? 결과적으로 실행되지도 않으면서 메모리만 차지하고 있는 비효율적인 상황이 발생한다. 이럴 경우 메모리에 load되어있는 running 상태로 넘어가지 않는 프로세스를 하드디스크로 쫓아낸다.(swap-out) 그리고 나중에 필요에 의해 다시 메모리로 들어올 수도 있다.(swap-in) 즉, 아래와 같은 과정이다. 이 과정을 midium-term 스케줄러가 한다.

출처: https://operatingsystems.tistory.com/entry/OS-스케쥴러-scheduler [Maybe]

multiprogramming degree를 낮춰주는 것

fore ground process
back ground process



총 4가지 방법으로 scheduling policy를 평가할 수 있다.
- Deterministic evaluation
- Queueing model
- Simulation
- Implementation

'🚦 Server > Operating System' 카테고리의 다른 글
| 14. Synchronization (1) (0) | 2020.05.18 |
|---|---|
| Process VS Processor (0) | 2020.05.17 |
| 12. Process Scheduling (3) (0) | 2020.05.07 |
| 11. Process Scheduling (2) (0) | 2020.05.05 |
| 10. Process Scheduling (1) (0) | 2020.04.29 |