딥러닝 용어
- Model
- Layer
- Convolution
- Weight / Filter / Kernel
- Pooling layer
- Activation Function
- SoftMax
- Cost / Loss / Loss Function
- Optimization
- Learning Rate
- Batch size
- Epoch
- Train set / Test set
- Label / Ground Truth
www.slideshare.net/KirillEremenko/deep-learning-az-convolutional-neural-networks-cnn-module-2r
이미지 출처
Deep Learning A-Z™: Convolutional Neural Networks (CNN) - Module 2
Deep Learning A-Z™: Convolutional Neural Networks (CNN) - Module 2
www.slideshare.net
CNN : talkingaboutme.tistory.com/entry/DL-Convolution의-정의


처음에는 퍼셉트론이라고 해서 몇 층만 쌓았다.
이 층을 여러층 쌓았다고 해서 딥러닝이라고 하는 것이다.
레이어를 하나하나 어떻게 쌓느냐에 따라서 모델이 결정된다.
층 수가 높으면 좋긴한데 너무 많이 쌓으면 느리거나 할 수 있다.
따라서 효율적으로 레이어를 쌓는 것이 좋다.

Convolution : 합성곱
이미지가 있으면 필터를 받아서 하나씩 곱해준다.
곱해주고 나면 테두리를 잡아서 필터가 된다.
이미지와 합성을 해서 어떠한 특징을 뽑아내는 것

Weight는 학습할려고 하는 대상이다.
필터는 Feature를 더 잘 뽑기 위해서 고정되지 않고 계산을 통해서 성능을 점점 더 높인다.
목적에 따른 Weight가 다르게 뽑힌다.
Convolution : 특징을 뽑는다
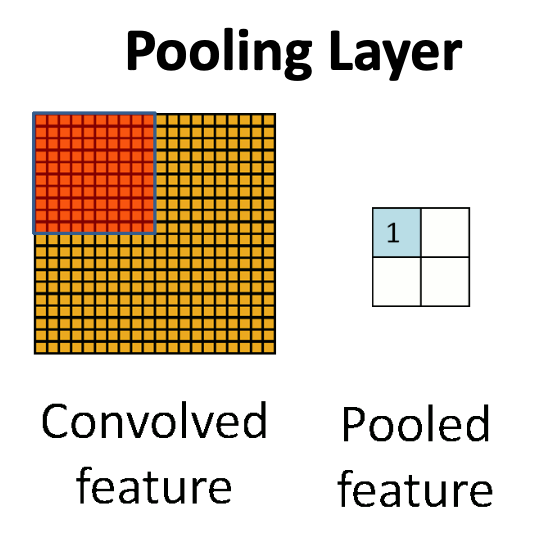
Pooling : 압축을 한다.

Convolution으로 특징을 뽑았으면 음수 값들을 제거해주어야 한다.
불필요한 값들을 줄인다.
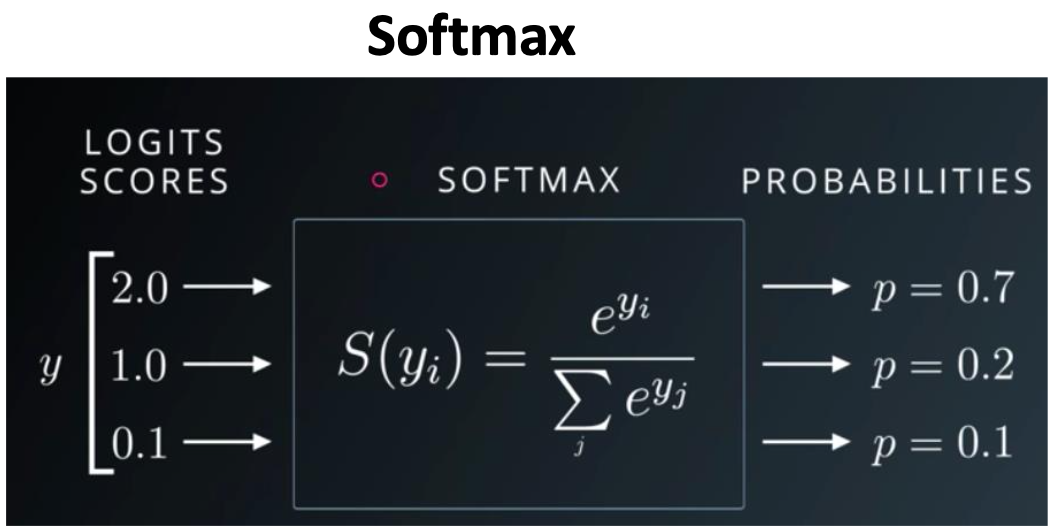
0,1,2 등의 모든 값들을 Softmax를 거친 후 합쳐서 1이 되게 만든다.
그럼 각 클래스 별로 몇 퍼센트인지 확률이 나온다.
즉 Softmax는 앞에서 나온 값들을 확률로 나타내어 준다.
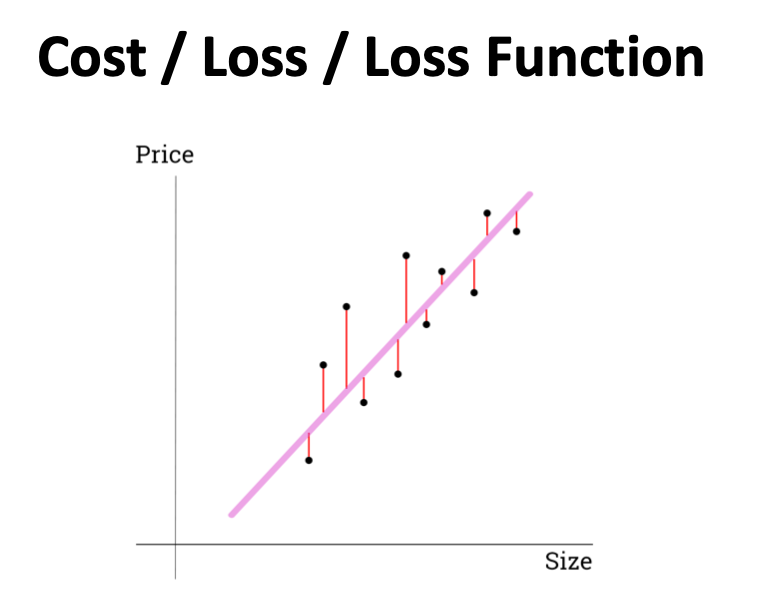
각각 예상했을 확률을 한번에 계산하여 얼마나 틀렸는지 확인한다.
그 방법이 Loss function이다.

얼마나 틀렸는지 봤으면 이 틀린 것들을 최소로 줄이고 싶다.
Optimization : 어떻게 하면 Model을 통한 예측이 Loss를 줄일 수 있을까?

Learning Rate가 너무 낮으면

모든 데이터를 한번에 다 넣을 수는 없다.
조금씩 나누어서 넣어준다.
그것을 정하는 것이 Batch size이다.

사람도 복습을 하는 것처럼 인공지능도 여러번 반복해야한다.
Epoch 수 만큼 반복한다.

데이터는 Train set과 Test set으로 나눈다.
학습할 때 Train set 평가할 때 Test set을 이용한다.

정답을 Label이나 Ground Truth라고도 한다.
대부분 딥러닝에는 정답이 있어야 한다.
데이터를 예측했을 때의 정답